
建议去看学长的笔记 Chap 2: Memory Hierarchy Design - NoughtQ的笔记本 ,以下内容是根据学长笔记做的, 方便我个人记忆
资料 百度网盘 请输入提取码
Chap1 Fundamentals of Quantitative Design and Analysis
能耗和功率
动态能耗(Energy_dynamic)
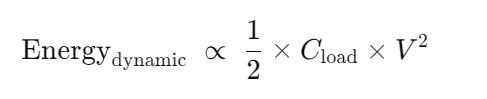
每发生一次从“0”→“1”或“1”→“0”的切换,就会消耗大约 1/2 × Cload × V2 的能量。
动态功率
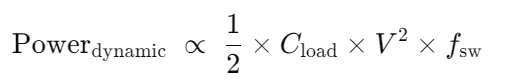
fsw:就是单位时间内开关的次数
静态功率(Static Power)
静态功率指的是晶体管即使没有开关动作(保持在“0”或“1”状态)时,仍然存在的漏电流(Leakage Current)所消耗的功率。
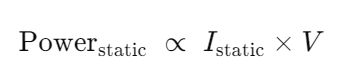
Cost of an Integreted Circuit
晶片成本
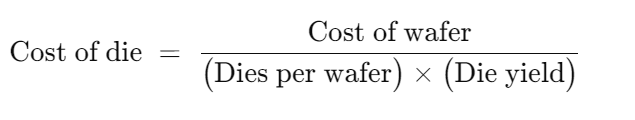
Die yield(裸片良率)指“经过晶圆级测试后判定合格的裸片比例”。
其中的Dies per wafer

S 指 die area ,每一个晶片大小
阿姆达尔定律
在执行时间 方面的表达

Chap 2: Memory Hierarchy Design
Memory Technologies
SRAM
特性:静态存储,无需刷新,速度快,但成本高、功耗大(待机功耗)。
应用:主要用于构建高速缓存(L1、L2、L3)。
DRAM
特性:动态存储,需要周期性刷新,成本低、密度高。
同步 DRAM(SDRAM):引入时钟信号,支持突发传输(burst transfer),允许在一次行激活后连续传输多个数据。
DDR(double data rate) SDRAM:在时钟的上升沿和下降沿都传输数据,有效倍增了数据传输速率。
闪存
非易失性,断电后数据不丢失
写入速度慢,需要先擦除再写入
写入次数有限(寿命问题,通过“磨损均衡”(wear leverage) 解决)。
N路 组相联 就代表 一路中有 N个块
Techniques for Higher Bandwidth (提高内存带宽的技术)
更宽的主存
将内存宽度 (内存总线宽度)加倍或四倍,可使内存带宽加倍或四倍。
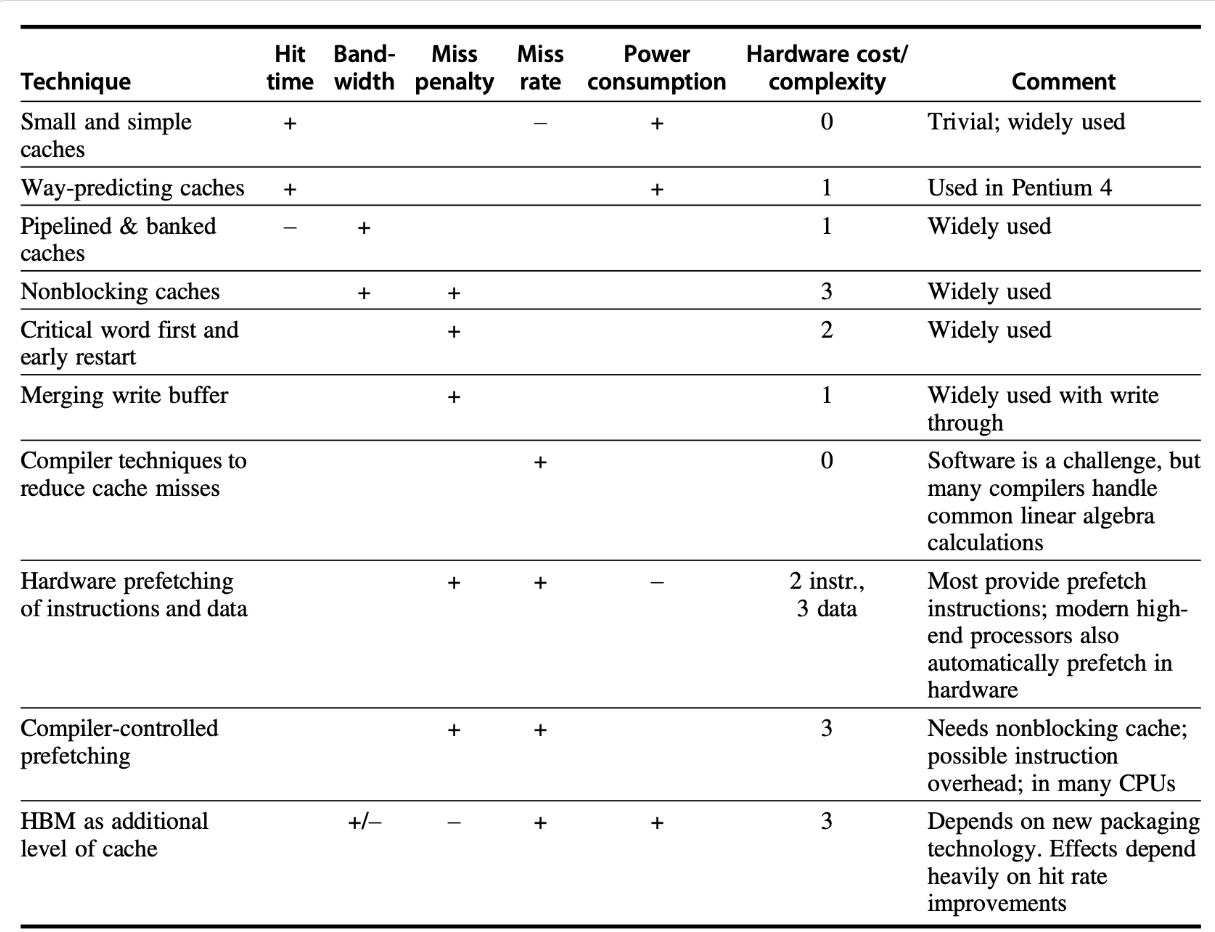
简单的交错内存
将内存组织成多个分区,可以同时读写多个字
问题:当数组大小或访问模式导致多个元素映射到同一个内存分区时,会发生分区冲突,导致 CPU 停顿。
软件(编译器)层面:
循环交换:改变嵌套循环的顺序,以避免访问同一个分区。
扩展数组大小:改变数组维度,使其不是 2 的幂次,从而强制地址映射到不同的分区。
硬件层面:使用质数数量的内存分区,有助于分散访问,减小冲突。
Write Strategy
写缺失的处理(地址 A 对应的缓存行不在 Cache 中 → 写缺失(Write Miss))
write back + write allocate
当发生写缺失时,找一个空闲行(如果空闲行上有脏数据就先写回主存),先把对应的整个缓存行(Cache Line)从主存(Memory)读取(load)到缓存中;然后再在缓存中对该缓存行进行写更新。
write through + write around (/no-write allocate)
发生写缺失时,直接写回主存(因为缓存中不会有脏数据需要处理)
在非缺失情况下,write through不仅要写回主存,也要写回内存,方便读
Cache
Performance
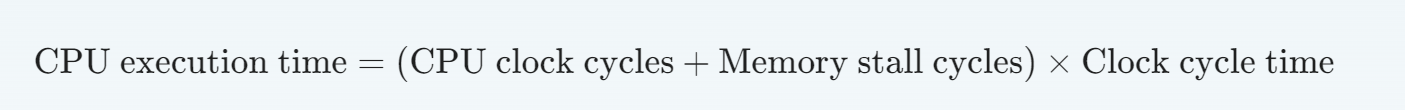
存储器停顿周期数
失效损失和失效率在读和写的情况下会有所不同, 如果这样的话下列公式仍得拆解



平均存储器访问时间(AMAT)

单位可以是绝对时间,也可以是周期数
只对那些需要memory的指令进行计算,加权分母为这些操作的个数 (包括取指,load store)
高速缓存的失效对于低 CPI 和高时钟频率的处理器 的影响 都较大
低CPI,那么miss暂停的clock一定下,miss的clock占比大
高频,在miss的暂停时间一定下,暂停的时钟周期更长
为了方便计算,Hit time 不用 ✖ (1- Miss rate)
Out-of-Order Execution Processors

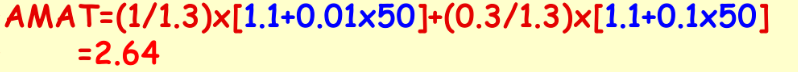
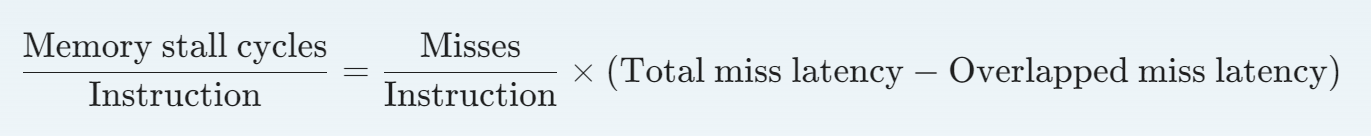
高速缓存优化方法(基于AMAT的三要素的优化)

失效分为: 强制、容量、冲突
1. Larger Block Size
降低失效率的最简单的方法是增大数据块的大小,它借助了空间局部性的优势,可以减少强制冲突的发生。
同时,更大的数据块还会提升失效损失,因为对于相同大小的高速缓存,数据块的数量会随之减少,从而导致冲突失效乃至容量失效的发生(当高速缓存较小时)。有时甚至还会出现失效损失的提升超过失效率的降低的情况,那么此时我们就不应该采取这种方法。
具体来说,数据块大小的选择需要同时考虑下级存储器的时延和带宽。
如果时延和带宽都很大的话,那么考虑使用更大的数据块,因为此时高速缓存在每次失效中可以得到更多的字节数据,而失效损失的提升相对较小
但如果时延和带宽都很小的话,则鼓励使用更小的数据块,因为更大的数据块只能节省很少的时间
2. Larger Caches
降低容量失效的一种方法是增大高速缓存的大小
但这样做的缺点是可能会带来更长的命中时间,以及消耗更高的成本和功率。
3. Higher Associativity
降低了失效率,但增加了命中时间;不建议在高频处理器上使用
4. Multilevel Caches
第一级高速缓存(以下简称 L1)可以足够小,以跟上处理器的时钟周期
第二级高速缓存(以下简称 L2)可以足够大,以捕获更多对内存的访问
AMAT 的 重新定义
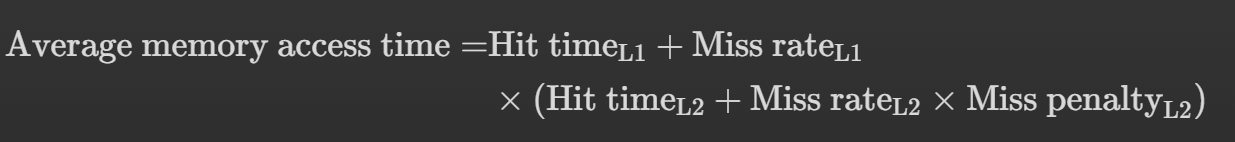
局部失效率和全局失效率

AMAT 强调的是每一次memory访问需要的时间,如果我们把目标放在“每一条指令的memory访问时间”,则有
当 L2 足够大时,全局失效率与 L2 的失效率非常相似
L1 内的数据是否需要出现在 L2 内?
多级包含(multilevel inclusion):L1 的数据永远都会在 L2 出现,这样可以确保数据的一致性
多级排斥(multilevel exclusion):L1 的数据永远不会在 L2 出现
当 L1 出现失效的情况时,交换 L1 和 L2 的数据,而非用 L2 的数据块替代 L1
5. Giving Priority to Read Misses over Writes

