
Chapter2 :Operating -System Structures
2.1 操作系统服务 (Operating-System Services)
操作系统为程序的执行提供了一个环境,并向程序和用户提供了一系列服务。这些服务可以大致分为以下几类
用户界面
程序执行 (Program Execution): 操作系统必须能够将程序加载到内存中并运行它,以及正常或异常地终止程序。
I/O 操作 (I/O Operations)
文件系统操作 (File-System Manipulation)
通信 (Communications)
可以在同一台计算机上的进程之间进行,也可以在网络上不同计算机的进程之间进行。主要方式有share memory和message bypassing。
错误检测
资源分配
日志 (Logging)
保护与安全 (Protection and Security)
确保对系统资源的访问是受控的(保护),并保护系统免受外部或内部的恶意攻击(安全)
2.2 用户与操作系统接口 (User and Operating-System Interface)
用户主要通过以下几种接口与操作系统进行交互
CLI, GUI, Touch-Screen Interface
2.3 系统调用 (System Calls)
定义: 系统调用为操作系统提供的服务提供了编程接口
当一个程序需要操作系统的服务时(例如,读取文件),它会执行一个系统调用,将控制权和请求传递给操作系统。操作系统完成任务后,再将控制权交还给程序
应用程序编程接口 (API):
在实际编程中,程序员通常不直接编写系统调用代码。
他们使用更高级的 API(例如 POSIX API, Windows API)。
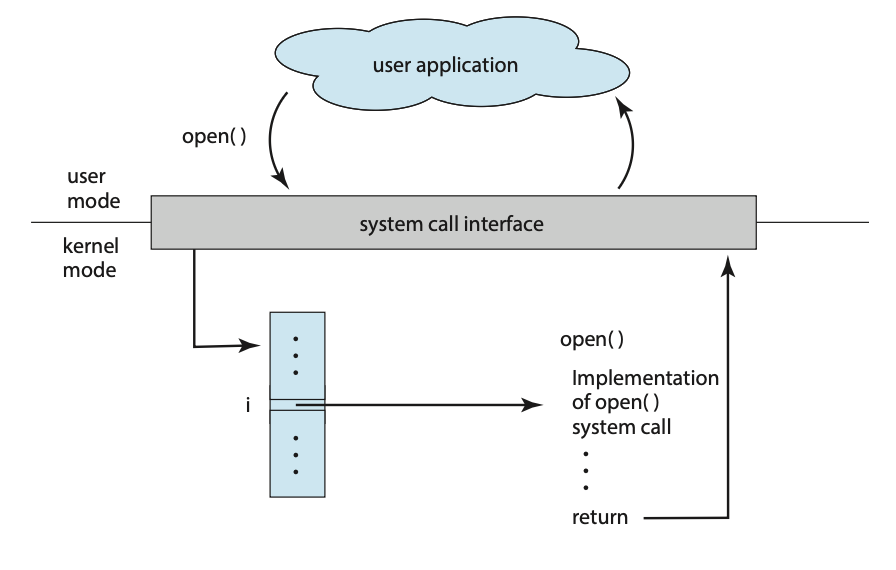
图中展示了一个用户应用程序从用户模式(user mode)通过系统调用接口调用open()函数。进入内核模式(kernel mode)后,接口通过一个索引 i 在系统调用表中查找并执行open()系统调用的具体实现,然后返回结果。
如何将参数传递给操作系统
pass the parameters in registers.