在写穿策略中,我们会利用写缓冲区(所以这和一般的写穿不一样)提升其性能 ; 上述第一条指令把 x3 的脏值写在 cache和写缓冲区内 , ld x1 将cache内的值擦除;而 ld x2 看到cache内没有自己想要的值,就会去主存读旧值,导致RAW
resolution: 当发生读失效时,检查写缓冲区的内容。
如果读请求的地址在写缓冲区中存在(意味着有待写入的最新数据),则直接从写缓冲区获取数据。
写优先于读,可以减少读操作的开销,让缓冲区的写回在后台自行完成
即使是写回式高速缓存,写操作的开销也可以通过类似的方式减少:
当读失效需要替换一个“脏”的内存块时,不是先将脏块写回主内存,再从主内存读取新块,而是将脏块复制到写缓冲区中。
然后立即从主存读取新块
6. Avoiding Address Translation During Indexing of the Cache
直接用虚拟cache,在虚拟cache命中;如果未命中的话再去TLB中查找,节省时间
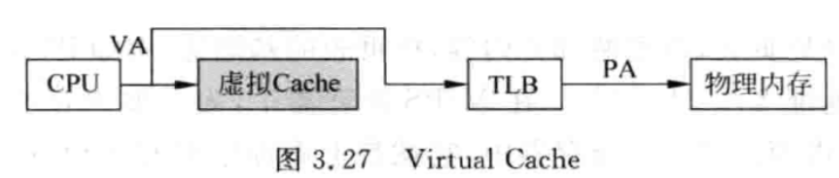
缺陷
考虑到虚拟地址转换为物理地址时的页级保护机制 (tlb包含数据是否不在内存中存在等信息)
通过在失效时拷贝 TLB 上的保护信息,并用一个字段来保存这个信息,并且在每次访问虚拟高速缓存时进行检查来克服这个问题
歧义(ambiguity) 问题:每当切换进程时,相同的虚拟地址就会指向不同的物理地址,需要对高速缓存进行清除操作
通过增加地址标签位的宽度,作为进程标识符标签(process-identifier tag, PID) 使用来解决这个问题。如果操作系统为进程赋予这些标签的话,它只需要清除那些 PID
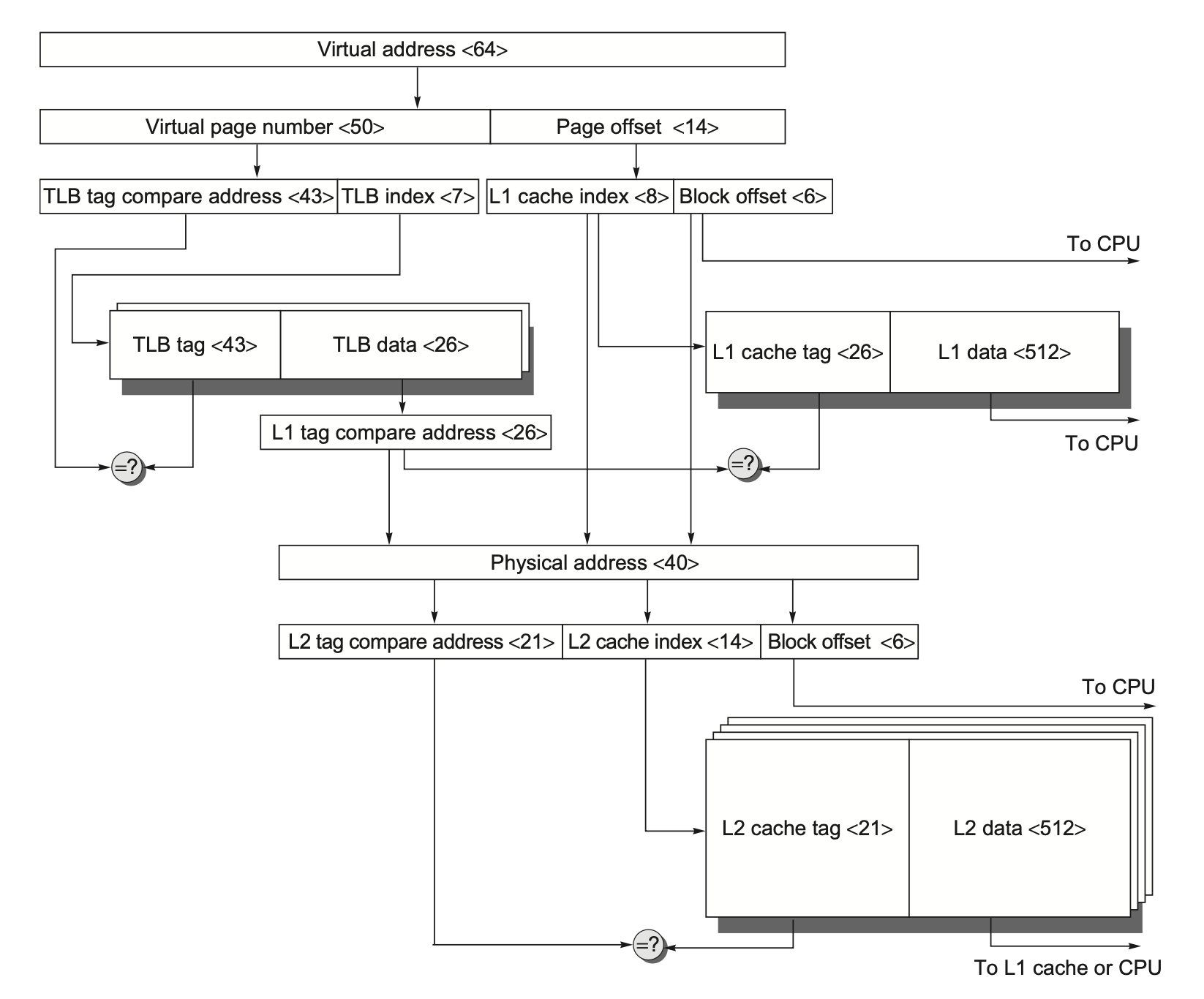
VIPT (virtually indexed, physically tagged):
前提提示,原本的Cache设计是,PIPT(physical‐indexed, physical‐tagged):先由 TLB(或页表)把虚拟地址 VA→物理地址 PA,再把 PA 的中间 Index₈ 和高位 Tag₂₆ 分离出来,去读 TagRAM、DataRAM;命中路径比较长
在 VIPT 中,(virtually indexed:)CPU 拿到 虚拟地址 VA〈63:0〉 后,直接把“页内偏移”(page offset〈13:0〉)再拆成两部分:
L1 cache index〈8〉
Block offset〈6〉
在还没做地址转换(VA→PA)之前就拿去给 L1 cache 把对应那个 set “并行”索引出来了。
physically tagged: 与此同时,VA 的“虚拟页号”〈50〉被送去 TLB,做 VA→PA 的翻译;才是真正用来跟 L1 cache tag RAM 比较的标签。
L2 Cache 比 L1 Cache 大得多,需要更多的 index(组选择)位,因此它拿走了原本属于 L1 tag 那部分的地址位来当 L2 index,留给 L2 tag 的高位就少了
十大进阶的高速缓存优化方法
在高级优化方法中,我们除了考虑 AMAT 公式中的三个因素外,还要考虑高速缓存的带宽和功耗问题
1. Small and Simple First-Level Caches
减小一级高速缓存(以下简称 L1)的大小,或者降低 L1 的相关程度都有助于减小命中时间和功耗。
最近的设计反而采用更高相联程度的高速缓存, 这是因为
很多处理器至少需要 2 个时钟周期来访问高速缓存,因此更长的命中时间并没有带来很大影响
2. Way Prediction
路预测(way-prediction):在高速缓存中保留额外的位(称为块预测器位(block predictor bit)),用于预测下一次可能被访问的数据块。
如果预测正确,高速缓存的访问时延就是很快的命中时间
如果预测失败,那么就要尝试下一个数据块,改变预测者的内容,并且会有一个额外的时钟周期时延 (n-way组相联代表一个组有n块)
3. Pipelined Access and Multibanked Caches
使高速缓存访问流水线化以及采用多个分区(banks) 加宽高速缓存都能提升高速缓存的带宽
主要针对L1
Pipelined Access: 将一次完整的缓存访问(Address Decode → Tag Compare → Data Read → 输出)划分成若干连贯的阶段,每个阶段在时钟的不同周期并行执行,类似处理器指令流水线 带来更高的时钟周期数,代价是提升了时延 ,可能导致更大的分支预测错误损失
采用多个分区加宽高速缓存:高速缓存被分为独立的分区,每个分区支持独立的访问
顺序交错
4. Nonblocking Caches
乱序执行的流水线 CPU 不会在数据高速缓存失效时停顿,比如它在等待获取失效数据的同时还能继续从指令高速缓存中获取指令。而非阻塞的高速缓存(nonblocking caches) 允许数据高速缓存在失效发生时继续提供命中,从而发挥出乱序流水线 CPU 的潜在优势。这种 "hit during miss" 的优化方法能够降低失效损失。
乱序处理器能够隐藏在 L1 失效但在 L2 命中的失效损失,但是无法隐藏更低级的高速缓存失效。
为什么:L1失效但L2命中往往只会有几十个时钟周期 的 penalty ,乱序引擎可以继续跑后面的后端流水;而L2 miss→L3 或 DRAM的惩罚是上百、上千个周期
5. Critical Word First and Early Start
在一次 Cache Miss 时,通常要从下一层存储(L2、L3 或主存)把整整一个缓存块(比如 64 Byte)搬上来再交给 CPU。但这中间有两种常见的提速小技巧,它们都能在块很大的情况下,把真正“究竟要哪几个字节”的那部分数据更早地送到处理器
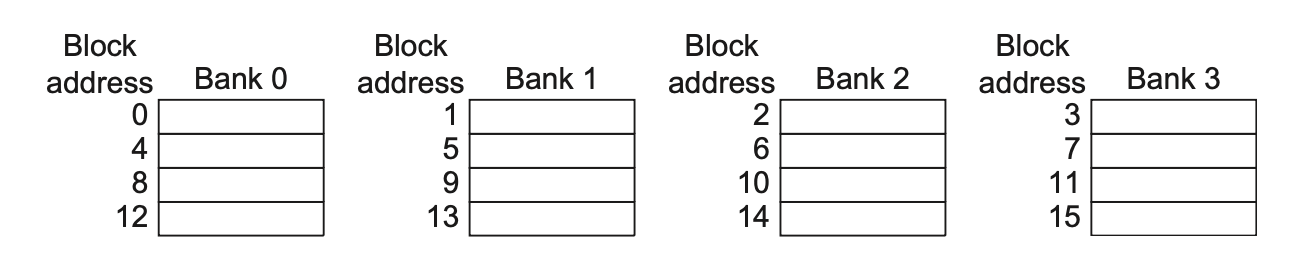
6. Merging Write Buffer
写穿依赖于写缓冲区,即使是写回有时也会用到写缓冲区。
剩下的不赘述了,建议看学长笔记
如果缓冲区包含一些被修改的数据块,那么就要检查一下地址,看这些新数据的地址是否与某个有效的写缓冲区项匹配,如果匹配的话,就将新数据并入到这个项里。这种优化方法称为写合并(write merging)。
写合并时,它检测到写操作属于同一个缓存块(即地址都落在 100–163 这一行里),于是把它们“合并”到同一个缓冲条目里:缓冲条目的块基地址仍然是 100;这样你只占用一个条目,就能连续发 4 次写,最后只在后端真正把整个 64-Byte 块一次写回去。
减少缓冲区条目消耗; 减少后端写回次数; 降低处理器停顿概率
7. Compiler Optimizations
合并数组、循环交换、循环融合、分块 ···
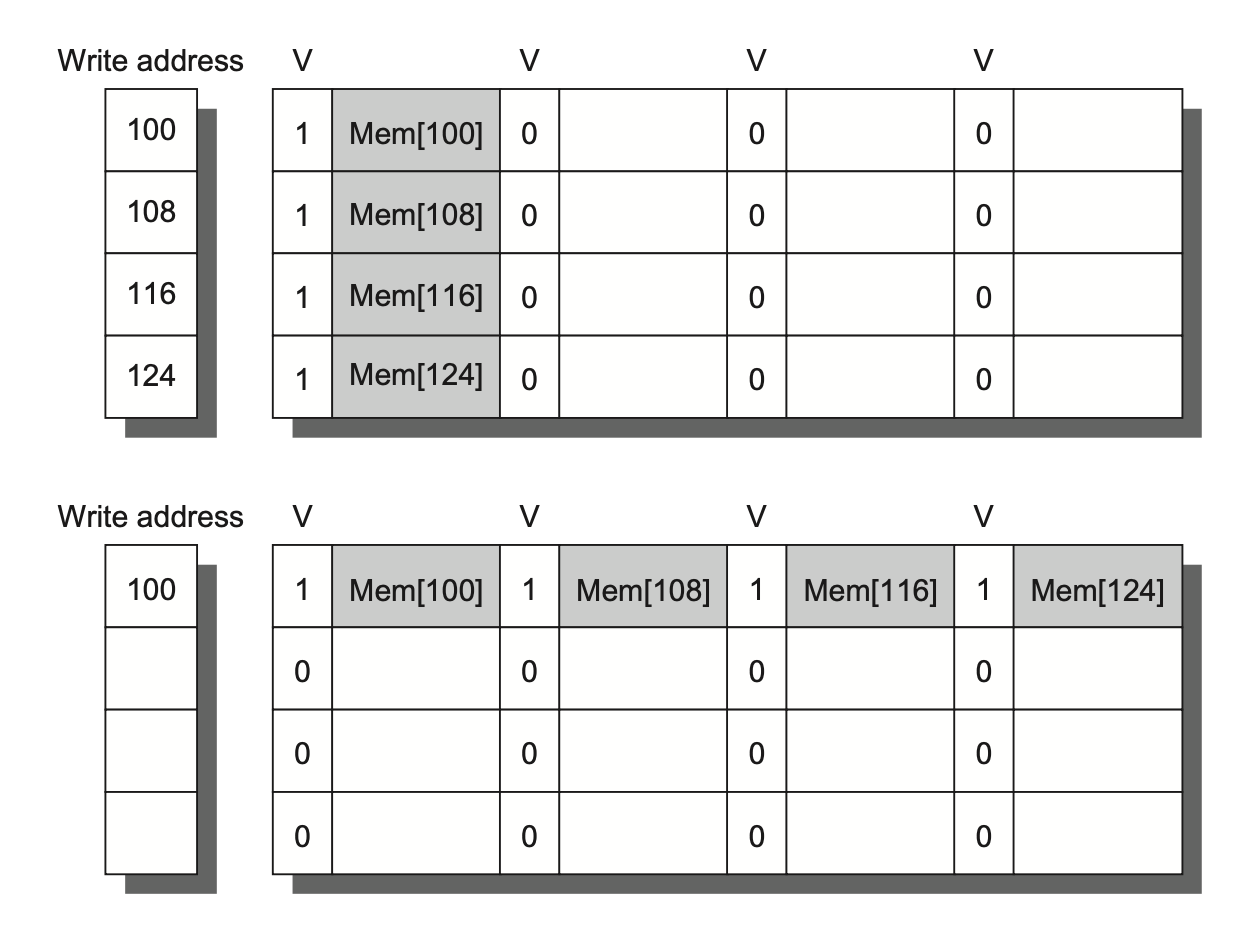
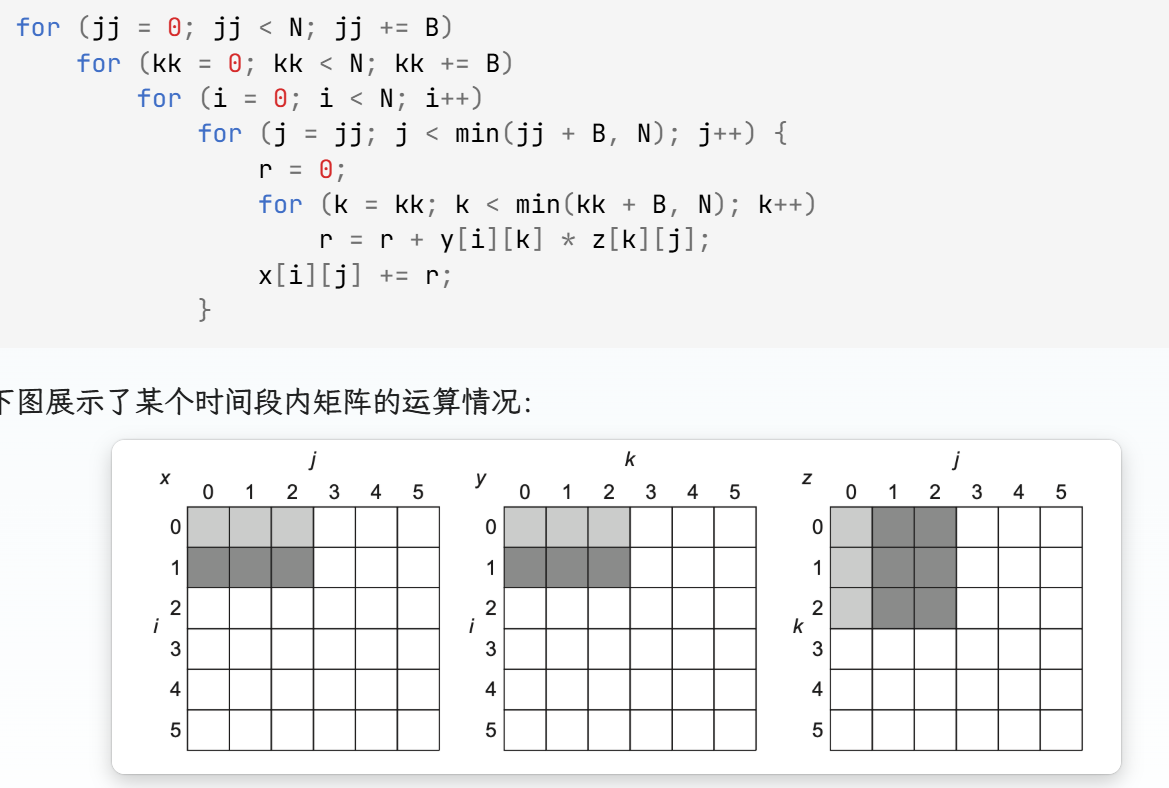
对于分块, 举一个例子
for (i = 0; i < N; i++)
for (j = 0; j < N; j++) {
r = 0;
for (k = 0; k < N; k++)
r = r + y[i][k] * z[k][j];
x[i][j] = r;
}如果N比较大的话,没有一个数据是可以复用的,N3 次运算需要访问 2N3+N2 个内存字数据。
需要将矩阵划分为 BxB 大小(B 称为分块因子(blocking factor))的子矩阵,逐个计算子矩阵乘法的结果,使得每一次分块之后的子运算,三个子数组都能被装在内存中
(N/B)2 (N/B)2B2 + N2 = 2N3/B+N2
8. Hardware Prefetching of Instructions and Data⚓︎
分为 指令预取 、 数据预取
带宽利用:预取依赖于利用原本可能未被使用的内存带宽;如果预取与实际需求访问竞争带宽,反而可能降低性能
当发生指令失效时,处理器不仅会请求当前缺失的指令块,还会预取下一个连续的指令块
这些预取到的块会被放置在指令流缓冲区(stream buffer) 中
数据预取也类似
9. Compiler-Controlled Prefetching
硬件预取的替代方案是使用编译器(compiler)
寄存器预取(register prefetch):将值加载到一个寄存器里。
高速缓存预取(cache prefetch):将数据仅加载到高速缓存中。
10. Using HBM to Extend the Memory Hierarchy
用 高带宽内存(HBM) 做成一个容量极大的 L4 缓存
分块大小:
小块大小(如 64 B)
HBM 容量如几 GB,要分成 64 B 一块,标签(Tag)数量就天文级
大块大小(如 4 KiB)
碎片化:每次拉入 4 KiB,块内往往只用其中很小一部分,浪费空间和带宽。
传输效率低:真正要用的数据可能散落在整块里,多数字节没被“命中使用”却被加载上来。
冲突 & 一致性缺失增多:在同样容量下,大块数目少,很容易不同地址映到同一组,引起更多冲突失效;再加上一致性管理也更麻烦。
传统标签存储延迟高
如果把 Tag 存在 HBM 里,每次访问都要两次 DRAM 访问(先取 Tag,再取 Data),往返可能 100+ 周期,根本不实际。
Loh & Hill 方案(“L–H”)
把Tag和Data都放在同一行(row)里,利用 DRAM 行打开(row-activate)带来的并行带宽。
. Qureshi & Loh 合金缓存
在 L–H 方案基础上,将 Tag 与 Data 融合存储,并且改为直接映射。
不再做组相联查找,Index 直接选出这一行唯一的 Tag+Data 段。
虚拟内存
(https://note.noughtq.top/system/ca/2#virtual-memory)
虚拟内存采取一种保护机制,防止属于某个进程的内存块被其他进程访问
减少开始程序的时间:因为无需物理内存中所有的代码和数据
高速缓存失效的替换是由硬件控制的,而虚拟内存的替换是由操作系统控制的
cache 和 虚拟内存
对 L4 这样做虚拟内存后级的 Cache,我们最核心的目标是把缺失率(miss rate)降到极低。
全相联比组相联、比直映射,都能把替换导致的冲突降到最低
写策略: 写回(Write-back)+写分配(Write-allocate)
写回 则只在Cache 块被驱逐(evict)时才写回主存,大幅减少主存写次数。
以下这张图体现全相联
Chap 3: Instruction-Level Parallelism
指令级并行
基于硬件的动态并行
基于软件(编译器)的静态(编译时)并行
Dependences in Instructions
1. Data Dependences
2. Name Dependences
3. Data Hazards
4. Control Dependences
Loop Unrolling and Scheduling
未经 调度 的 RISC v 代码
Loop:
fld f0, 0(x1)
fadd.d f4, f0, f2
fsd f4, 0(x1)
addi x1, x1, -8
bne x1, x2, Loop经过循环展开后,部分 addi 和 bne 被消除了

再加以调度,避免了过多的停顿

限制
更大的代码规模可能会带来更大的高速缓存失效率
寄存器压力(register pressure):用来存放“活值”的寄存器变得更多,导致可用寄存器变少,尤其为多发射处理器带来困难
Advanced Branch Prediction
EX
https://note.noughtq.top/system/ca/3#advanced-branch-prediction
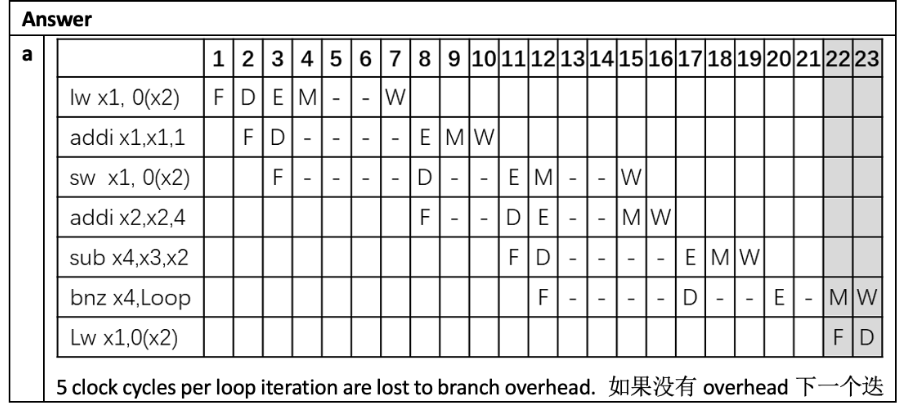
注意到两点:
1. lw的三次停顿在Mem阶段,bnz的两次停顿在Ex阶段
2. 前一个指令F进入D之后,后一个指令才能进入F
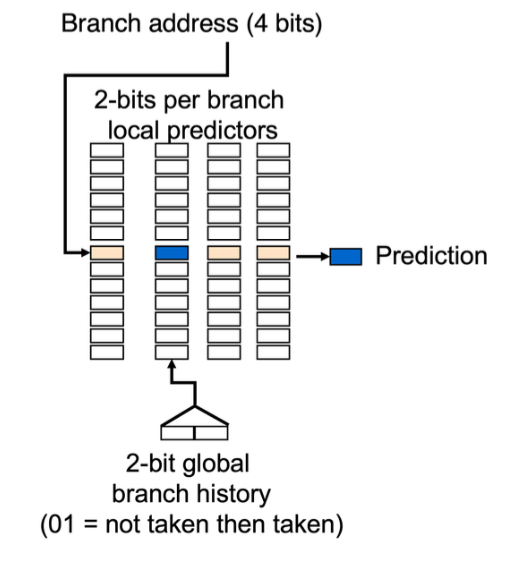
Correlating Branch Predictors (相关预测器)
不同分支之间具有相关性 使用
(m,n) 相关预测器能够预测最近 m 个分支的行为
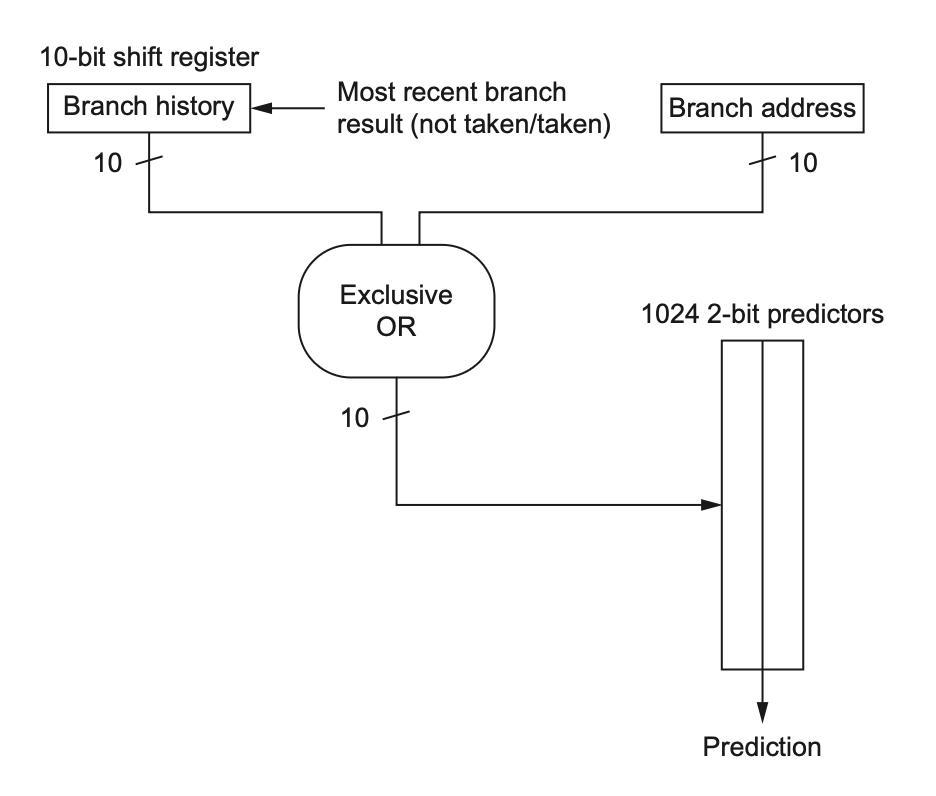
(m,n) 预测器的总位数为:
2m×n×Number of prediction entries selected by the branch address
要预测地址 的 低10位 和 历史的10位记录进行亦或;得到了m位二进制,已知m位共有2m种可能,这是对应predictors的列索引;而 branch address 的低n位 mod Number of prediction entries selected by the branch address 则是行索引 ;n表示预测出来有几位
二位预测器也是类似的行列索引
Tournament Predictors
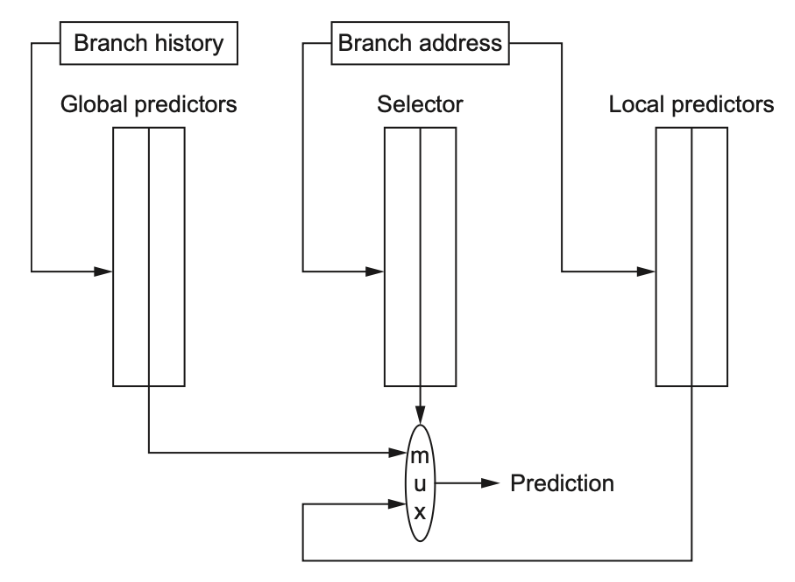
利用一个 预测器的预测器 , 来选择 全局预测和局部预测 的 其中一种
Dynamic Scheduling
乱序执行
乱序执行会引入 WAR 和 WAW 冒险的可能 , 不过这两类冒险都可以用寄存器重命名来避免
fdiv.d f0, f2, f4
fmul.d f6, f0, f8
fadd.d f0, f10, f14对于f0 ,fmul和fadd存在 WAR , fdiv和fadd存在 WAW
为了实现乱序执行,我们将流水线的 ID(译码)阶段划分为两个子阶段:
发射(issue):对指令译码,检查结构冒险(顺序发射)
读取操作数(read operands):等待,直到没有数据冒险,然后读取操作数(乱序执行)
Scoreboarding⭐
执行过程
发射 (issue)
如果 unit 被占用,就根本进不来
如果结构冒险或 WAW 冒险存在,那么必须停止指令发射
当停顿发射时,IF(指令获取)和发射阶段之间的缓冲区将会被填充。
如果缓冲区只保存单项,IF 能够立刻停止;
如果缓冲区是一个能保存多条指令的队列,那么只有当队列被填满时 IF 才停止
读取操作数 (read operands)
若没有先前发射的活跃指令要向其写入的话,该源操作数就是空闲的;被送往执行阶段
解决了 RAW 冒险
执行 (execution)
写入结果(write result)
先检查 WAR 冒险, 没有冒险之后再写回
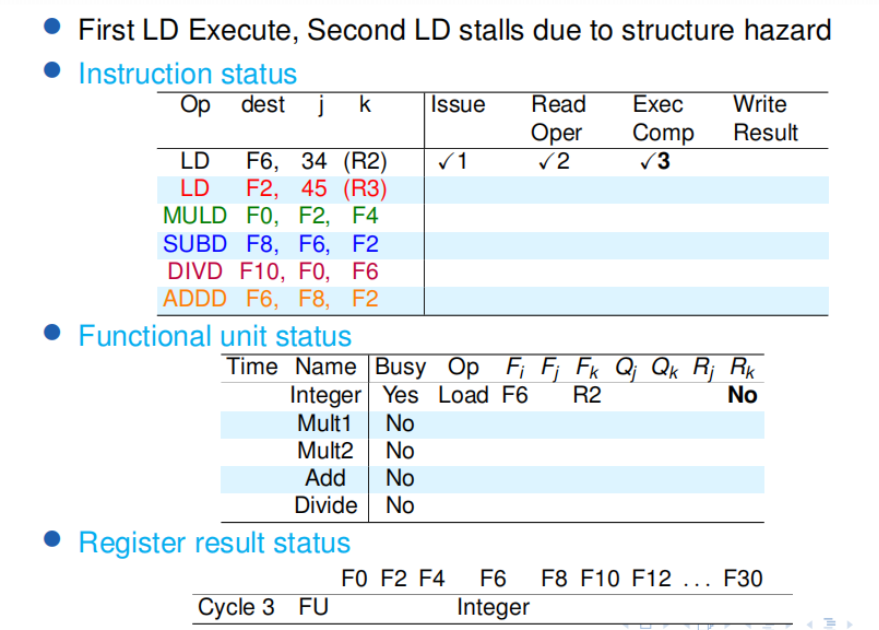
观察到
某个指令在 issue ReadOper Exec 阶段会占用 Functional unit status 和 Register result status 的一行 (;
在Issue 和 Read Oper阶段, Functional unit status 的 R 如果是no表示没准备好,不能进入 Exec;在 Exec阶段 Functional unit status 的 R 都会no,表示不读占用了,可以写入了
写入结果和读取寄存器阶段不得重叠, 在 RAW 中,write back 的下两周期 另一个指令才能进入Exe
structure hazard ,在 writeback 下一个周期可以 issue
read operation 打勾 代表已经读到了
Qi Qj 在源操作数未准备好的时候记录对应的等待的unit
记得sd指令没有目标寄存器
Tomasulo's Algorithm⭐
RAW 冒险可通过在操作数空闲时就执行指令来避免
WAR 和 WAW 冒险可通过寄存器重命名(register renaming) 来消除。
WAW 中,把前一个W的目标寄存器重命名,在这两个W之间用到的前一个W的目标寄存器的读都要使用重命名的这个
WAR中,把W的目标寄存器重命名,在W之后用到的这个寄存器也要用重命名的这个
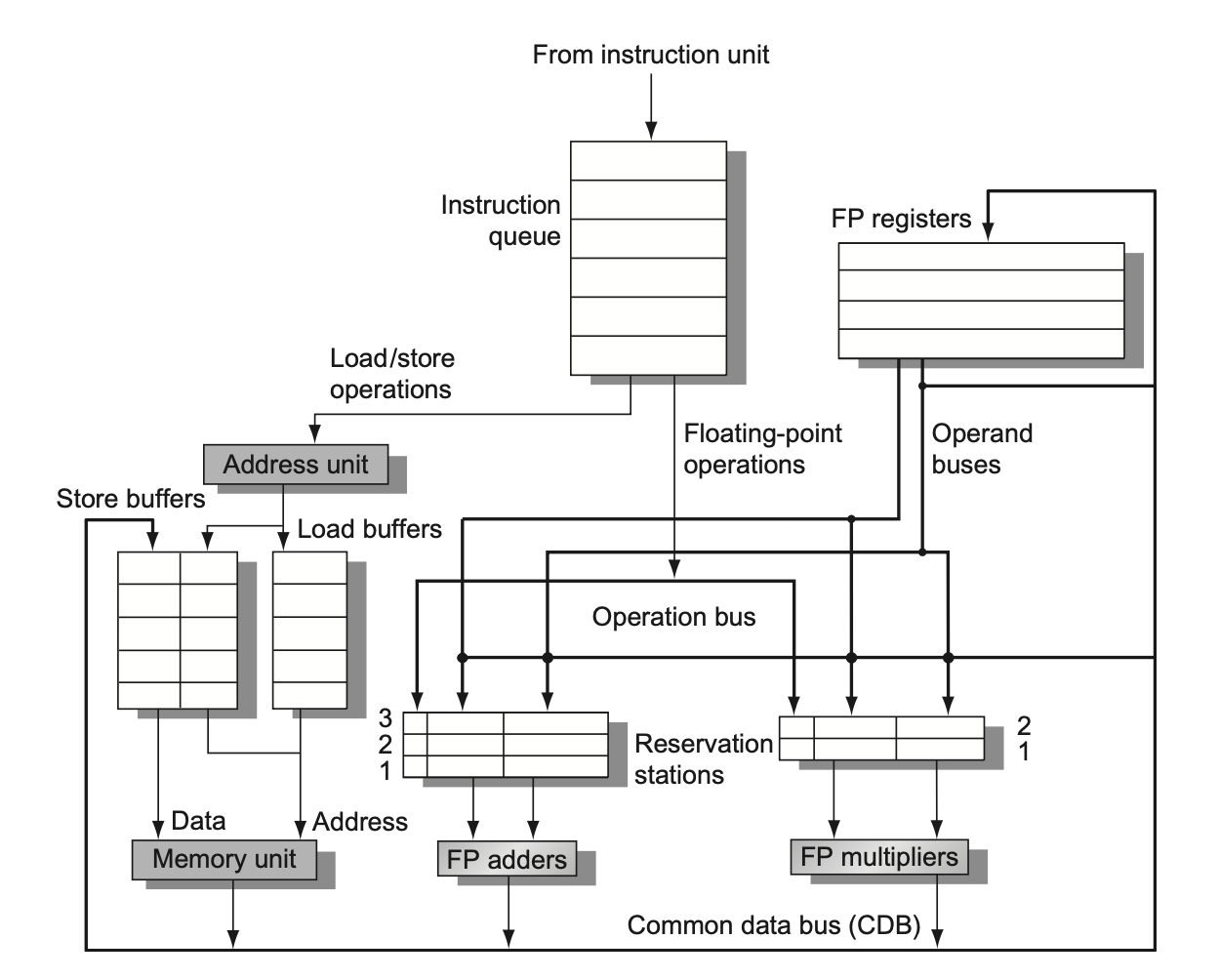
发射(issue)(有时会称为分派(dispatch)):
从指令队列(FIFO 顺序,以维持正确的数据流)的队首中获取下一条指令
每个unit对应一个 保留站 ,当指令相对应的保留站有空闲时就会读入指令
如果操作数不在寄存器内,那么追踪会产生操作数值的那个功能单元
这一步会对目标寄存器进行寄存器重命名 (消除了 WAR 和 WAW 冒险),所以表格中没有目标寄存器了,都用别名替代
执行(execute)
如果一个或多个操作数不可用的话,那么监控 CDB,等待操作数被计算出来; 从unit算出来可以直接到总线进入保留站
(RAW 冒险得以避免)
Load 在 Execute的 时候只需要 写A就行
这里的RAW 从wrieback到execute只需要一个周期就行了
写入结果(write result):
当结果可用时,将其写入 CDB 中,然后再写到寄存器以及任何等待该结果的保留站中(这一操作称为广播(broadcast))
存储操作一直缓存在存储缓冲区内,直到值被存储,且存储地址可用
Write result 打勾之时,保留站被释放,Busy置No
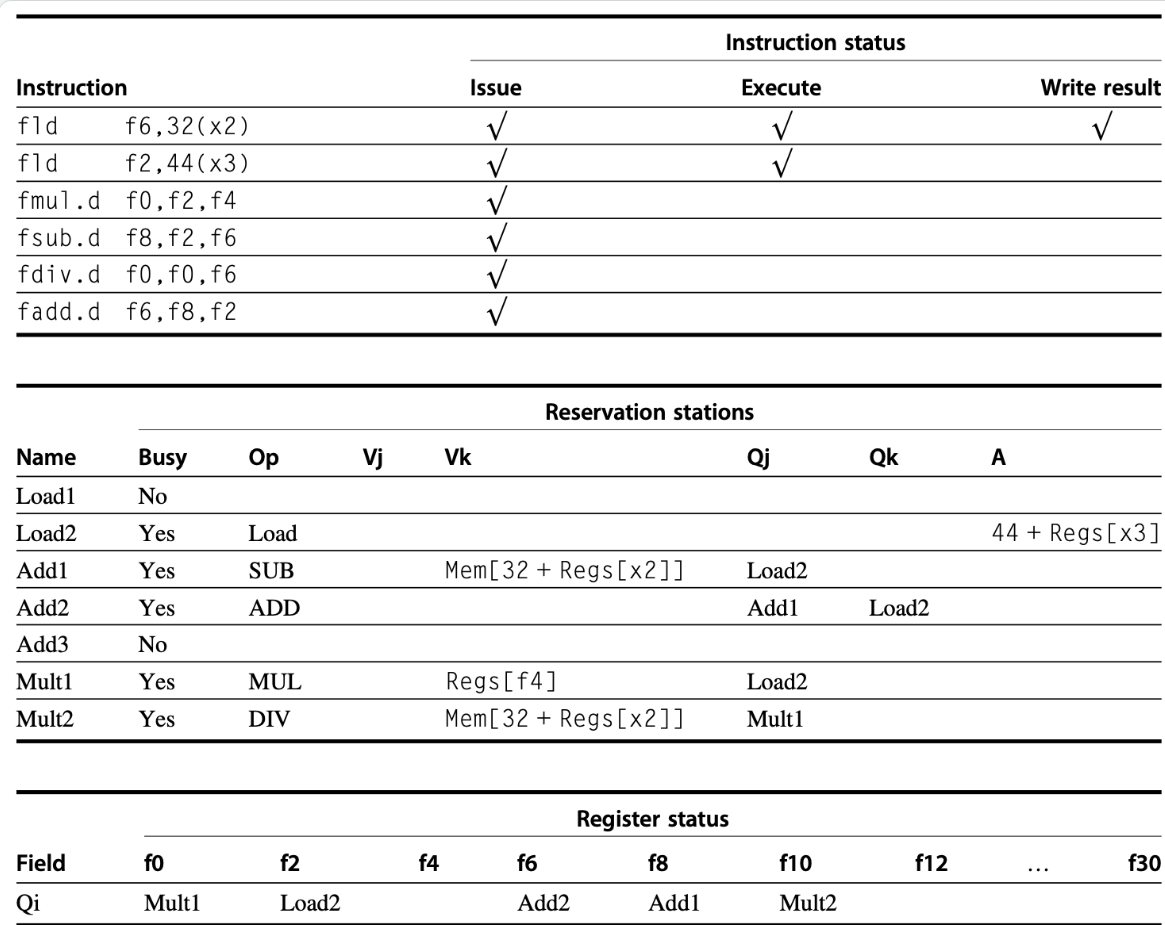
第二张表,对于同一条指令,同一个操作数 V 和 Q 只有一个能被赋值
V表示源操作数的值,可以是Reg[f4],也可以是Mem[32+Regs[x2]]
Q表示没有准备好的数对于的计算单元,即使已经在做Ex这里也还未准备好
A 就是加载或存储指令 Mem[*] 里面的这一部分,表示地址的计算结果
Hardware-Based Speculation ⭐ 能在分支还没算出来前下一条指令进行运算
维护了一个 重排缓冲区(reorder buffer, ROB),寄存器重命名由他负责 ; 每条指令在提交前必须在 ROB 上有个位置,因此我们用 ROB 每项的编号来为结果打标签,而这个标签必须能被保留站追踪到。
包含: 指令类型 、 目标字段(写入寄存器还是内存)、 值字段 、 准备字段(是否执行完毕)
硬件推测过程
发射
存在一个空的保留站以及一个空的 ROB 项,则发射该指令
ROB 的项数也要送到保留站内
执行
和tomasulo类似
写入结果
当结果可用时,将其(以及 ROB 标签)写入 CDB,然后从 CDB 写到 ROB 以及其他等待该结果的保留站内
提交
正常提交(当指令到达 ROB 头,且对应值在缓冲区内时):处理器用指令执行结果更新寄存器,并移除 ROB 内的指令
提交存储指令:和前一种情况类似,只是更新的东西变成了内存而非寄存器
错误预测的分支指令(即推测错误):清除 ROB 里的内容,重新开始分支指令后的正确指令
EXERCISE

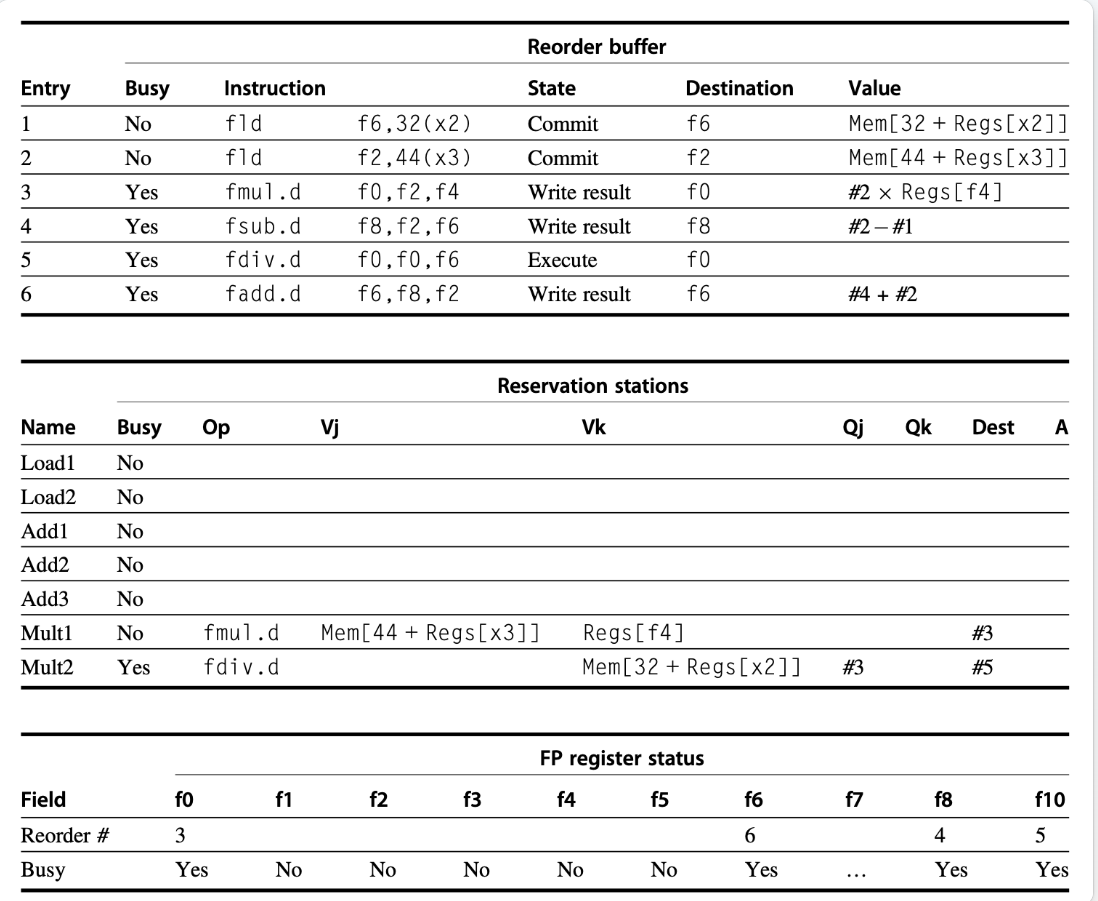
注意到,Qj,Qk,Dest,Value中的一些 值都变成了ROB的提交序号,说明重命名的确是在ROB完成的
由于3未提交,而4,6的提交顺序在其之后,故尽管4,6早早做完了 ,但仍然需要在Commit处等待
Reservation stations 表中有 Reorder buffer的序号
Reorder buffer 和 FP register status 的 busy是看指令有无最终提交,Reservation stations 的busy是看 有无执行完成
可能存在 RAW 冒险的问题,在做加载之前要检查存储
Value 只有进入 reorderbuffer之后 才会 显示
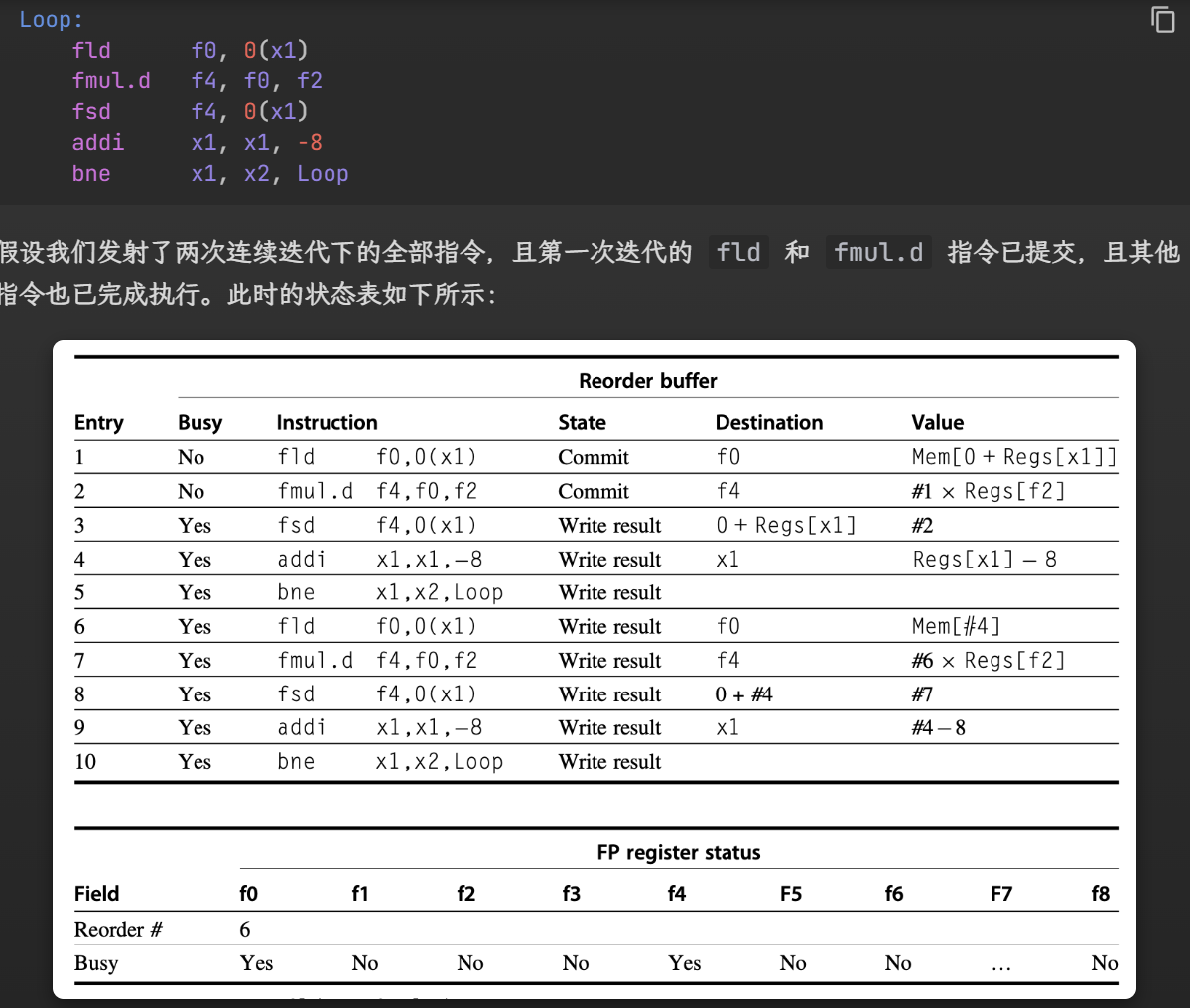
第七条指令不需要重命名了,因为
Multiple Issue
Using Static Scheduling
VLIW 采用多个独立的功能单元,将多个运算打包成一个非常长的指令
循环展开和代码调度来实现
假设 让指令包含 5 个运算:1 个整数运算、2 个浮点数运算和 2 个内存引用运算。
do {
f0 = MEM[x1+0]; // fld f0,0(x1)
f4 = f0 + f2; // fadd.d f4,f0,f2
MEM[x1+0] = f4; // fsd f4,0(x1)
x1 -= 8; // addi x1,x1,−8
if (x1 != x2) goto Loop;
} while (1);
Using Dynamic Scheduling and Speculation
将动态调度、多发射和推测这三项技术结合起来
1. 预先分配资源
在真正开始往保留站和 ROB 填写依赖之前,就先从空闲的保留站池里挑出 n 个槽位、从空闲的 ROB 里拿出 n 个条目,一次性“预留”好给这一组要发射的指令
2. 包内依赖分析
把这 n 条指令拿出来,对每条的源操作数看它到底依赖谁:
如果依赖的是包里前面的某条指令,就属于“内部依赖”;
如果依赖的是包外(已经在 ROB/保留站里,或者寄存器堆里记录的旧值),就是“外部依赖”
3. 基于依赖来源填表
内部依赖:第 j 条指令如果要读第 i(<j)条指令的结果,就直接把它的
Q字段填成“i 号的 ROB 条目”,这样两个指令在同一个周期“打包”发射也能立刻连上依赖。外部依赖:要么读已就绪的寄存器值,要么读 ROB/保留站里更早分配的标签(和单发模式完全一样)。

没推测的:每轮迭代的
bne都要等到算到结果 , 下一条指令才开始 Execute ; 而有推测的永远不会“分支错误”
7 Advanced Techniques for Instruction Delivery and Speculation
7.1 Increasing Instruction Fetch Bandwidth
7.1.1 Branch-Target Buffers
定义:BTB是一个小型的、高速的缓存。它专门用来存储近期执行过的、并且被预测为“会发生跳转”(Taken)的分支指令的地址,以及它们跳转的目标地址(Predicted PC)。
目的:它的核心目标是在分支指令被正式译码和执行之前,就预测出它的行为
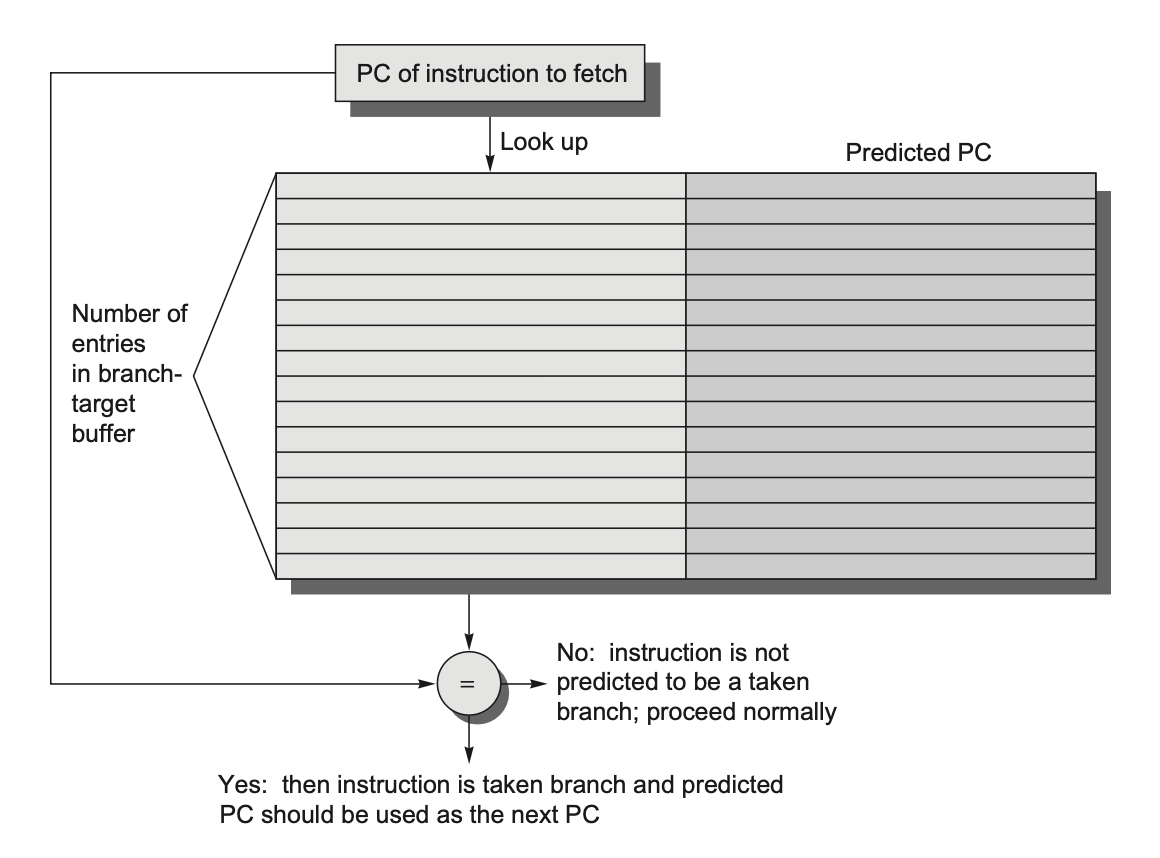
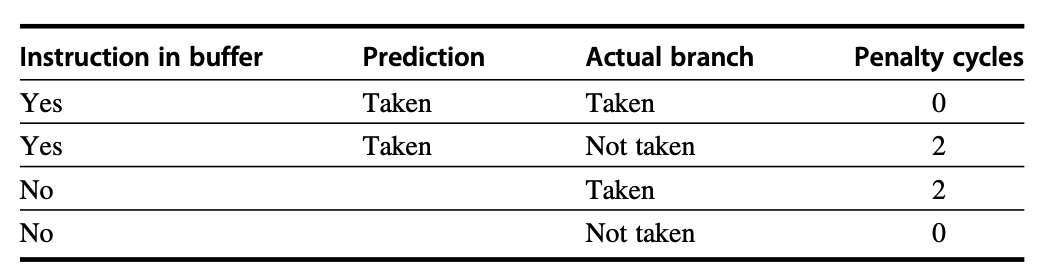
7.2 Specialized Branch Predictors
预测间接跳转(indirect jump)存在挑战
对于函数返回,如果简单地使用常规的分支目标缓冲器(BTB)来预测,精度会很低。因为同一个
return指令,每次执行时需要返回的地址都不同,BTB只会记住上一次的返回地址,导致频繁的预测失败。
解决方案:返回地址栈 (Return Address Stack/Buffer)
压栈 (Push):当处理器执行一个函数调用指令 (call) 时,它会预测这是一个调用,并将紧随调用指令之后的指令地址(即返回地址)推入一个专门的小型硬件栈(返回地址栈)中。
弹栈 (Pop):当处理器遇到一个函数返回指令 (return) 时,它会预测这是一个返回,然后直接从返回地址栈的栈顶弹出一个地址,并将其作为预测的PC值。
后进先出”(LIFO)的结构
7.3 Implementation Issues and Extensions of Speculation
7.3.1 Speculation Support: Register Renaming v.s. Reorder Buffers
7.3.2 The Challenge of More Issues per Clock
只有当采用了精确的分支预测和推测时,我们才会考虑增大发射率,否则的话会因为要解决分支问题而很难扩大发射率
在一个时钟周期内,这些指令的依赖关系必须被检测出来,必须为其赋予物理寄存器,并且指令必须用物理寄存器编码被重写。
较为困难复杂
7.3.6 Address Aliasing Prediction
8 Cross-Cutting Issues
Speculative Execution and the Memory System
支持推测执行和条件指令的寄存器可能会产生非法的地址,从而影响到处理器的性能,这在没有推测执行的处理器中是不会发生的。因此,内存系统必须识别出推测执行的指令和条件执行的指令,镇压住对应的异常。而且,我们不能让这样的指令导致高速缓存的停顿或失效,因此处理器必须和非阻塞的高速缓存匹配。
9.Multithreading: Exploiting Thread-Level Parallelism to Improve Uniprocessor Throughput
在传统架构里,当一个线程因流水线冒险或缓存 miss 而停下来(stall)时,整个处理器就空转了;
而在多线程模型下,处理器可以在不停顿的时钟周期内 快速切换(几乎无需走完全上下文切换)到另一个就绪线程继续发射指令,充分利用每个周期。

Chap 4: Data-Level Parallelism
数据级并行中最知名的为 SIMD(single instruction multiple data,单指令多数据)技术,最大的优势在于程序员仍能继续按照串行方式思考代码,而与此同时底层能通过并行实现加速运算。
本章主要介绍的内容分为三大块,它们都是 SIMD 的变体:
向量架构(vector architecture)
多媒体 SIMD 指令集扩展(multimedia SIMD instruction set extensions)
图形处理器(graphic processing units, GPUs)
Vector Architecture
向量架构的大致原理可以概括为:获取分散在内存中的数据元素集,将它们放在一个较大的顺序寄存器堆内,在寄存器堆上对数据进行操作,最后将结果分散放回到内存中。
1.1 RV64V Extension
传统的向量机 有 指令集臃肿、上下文开销大 的缺点,动态寄存器类型按需“启用”寄存器;设置最大向量长度,禁用那些没用到的向量寄存器
由于存在数据依赖,RV64G 指令会有很多停顿;但在向量处理器中,每个向量指令仅需为向量的第一个元素停顿,之后的元素就会很丝滑地流过流水线,因此这样的元素依赖运算被称为链(chaining)。(load第一个元素之后第一个mul也可用了,不用等到第n个load结束)
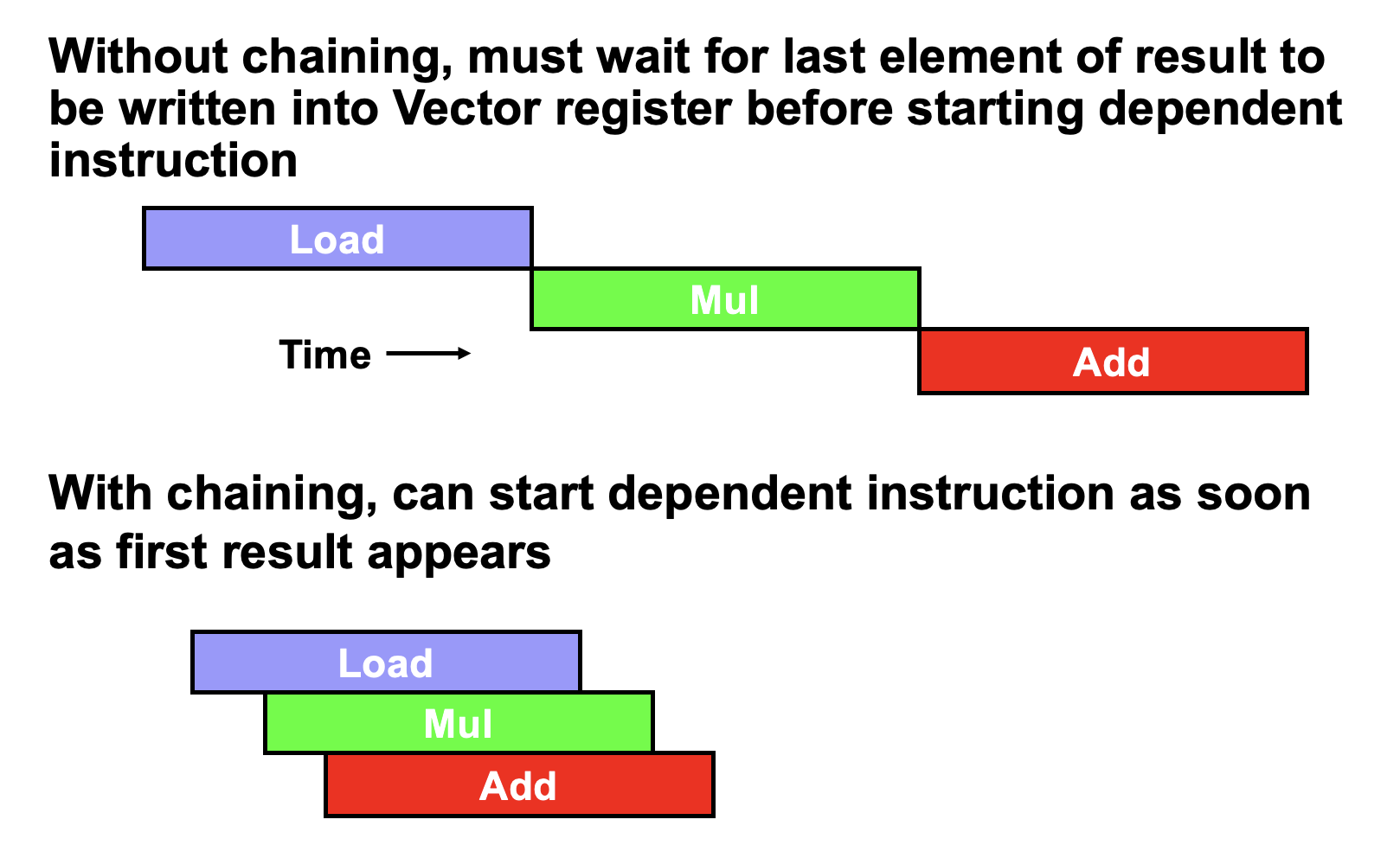 下面那三个称为一个指令组convoy(chimes)
下面那三个称为一个指令组convoy(chimes)
1.2 Vector Execution Time
如果我们能够知道向量长度(VL)和初始化速率(initiation rate)(即向量单元接收运算符并产生结果的速率)的话,我们就能计算单条向量指令的计算时间。
假设 填满流水线:需要 D 周期,才能看到第一个结果;
总的执行时间大致是:
T≈D+VL/IR

上面这串指令要分成几个「convoy」才能安全地一起发射呢?
convoy 1:
vld+vmul:vmul v1,v0,f0依赖于vld v0,x5;但向量流水线支持 chaining——第 1 个元素一从vld流出,就可以立刻送给vmul,所以两条指令可以放在同一个周期一起发射。并且不会发生结构冲突convoy 2:
vld+vadd: 第二条vld v2,x6不能跟第一个vld一起发射:只有一个载入单元,存在结构冒险,必须分到下一个周期。convoy 3:
vst和前面的vld又争一个 Load/Store 单元,所以只好分到第三个周期单独发射。
对于一个 32 元素的向量,总体所需周期约为
chimes×vector length= 3×32=96 周期
(再加上少量发射和流水线启动延迟,大约也是这个量级。)
1.3 Optimizations
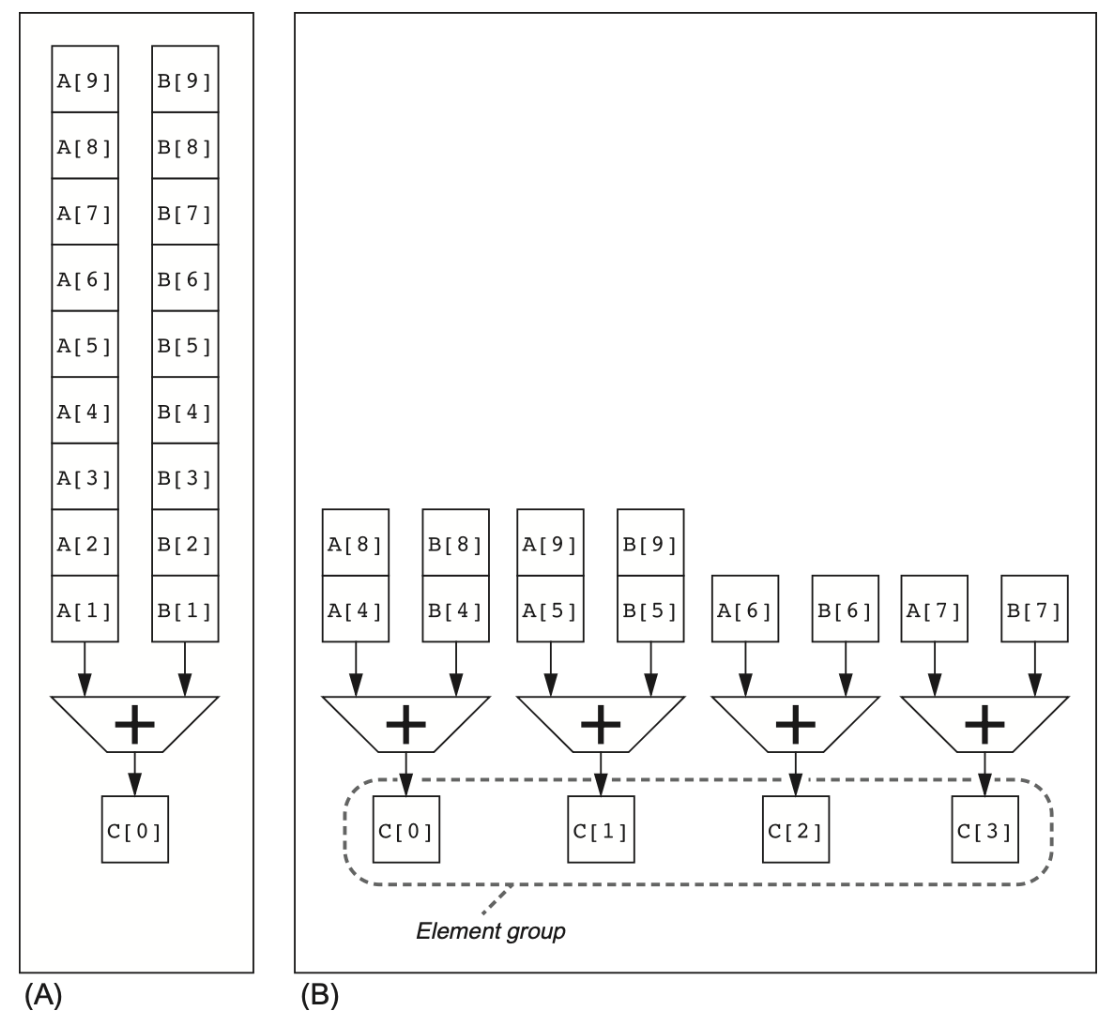
1.3.1 Multiple Lanes(多通道)
“多通道”(multiple lanes)优化的精髓就在于,把原来单条向量指令在一个功能单元流水线上“逐个元素送入”的执行方式,扩展成在多个独立但同构的流水线(lane)上并行推进多个元素组(element‐groups)。
图中左侧是没有优化过的普通的向量计算,如果IR为1的话还得一个一个送进去
1.3.2 Vector-Length Registers
在真实程序里,往往要处理的向量长度 n 并不恰好等于硬件能支持的最大向量长度 MVL ; n 通常是在运行时才知道的 , n 可能大于 MVL
RISC-V 的更优解:
setvl指令不需要手动分两段写:前面成批 MVL,再写尾部。
if rs1 > MVL then vl ← MVL, rd ← rs1 – MVL
else vl ← rs1, rd ← 01.3.3 Predicate Registers
如果程序中有包含 IF 语句的循环的话,就不能以(上述介绍过的)向量模式运行程序,因为 IF 语句引入了控制依赖
for (i = 0; i < 64; ++i)
if (X[i] != 0)
X[i] -= Y[i];向量掩码控制 ; 在 RV64V 中,谓词寄存器保存掩码 ; 当谓词寄存器
p0被设置时,所有向量指令仅操作对应项在谓词寄存器里的值为 1 的向量元素,对应值为 0 的元素就不会发生改变
1.3.4 Memory Banks
向量加载 / 存储单元的行为相比算术功能单元会复杂得多——它们的初始化速率不一定是 1 个时钟周期,因为内存分区的停顿会减少有效的吞吐量 ; 为了维持理论上的初始化速率,内存系统必须能够产出或接收大量数据,具体做法是将访问分散在多个独立的内存分区中
硬件通常会把“以元素为单位”的地址按低位几位轮询地分到各个bank。
元素宽度为 E 字节(比如双精度浮点 E=8),
总共有 B 个bank(比如 B=8),
元素在内存中的起始字节地址是 Addr,那么它属于哪个bank,通常这样算:
bank_id = (Addr / E) mod B
1.3.5 Stride
在实际的数值计算里,向量中相邻元素在内存里的布局不一定是「紧邻」的。尤其像矩阵乘法这种双重嵌套循环:
for (i = 0; i < 100; ++i)
for (j = 0; j < 100; ++j) {
A[i][j] = 0.0;
for (k = 0; k < 100; ++k)
A[i][j] += B[i][k] * D[k][j];
}为了支持任意 stride 的向量访问,RISC-V Vector 扩展提供:
vlds vd, (rs1), stride:从基址rs1开始,每隔stride× 元素宽度字节,载入vl个元素到向量寄存器vd。vsts vd, (rs1), stride:将vd中的vl个元素,以同样的 stride 存回内存。
这样在软件层面,就能一次性把稀疏分布在内存中的一列或对角线“抽”到一条向量寄存器里,像邻近元素那样并行计算。
设有 B 个 banks,步幅为 S 个元素,则当多个并行请求的地址模 B 相同,就会冲突。
只要满足
B / gcd(S,B)>bank busy time
就可以避免冲突
1.3.6 Gather-Scatter
1.3.7 Programming Vector Architecture
Detecting and Enhancing Loop-Level Parallelism
Finding Dependences
for (i = 0; i < 100; ++i) {
A[i+1] = A[i] + C[i]; // S1
B[i+1] = B[i] + A[i+1]; // S2
}当前迭代下的
S1(A[i])会用到先前迭代下的S1计算得到的值(A[i+1]);S2也存在这一依赖(B[i]和B[i+1])。该依赖是循环携带的,迫使循环中连续的迭代按顺序执行。S2使用相同迭代下S1计算得到的值A[i+1]。该依赖并非循环携带的,所以如果仅存在这一依赖的话,循环中的多个迭代还是可以并行执行的(比如使用前面提到过的循环展开等方法)。假设我们以索引值
a * i + b存储某数组元素后,又以c * i + d的索引值从该数组中加载数据若存在循环携带的依赖关系,则
GCD(c, a)必须能整除(d - b)


Eliminating Dependent Computations
点积的规约
for (i = 9999; i >= 0; --i)
sum += x[i] * y[i];把乘机和求和拆开,分别并行
for (i = 9999; i >= 0; --i)
sum[i] = x[i] * y[i];
for (i = 999; i >= 0; --i)
finalsum[p] += sum[i + 1000 * p];Chap 5: Thread-Level Parallelism
Introduction
由于 ILP 工艺进步的放缓,单处理器 (uniprocessor) 的发展逐渐走向尾声,因而多处理器(multiprocessor) 的重要性日渐提升
1.1 Multiprocessor Architecture
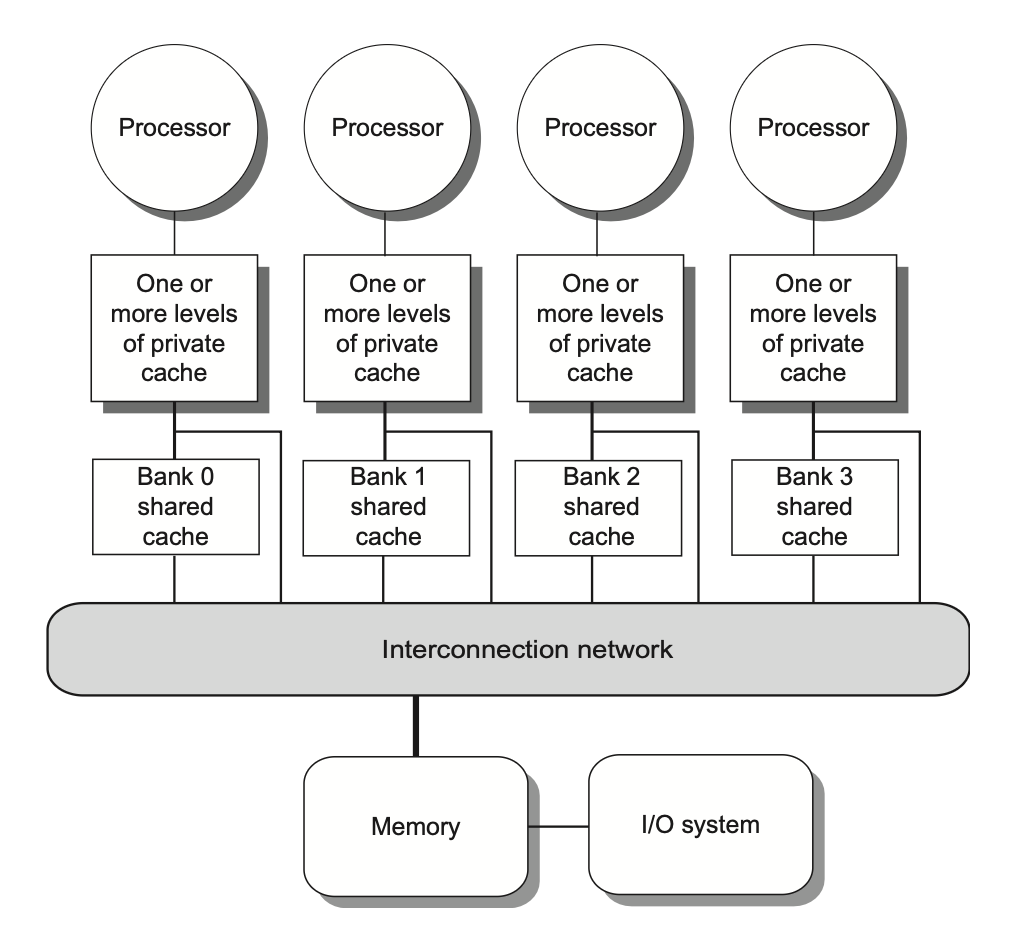
对于现有的共享内存多处理器,根据其内存组织的不同,可以划分为以下两大类:
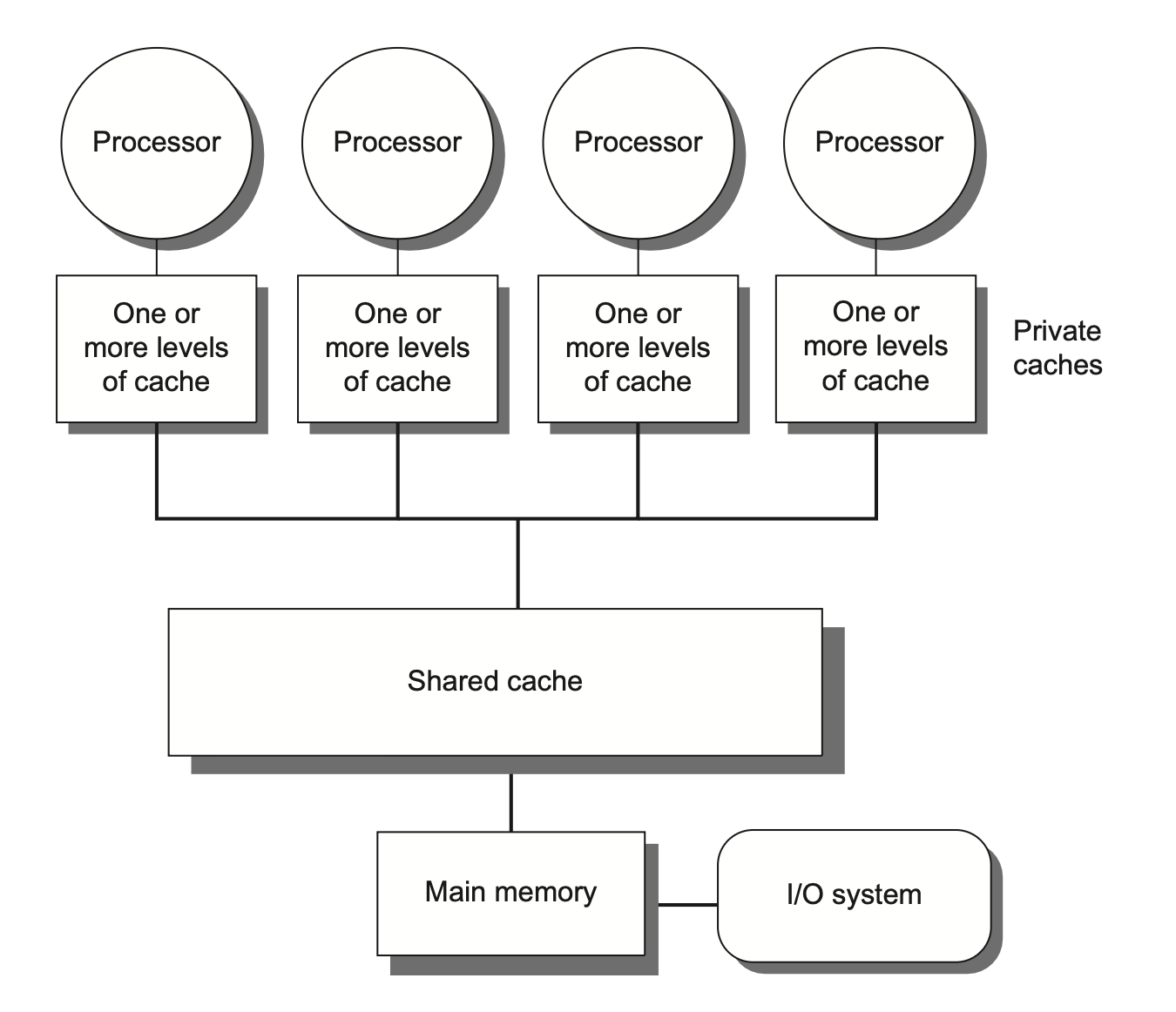
对称(共享内存)多处理器(symmetric (shared-memory) multiprocessors, SMP)
所有处理器对内存的访问延迟是均等的,即便内存被划分为多个分区亦是如此
分布式共享内存(distributed shared memory, DSM)
在由多个多核芯片构成的多处理器系统中,每个多核芯片通常配备独立的内存单元,因此这类系统的内存采用分布式组织而非集中式组织
许多分布式内存设计能实现对本地内存的快速访问,而远程内存访问速度则显著下降
为支持更多的处理器数量,内存必须是分布组织而非集中组织;否则内存系统将以增大访问延迟的代价来满足更多处理器的带宽需求'
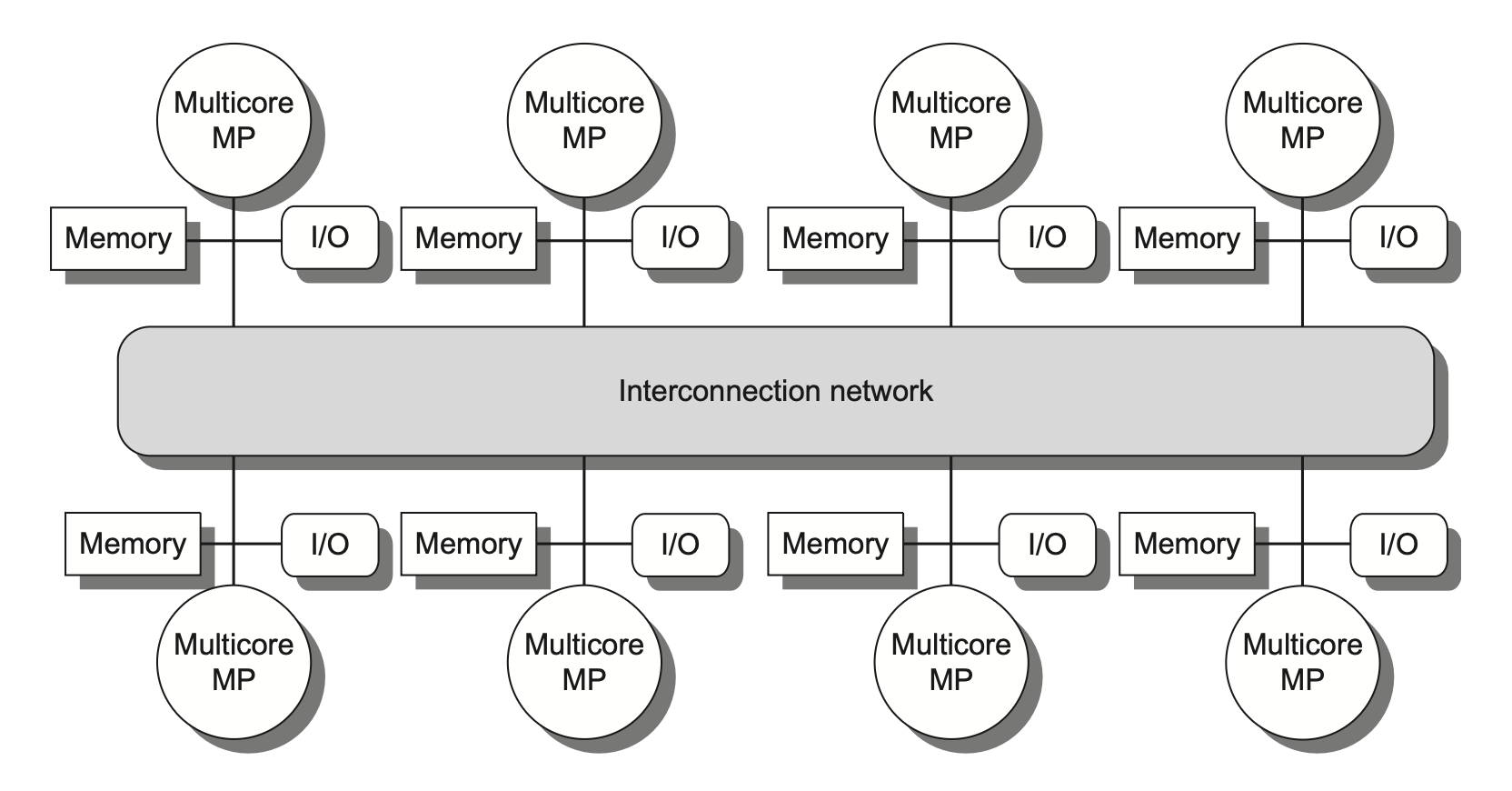
DSM 多处理器也被称为非均匀内存访问架构(nonuniform memeory access, NUMA),因为数据访问时间取决于数据字在内存中的物理位置
无论是 SMP 还是 DSM 架构,线程间的通信均通过一个共享的地址空间来实现。这意味着只要具备相应的访问权限,任何处理器均可对任意内存位置进行寻址操作
这意味着只要具备相应的访问权限,任何处理器均可对任意内存位置进行寻址操作
1.2 Challenges of Parallel Processing
当处理器规模变得很大的时候,我们需要同步优化软件和硬件的所有层面。具体来说,我们主要会遇到以下两种挑战:
程序中有限的并行能力
相对高昂的通信开销,或者说并行处理器中远程访问的高延迟问题
Centralized Shared-Memory Architectures
有一些 和 SMP 有一定区别,访问具有不对称性:本地内存访问速度较快,而远程内存较慢
而 对称的共享内存机器通常支持对共享数据和私有数据的缓存
2.1 Multiprocessor Cache Coherence
高速缓存一致性问题(cache coherence problem):由于两个不同的处理器对内存的视图是通过各自的高速缓存建立的,因此这些处理器最终可能看到同一内存位置下的不同值。
一致性(coherence):规定了读操作可以返回哪些值
连贯性(consistency):决定了写操作的值何时能被读操作返回
2.2 Basic Schemes for Enforcing Coherence
多处理器引入硬件级协议来维护高速缓存的一致性。这个协议被称为高速缓存一致性协议(cache coherence protocols),其实现核心在于追踪数据块的共享状态。每个缓存块的状态通过与之关联的状态位来维护
基于目录
特定物理内存块的共享状态被保存在一个称为目录(directory) 的位置。
SMP: 集中式目录 ; DSM: 分布式目录
监听(snooping)
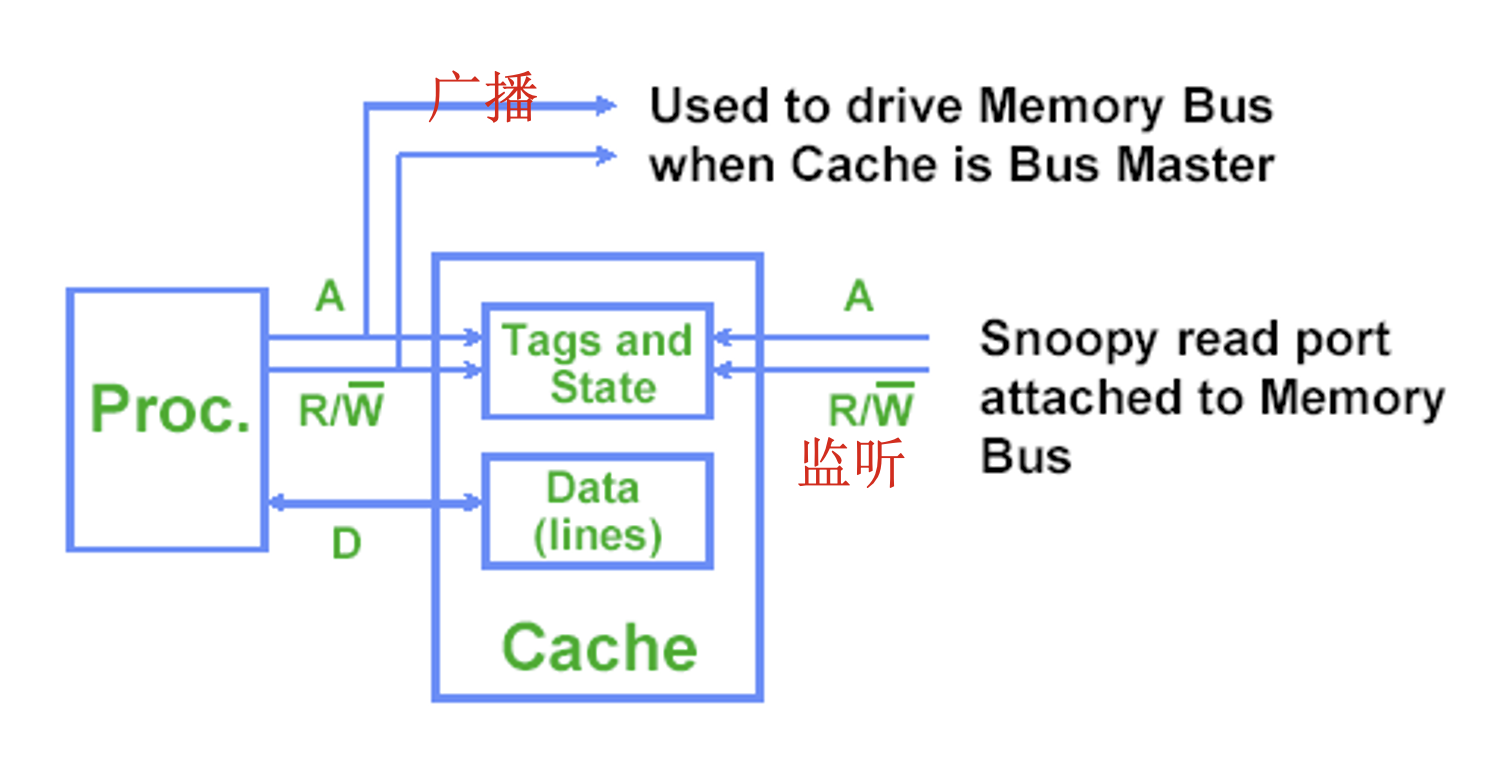
每个持有物理内存块数据拷贝的高速缓存均可追踪该块的共享状态
在 SMP 中,各个核心的高速缓存通常通过广播介质(如核心自带的高速缓存与共享高速缓存 / 内存之间的总线)实现互通,并且所有的高速缓存控制器通过持续监控或监听(snoop) 介质,以确认自身是否拥有在总线上,或交换访问中请求的目标数据块拷贝
2.3 Snooping Coherence Protocols
保持一致性要求有两种方法
写无效协议(write invalidate protocol):确保处理器在写入数据项前拥有对该项的独占访问权
独占访问能保证执行写入操作时不存在任何其他可读或可写的副本:该项数据的所有其他高速缓存的拷贝均会被置为无效状态
写更新(write update)/写广播(write broadcast) 协议:在写入数据项时更新该数据项的所有缓存拷贝
消耗更多的带宽
2.3.1 Basic Implementation Techniques
在多核处理器中,实现无效协议的关键在于利用总线或其他广播媒介来执行无效操作。
该机制的一个重要含义是:在获得总线访问权之前,对共享数据项的写操作实际上无法完成。
我们还需在发生高速缓存失效时定位数据项
在写穿式(write-through) 高速缓存中,查找数据项的当前值较为简单,因为所有已写入的数据都会立即发送至内存,从中总能获取到数据项的最新值。
写回式(✔🌭我们后续使用的,因为消耗带宽小),可以对高速缓存失效和写入操作采用相同的监听机制
每个处理器都会监听共享总线上传输的所有地址。
当某处理器发现自己持有目标缓存块的脏拷贝时,会将该缓存块作为读请求的响应内容返回,并终止对主存(或三级高速缓存)的访问。
该方法的复杂性在于需要从其他处理器的私有高速缓存(L1 或 L2)中获取目标块,这通常比访问三级高级缓存耗时更长。
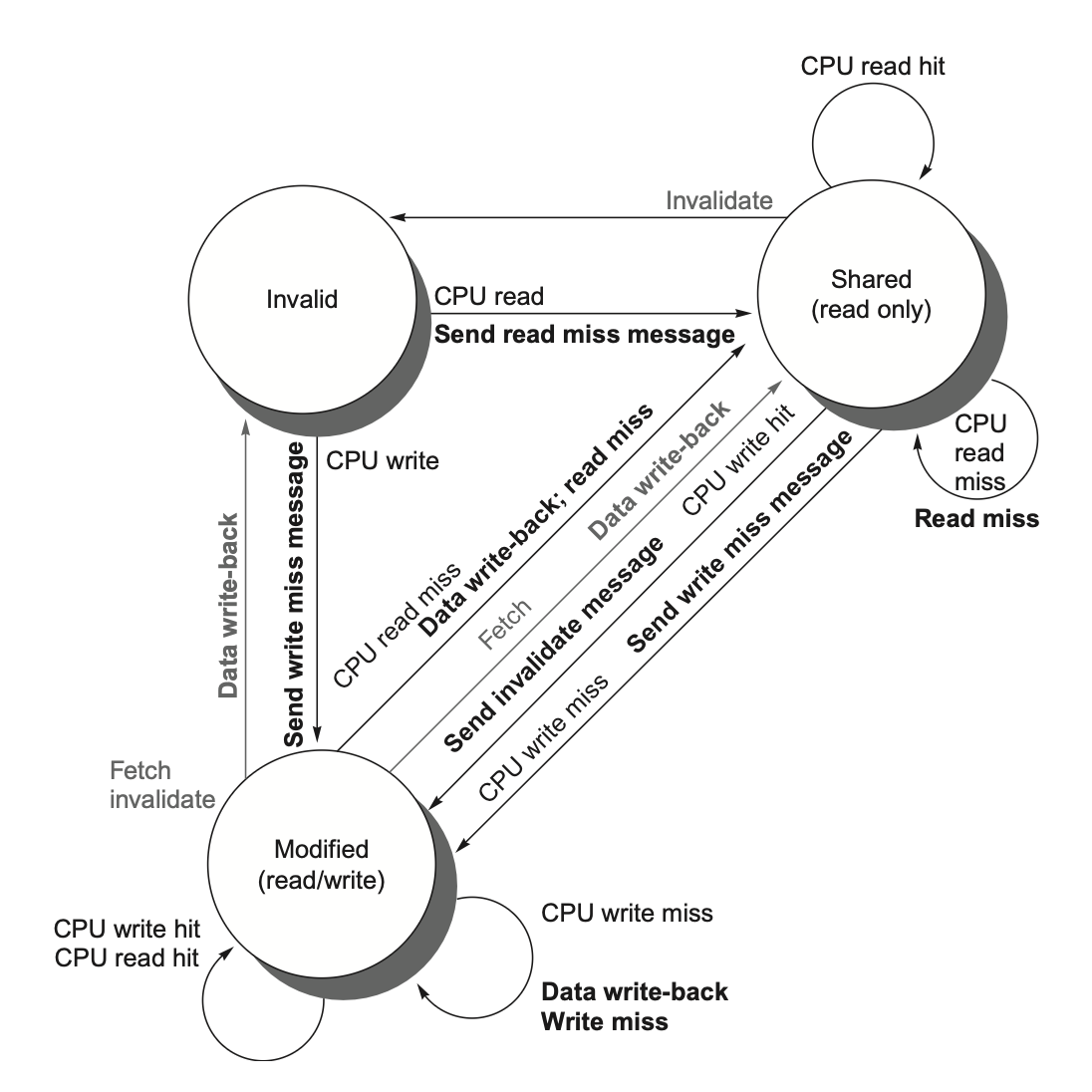
2.3.2 A Simple Protocol
我们一般通过为每个核中集成一个有限状态控制器来实现监听式一致性协议
协议包含三种状态:
无效(invalid)
共享(shared):表示私有高速缓存中的块可能被多个核共享
修改(modified):表明某个块已在私有高速缓存中被更新;并且该状态意味着该块具有独占性。
左图是我(CPU)内部以及对总线的请求,右图是总线对我(CPU)的请求以及我的状态变化
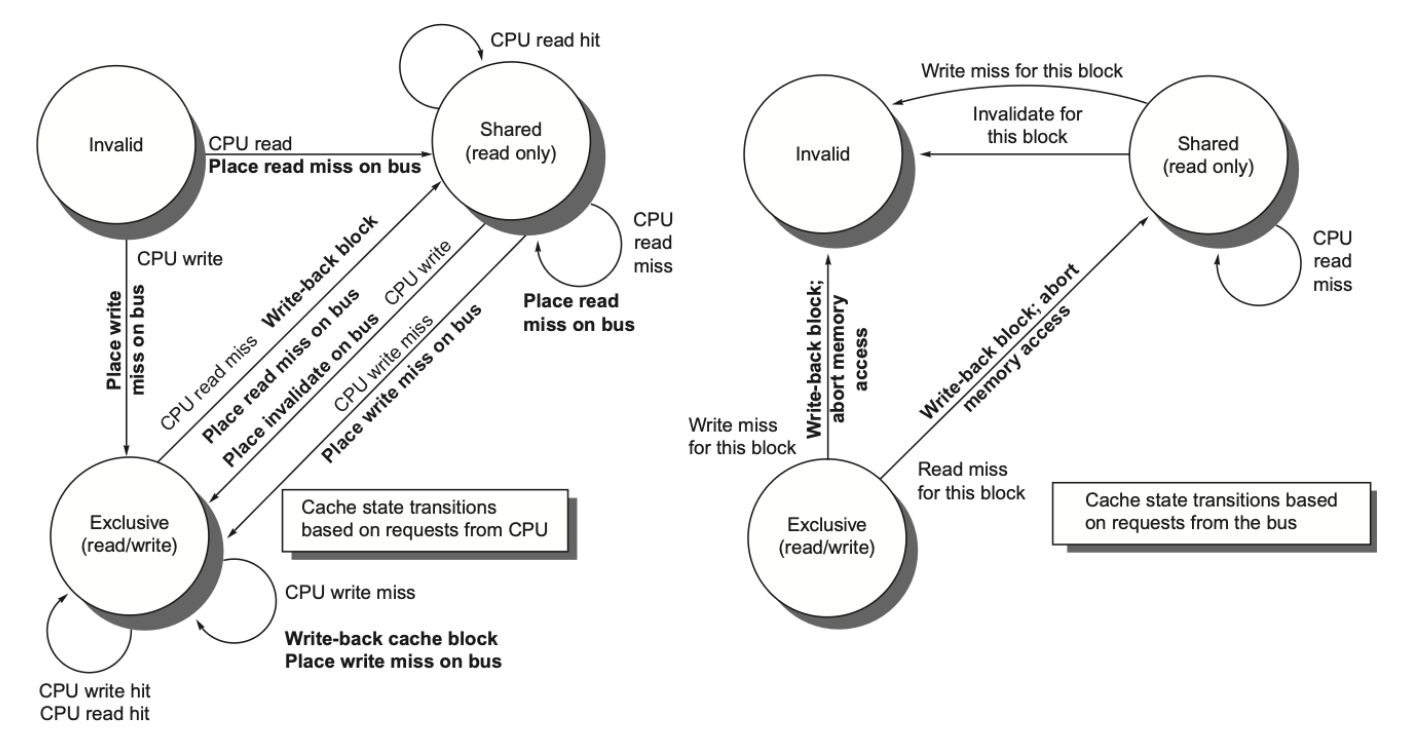
总线也在表格中单独列出来
2.4 Extensions to the Basic Coherence Protols
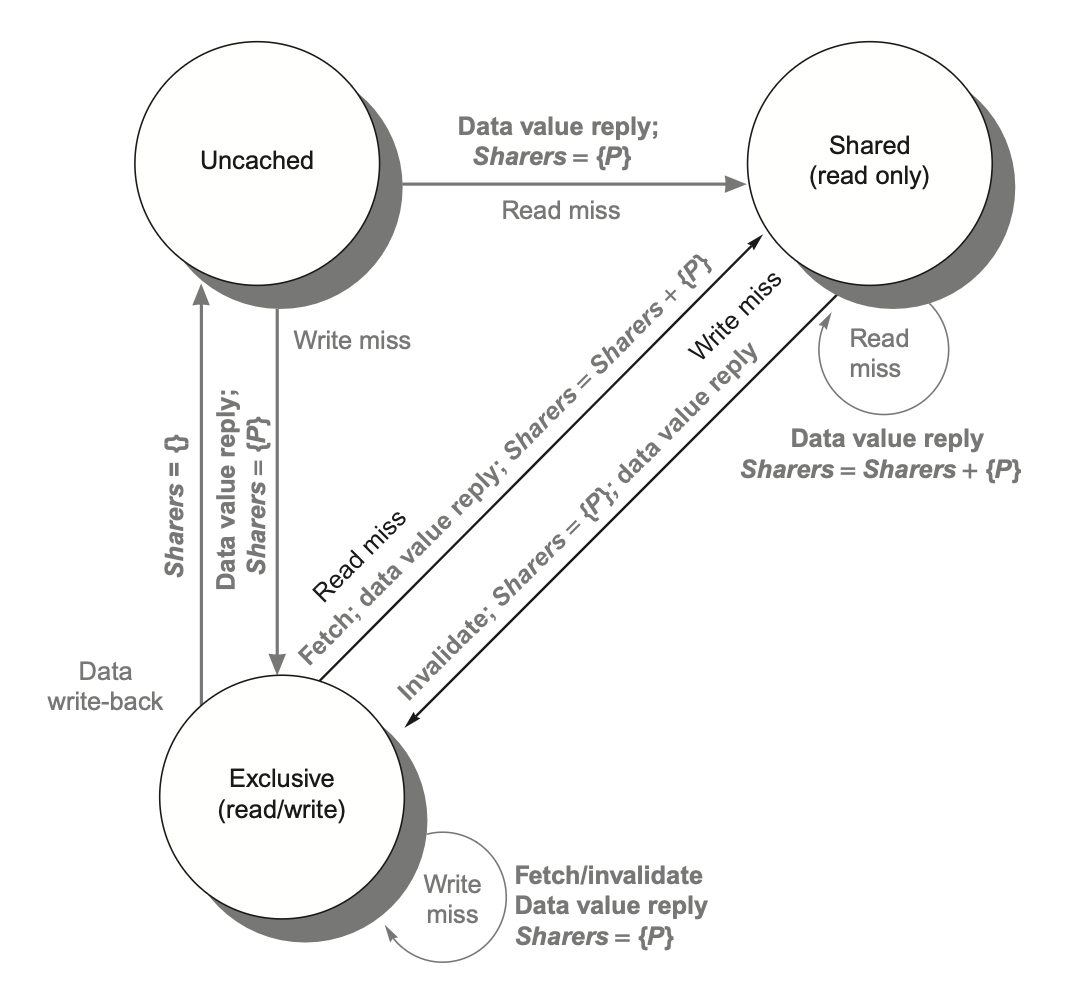
MESI 协议:增加了独占(exclusive) 状态
当同一个核再次写入处于独占状态的数据块时,既不需要获取总线访问权,也不需生成失效信号,因为系统明确知晓该数据块仅存在于本地的这个高速缓存中;处理器只需将其状态改为已修改即可实现更新。
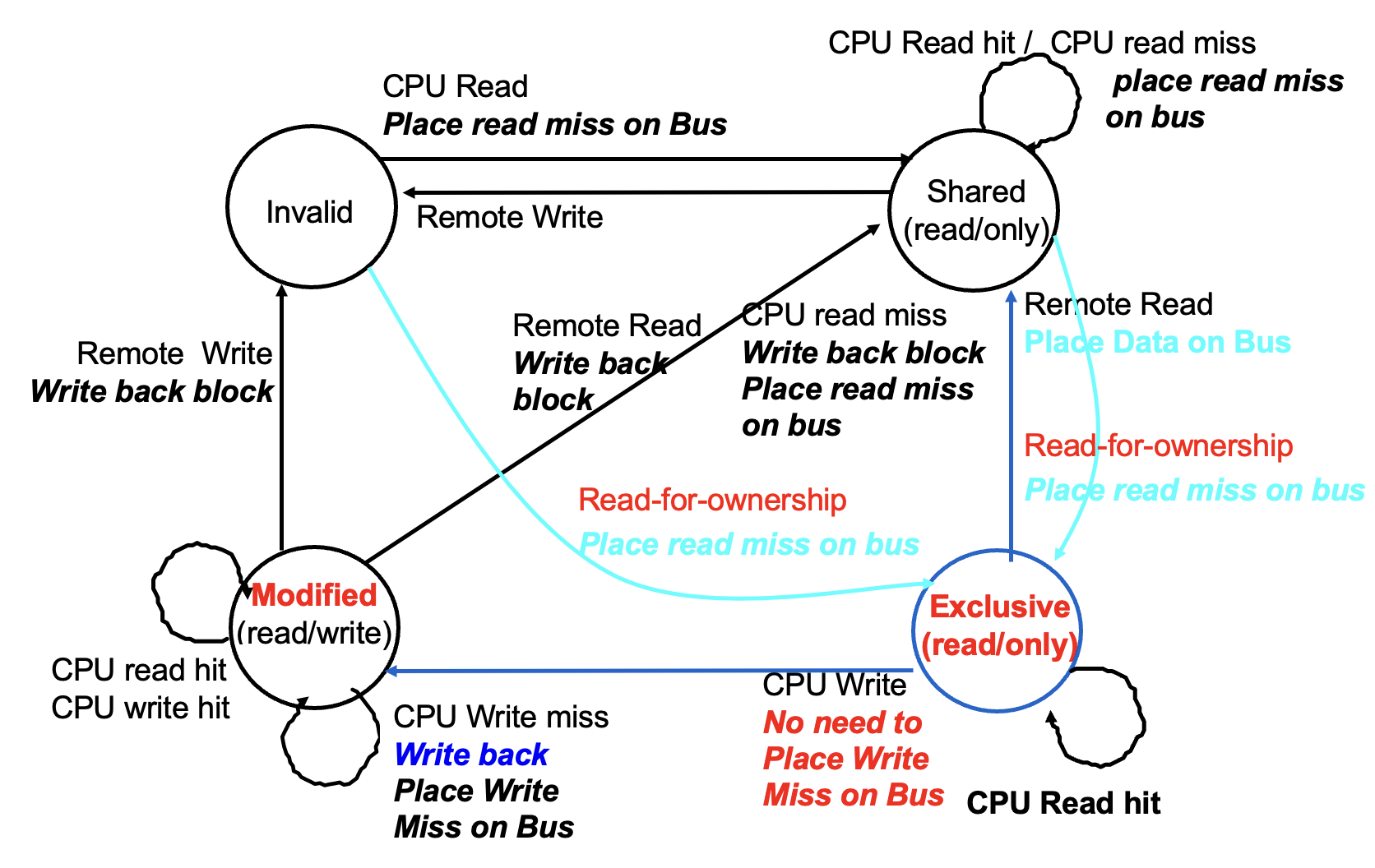
MOESI协议:在 MESI 协议的基础上增加了拥有(owned) 状态
而在 MOESI 协议中,原高速缓存的修改状态可以直接转换为拥有状态而无需立即写入内存。其他新的共享该块的高速缓存则保持共享状态;而仅由原高速缓存持有的拥有状态表明主存拷贝已失效,且指定高速缓存是所有者。
当发生失效时,所有者必须提供该数据块(因为主存未更新);若被替换,则需将其写回主存。
2.5 Limitations in SMPs and Snooping Protocols
监听式高速缓存的带宽也可能是一个限制,因为每个高速缓存都必须检查每一次的失效情况,下面给出一些增加监听带宽的技术
复制标签位
可在最外层的共享高速缓存层(如 L3)设置一个目录。
引入目录结构后,无需广播至所有 L2 缓存,仅需查询目录指向的可能持有数据块拷贝的特定 L2 即可。
2.6 Implementing Snooping Cache Coherence
Distributed Shared-Memory and Directory-Based Coherence
最简单的目录实现方式是:为每个内存块在目录中关联一个条目。
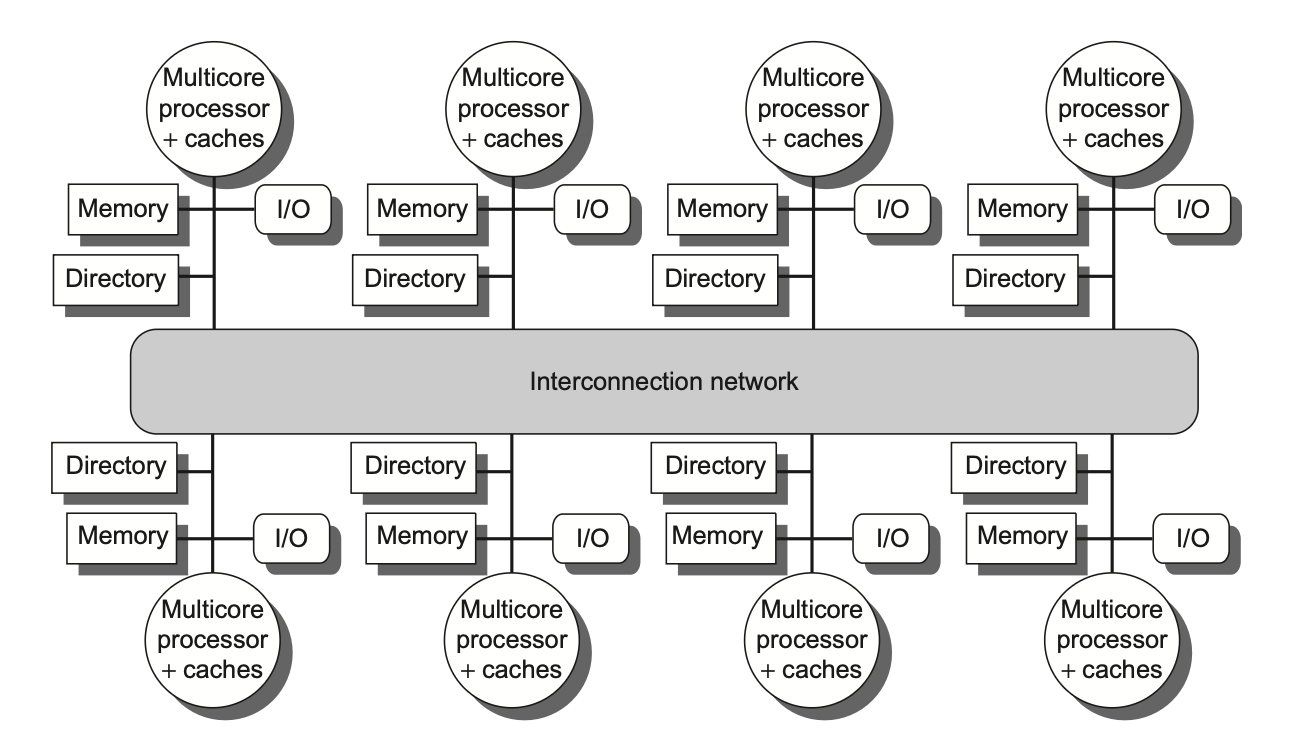
3.1 Directory-Based Cache Coherence Protocols
目录需要追踪每个高速缓存块的状态。具体有以下几类状态:
共享:一个或多个节点缓存了该数据块,且内存中的数值与所有缓存副本保持同步更新
未缓存(uncached):没有任何节点持有该缓存块的副本
已修改(modified):只有一个节点持有该数据块副本,且已执行过写操作,因此内存中的对应副本失效;此时该处理器被称为此数据块的所有者(owner)
为每个内存块维护一个位向量。当内存块处于共享状态时,向量的每一位表示对应的处理器芯片是否持有该块的副本。当内存块处于独占状态时,我们同样可以利用这个位向量来追踪其所有者
各高速缓存中状态机的状态与转换机制与之前采用的监听式高速缓存方案完全一致。
而数据项的无效化处理及独占副本的定位操作则存在显著区别:这两种操作都需要请求节点与目录之间、目录与一个或多个远程节点之间进行通信;而在监听协议中,这两个步骤是通过向所有节点广播一起完成的。
为了追踪持有高速缓存块副本的节点集合,我们使用名为共享者(Sharers) 的位向量来实现这一功能。目录请求需要更新共享者,并通过读取该集合执行无效化操作。
shares 里的内容是 该数据有哪些 processors 共享了
Synchronization
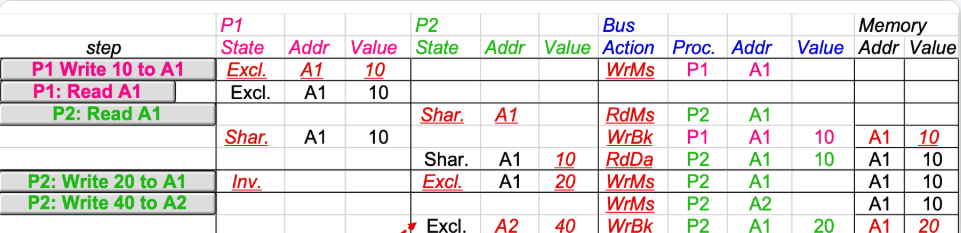
同步(synchronization) 机制通常由用户级的软件例程构建,这些例程依赖于硬件提供的同步指令。对于较小规模的多处理器系统或低竞争场景,关键的硬件能力在于提供一条不可中断的指令或指令序列,该指令能够以原子方式检索并修改数值。基于这一能力,便可构建出软件同步机制。本节重点探讨加锁与解锁这两类同步操作的实现原理;通过这两个操作,既能实现互斥访问控制,也可为更复杂的同步机制奠定基础。
4.1 Basic Hardware Primitives
一组能够实现原子化读取并修改内存位置的硬件原语
1. 原子交换(atomic exchange),用于将寄存器中的值与内存中的值进行互换。
成功路径:
交换前
*lock_addr为 0,寄存器是 1交换后
*lock_addr为 1(被占用),寄存器得到旧值 0返回值 0 → 调用者知道自己“锁”到了
失败路径:
交换前
*lock_addr已是 1交换后寄存器得到旧值 1
返回值 1 → 说明别人已经占用,需自旋/睡眠重试
int acquire_lock(int *lock_addr) {
register int reg = 1; // 想把 1 写进锁变量
int old = xchg(®, lock_addr); // 原子交换:reg↔*lock_addr
return old; // old==0 ⇒ 成功获取锁;old==1 ⇒ 失败
}2. 另一种类型的硬件原语是使用一对指令; 在 RISC-V 中,这对指令包括一种特殊的加载操作(称为保留加载(load reserved))
lr和一种特殊的存储操作(称为条件存储(store conditional))sc。
try:
mov x3, x4 ; mov exchange value
lr x2, x1 ; load reserved from
sc x3, 0(x1) ; store conditional
bnez x3, try ; branch store fails
mov x4, x2 ; put load value in x4只有当 lr(保留加载) 和 sc(条件存储) 中间 没有人对 *x1 写入,x3才为0
用保留寄存器(reversed register) 中跟踪
lr指令指定的地址
4.2 Implementing Locks Using Coherence
一旦有了原子操作后,便可以利用多处理器的一致性机制来实现自旋锁(spin lock)。
addi x2, R0, #1 ; x2 ← 1,准备写入锁
lockit:
EXCH x2, 0(x1) ; 原子交换:x2 ↔ (*x1)
bnez x2, lockit ; 如果旧值 ≠0,则锁已被占用 → 继续自旋
自旋锁会让处理器陷入等待释放的循环中占用资源,因此在某些场景下并不适用。
“缓存锁 (caching lock)”——也叫 test-test-and-set 自旋锁。
先用纯读操作忙等,只在确实看到锁已空闲时才发起一次真正的“原子交换”去争抢。这样可以把 99 %的时间都停留在各自处理器的 本地缓存 里,显著降低总线 / 缓存一致性流量。
lockit: ld x2, 0(x1) ; 1) 读锁值到 x2
bnez x2, lockit ; 2) 如果 ≠0 → 锁未释放,继续忙等
addi x2, R0, #1 ; 3) 准备抢锁,把 1 放进 x2
EXCH x2, 0(x1) ; 4) 原子交换 x2 ↔ (*x1)
bnez x2, lockit ; 5) 交换失败?有人捷足先登 → 重来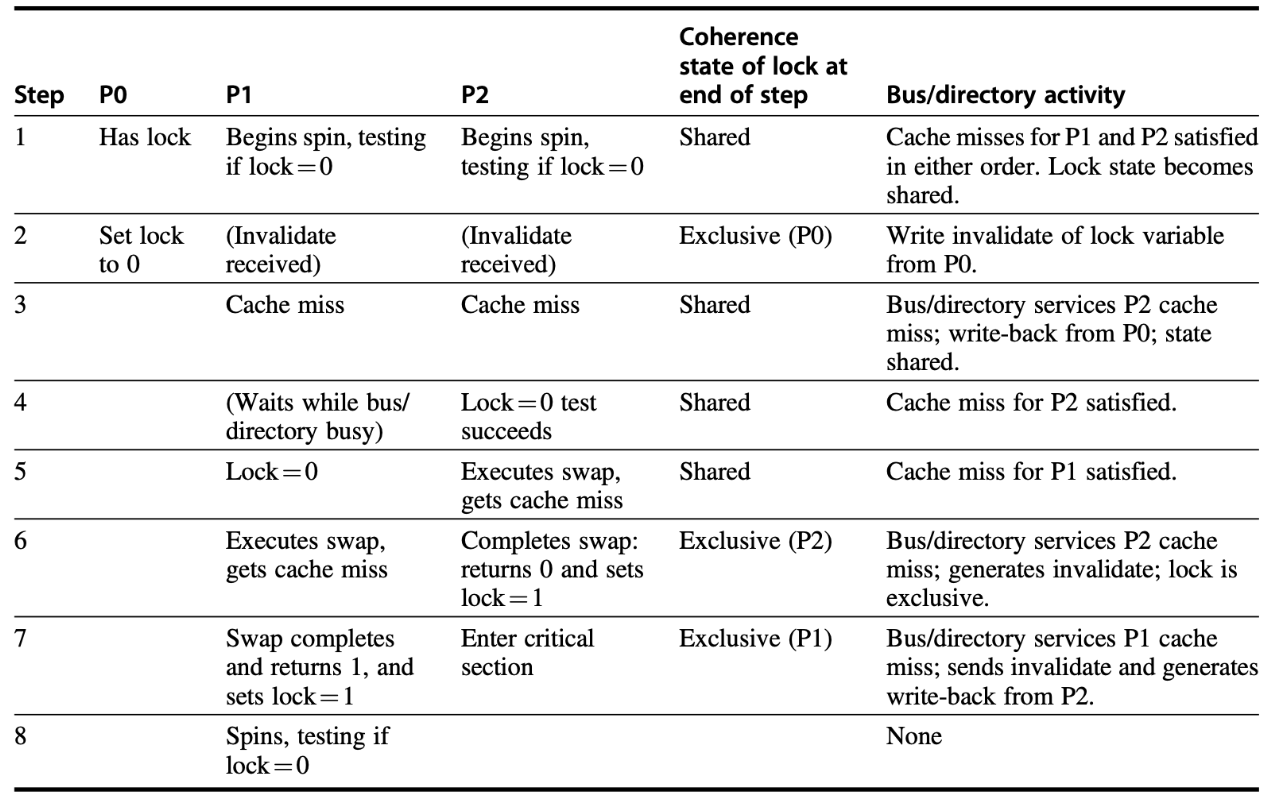
解锁 (= 写 0) 会触发一次广播失效
持锁者把行从 Shared 升到 Exclusive 并写入 0,其余核的副本立即作废 → 这保证它们下一次读到的就是新值。谁先拿到 0,不一定就是最终赢家
P2 第一个读到 0,但真正获锁要等它的
swap请求再把行升级为 Exclusive。如果在它升级前别的核(这里是 P1)抢先发 RFO 并赢得仲裁,就会“反超”成功加锁。
因此 总线仲裁顺序 + 目录响应延迟 决定最终谁获锁。
失败者的后果
失去独占权限 (收到 invalidate) 后,swap返回旧值 1 ⇒ 知道自己失败,只能回到“测试-自旋”阶段。缓存锁减少总线风暴,但仍有两次写失效
相比“每次循环都做swap”的朴素自旋锁,这里只有:一次失效:释放锁时写 0
一次失效:赢家把 0 ↦ 1
其余时间各自都在本地缓存里自旋,对总线很友好。就比如第一步里面都是shared的
4.3 Barrier Synchronization
{
lock(counterlock); // ensure update atomic
if (count == 0) release = 0; // first-->reset release
++count; // count arrivals
if (count == total){ // all arrived
count = 0; // reset counter
release = 1; // release processes
}
unlock(counterlock); // release lock
spin(release == 1) ; // wait for arrivals
}Models of Memory Consistency
P1
P1: A = 0;
......
A = 1;
L1: if (B == 0) ...P2
P2: B = 0;
......
B = 1;
L2: if (A == 0) ...假设写失效操作被延迟,并且允许处理器在此延迟期间继续执行; 那么两个IF 将会被同时满足
通过硬件和软件实现顺序一致性:一些系统采用硬件级的加速来确保内存访问的顺序一致性,同时使用软件的同步机制(如锁、条件变量等)来保证不同线程/处理器之间的协调。
下图展示了各类连贯性模型对一般访问和同步访问顺序的约束
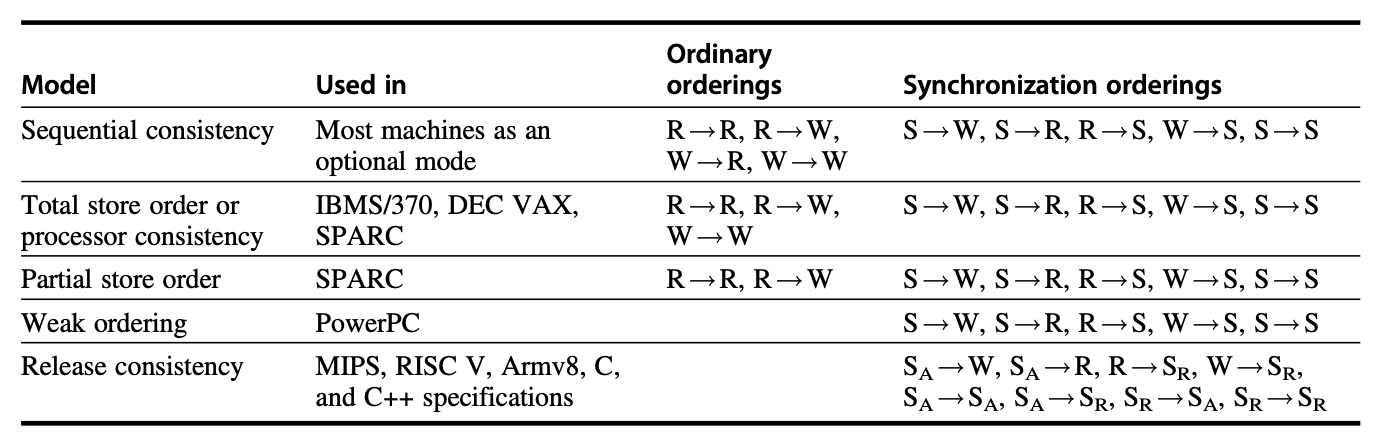
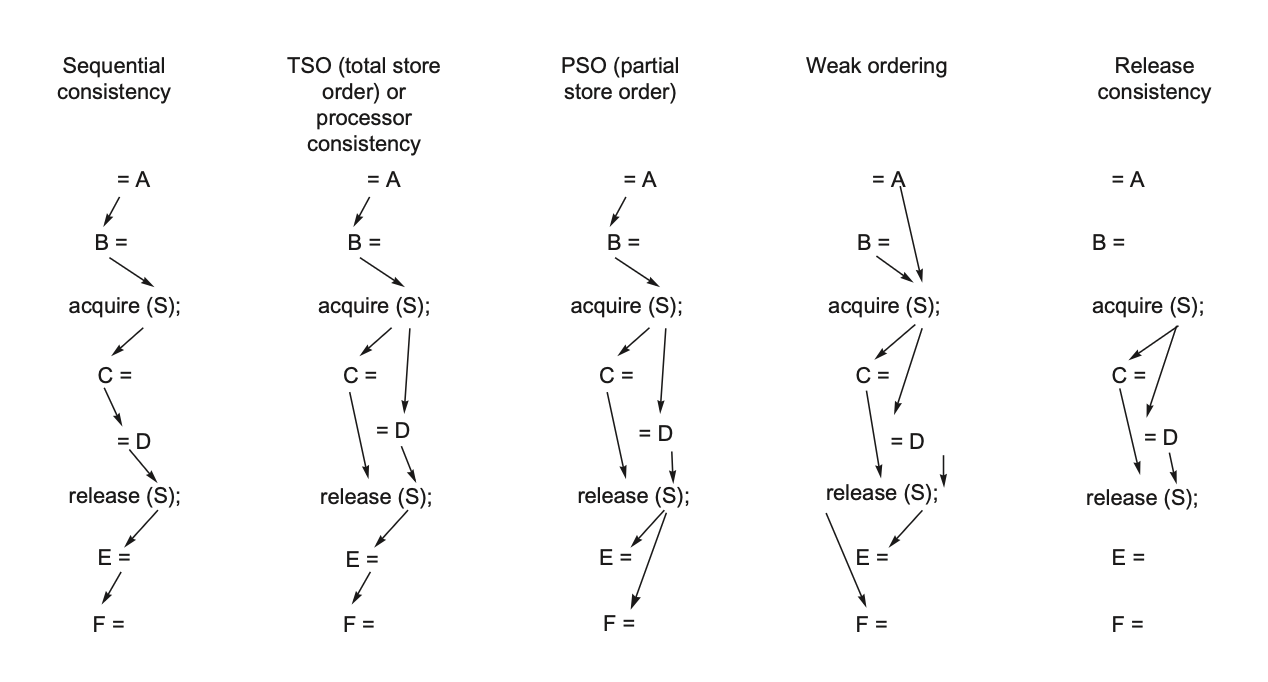
区分 , coherence:若某个处理器能持续读取到过时的数据值,那么显然可以判定该内存处在不一致的状态。
coherence 需要 自己能读到自己写的,自己能读到别人写的最新值
A4 应该特别注意
Cache
AMAT和平均停顿时间 要区分开来 ,后者的第一级的hit时间不必算上
ILP
托马斯洛三种
普通的scoreboard解决 waw 在发射前,写入结果检查WAR,写入结果的下两周期才能进行RAW以来指令的EXE;托马斯洛和硬件调度 在WAW WAR 运用了重命名, EX做完总线广播到另一条有RAW依赖的EX之间差一个周期
精确异常(Precise Exception)会严格保证异常点的指令上下文完全可重现。现代处理器通常通过检查点恢复(类似数据库系统的 ARIES 算法)或重排序缓冲区(ROB)等机制将不精确异常转化为精确异常处理。
-
TLP
coherence and consistency
同步访问顺序
2022题目
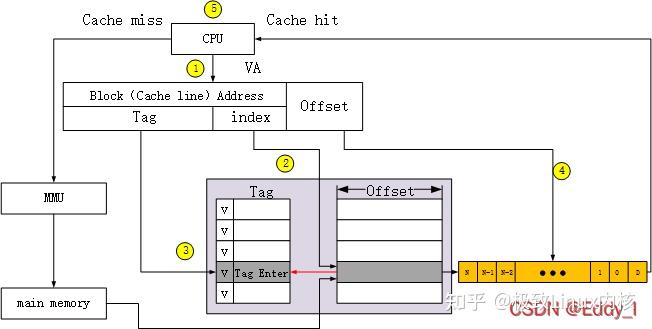
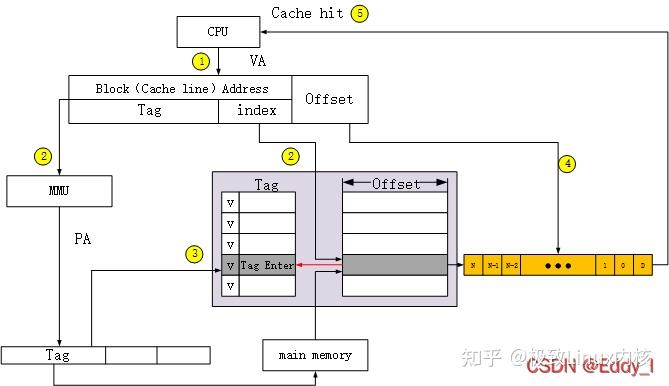
T1 VIVT 和 VIPT

这种题目直接考虑物理地址那块就行了,虚拟地址仿佛都没怎么用到计算
VIVT 和 VIPT 对于 pageoffset的处理都是一样的,都是直接转化为block offset和byte offset; (1 封私信 / 6 条消息) Cache的组织形式(VIVT、VIPT、PIPT) - 知乎
这是VIVT,virtual index和virtual tag 不经处理直接去索引数据
VIPT, Tag要经过转换
T2 snooping

C正确:写失效由于让其他块失效了,所以下一次读会miss一次;而写更新不会让其他已经持有此块的processor失效化
2023 年题目
T1
ISA 的类别
栈架构(stack architecture)
累加器架构(accumulator architecture)
通用目的寄存器架构(general-purpose register architecture, GRA)
寄存器 - 内存架构 任何指令都能访问内存 只要另一操作数在寄存器里即可
(下图中直接把B取出来相加)
加载 - 存储架构 只有加载和存储指令才能访问内存
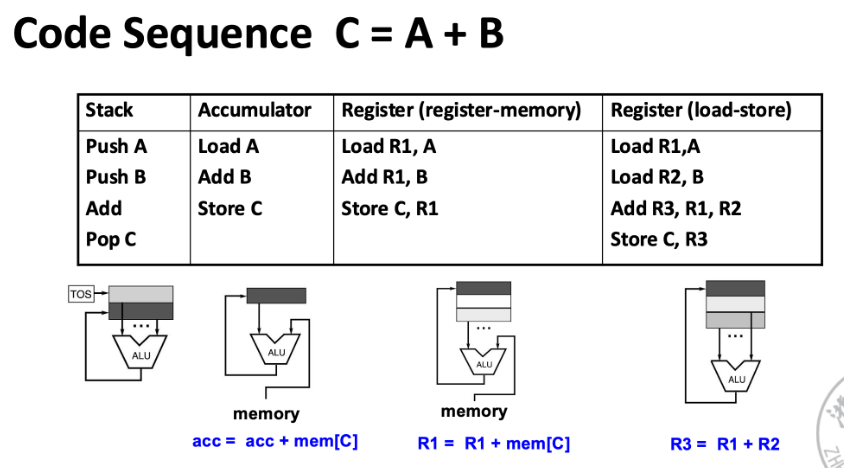
T2
Double-bump
把一个时钟周期拆成 两个半拍:① 前半拍写回结果 ② 后半拍读取源寄存器
上一条指令刚写回的寄存器,当周期内下一条就能读到 → 消掉 1 拍 RAW 等待;同时避免“读/写端口冲突”结构冒险
T3
NUMA 中

"家节点"就是多核中单个核对应的内存 , 一个核对应一块内存,对应一个shares表
2021 年
T1
CSR 总览

T2
三个概念

改进后的“缓存锁”已经把写流量降到了最低可接受水平,但在高并发瞬间竞争时,仍会出现“所有线程一起写一次”的失效冲击;而 LR/SC 自旋锁完全消除失败写,所以在核数多、锁粒度小的应用上性能还是更好。
在核数少或锁竞争不激烈的场景,两者表现几乎一样。
T3 Write back 和 allocate 下 ,L1,L2 的“懒惰”传递



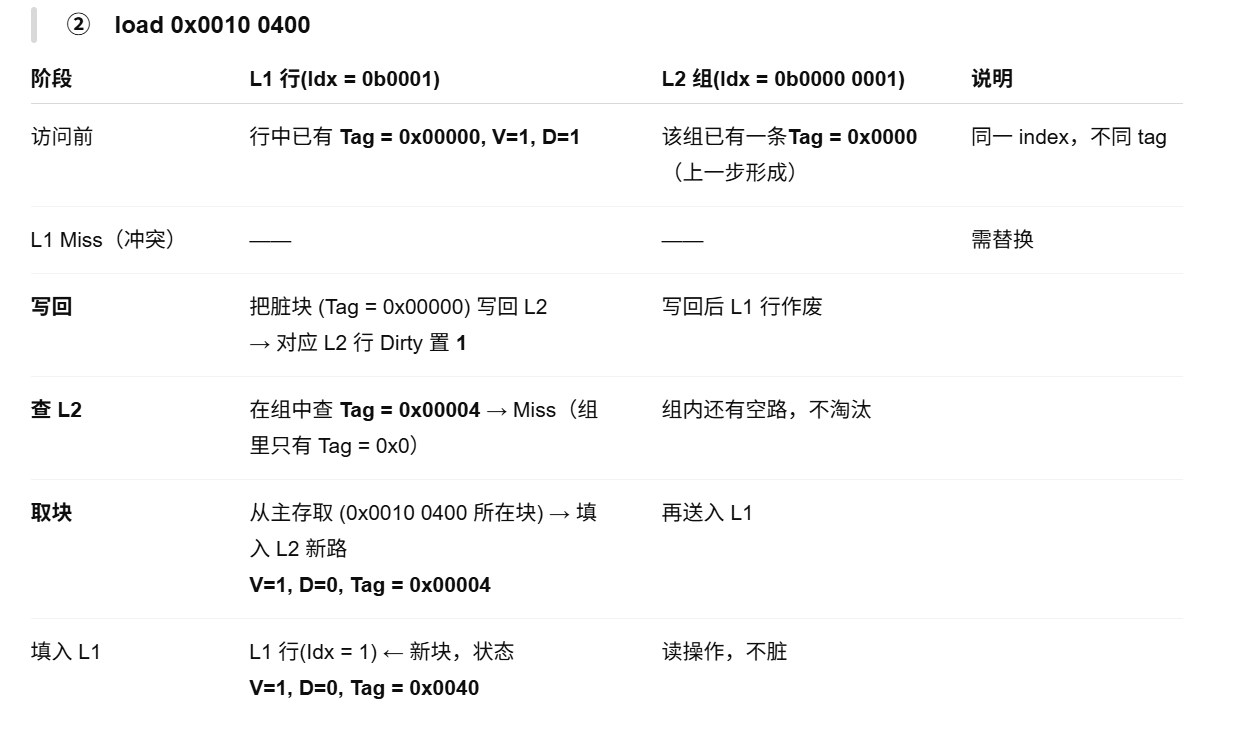
Already Done
Ex2.1 AMAT要先计算 该 内存 操作 的占比

Ex2.3 “Unified的一千条指令中的miss比率还要除以1.36,是为了算出每种miss 的占比”

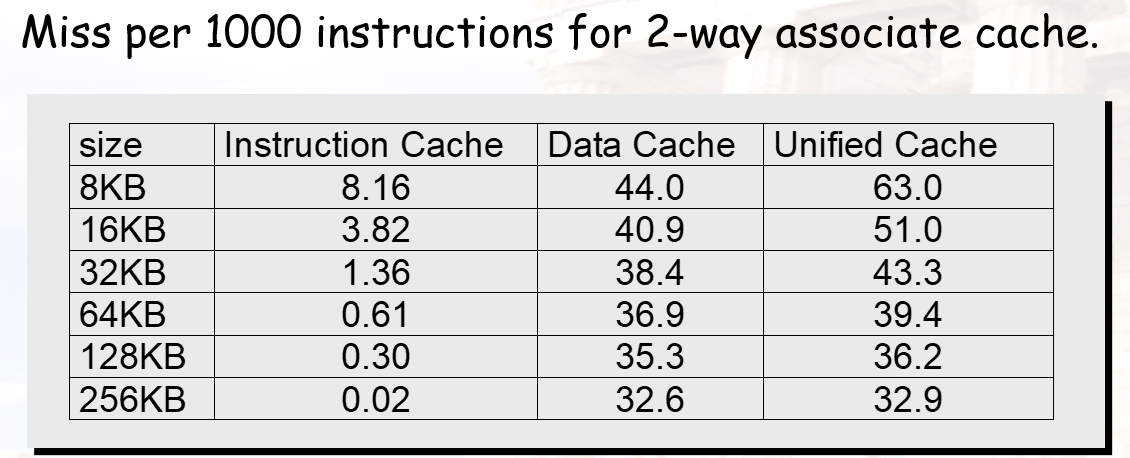



ex2.4 有缓存时用cachemiss 和 missrate 算是一样的,没缓存的话是 1 + 100*1.5