block method , 将参数存储在内存的一个块或表中,然后将该块的地址作为一个参数在寄存器中传递
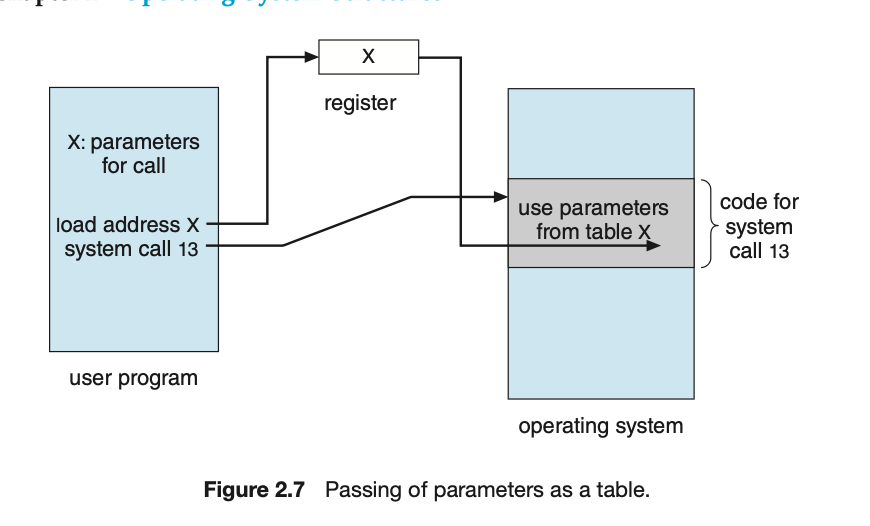
stack method
系统调用的类型 (Types of System Calls)
进程控制 (process control)、文件管理 (file management)、设备管理 (device management)、信息维护 (information maintenance)、通信 (communications) 和 保护 (protection)
2.7 Operating-System Design and Implementation
机制与策略 (Mechanisms and Policies)
策略和机制的分离对于灵活性非常重要。策略可能会随着地点的变化或时间的推移而改变。在最坏的情况下,对策略的每次更改都需要重新修改底层机制。一个通用的机制应该足够灵活,以适应各种策略。如果策略改变,人们只需要重新定义某些参数即可
基于微内核的操作系统(在2.8.3节讨论)将机制和策略的分离推向了极致,它通过实现一组非常基础的构建块来实现。这些块几乎没有策略,允许更高级的机制和策略通过用户创建的内核模块被添加进来。
相比之下,商业操作系统Windows,在三十多年的发展中,将机制和策略紧密地结合在一起。微软一直将策略强制应用于整个系统,并跨所有使用Windows操作系统的设备。所有应用程序都有相似的界面,因为界面本身是内置在内核和系统库中的。苹果公司为其macOS和iOS操作系统采取了类似的策略。
2.8 Operating-System Structure
2.8.1 单体结构 (Monolithic Structure)
组织操作系统的最简单结构就是根本没有结构。也就是说,内核的所有功能都被放置在一个地址空间中的单个静态二进制文件中
这种有限结构的一个例子是最初的UNIX操作系统,它由两部分组成:内核和系统程序。内核被进一步分离为一系列与硬件交互的接口和设备驱动程序。
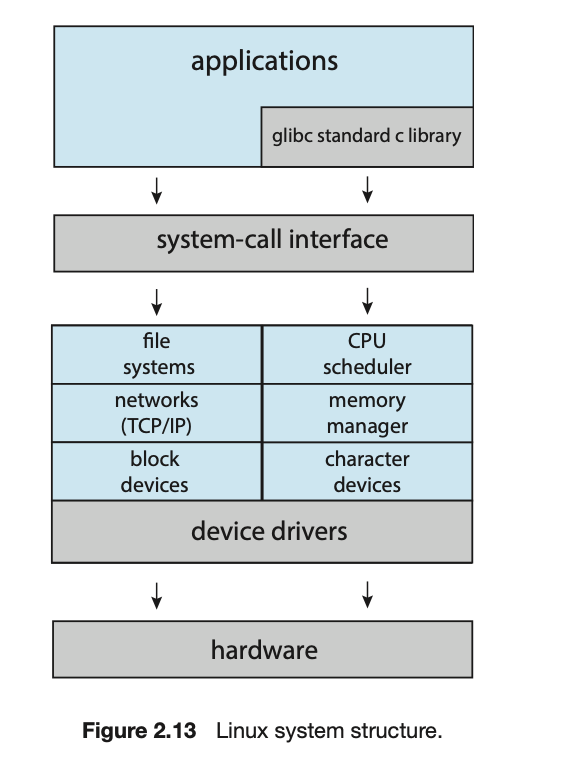
尽管实现了单体内核的简单性,但它们很难实现和扩展。尽管如此,单体内核确实有一个明显的性能优势:系统调用接口和内核内的通信开销很小,因此单体内核的速度和效率解释了为什么它们仍然在UNIX、Linux和Windows操作系统中
2.8.2 分层方法 (Layered Approach)
单体方法通常被称为一个**紧密耦合(tightly coupled)的系统,因为一个组件的改变可能会对系统的其他部分产生广泛的影响。我们可以设计一个松散耦合(loosely coupled)**的系统。这样一个系统被划分为独立的、更小的组件,这些组件具有特定的、有限的功能。所有这些组件一起构成了内核。
一种方法是将操作系统分解成多个层次(层级)。底层(第0层)是硬件;最高层(第N层)是用户界面。
一个典型的操作系统层——比如说第M层——由数据结构和一系列例程组成,这些例程可以被更高层的层级(第M+1层)调用。第M层,相应地,可以调用更低层层级(第M-1层)的操作。
分层系统已经成功地应用于计算机网络(例如TCP/IP)和Web应用程序。然而,很少有操作系统使用纯粹的分层方法。一个原因在于定义每一层的适当功能所面临的挑战。此外,这种方法的整体性能很差,因为通过多层来请求一个操作系统服务会产生开销。一些操作系统在结构上比其他操作系统更分层。
2.8.3 微内核 (Microkernels)
这种方法通过从内核中移除所有非必需的组件,并将它们实现为用户级程序来构建操作系统
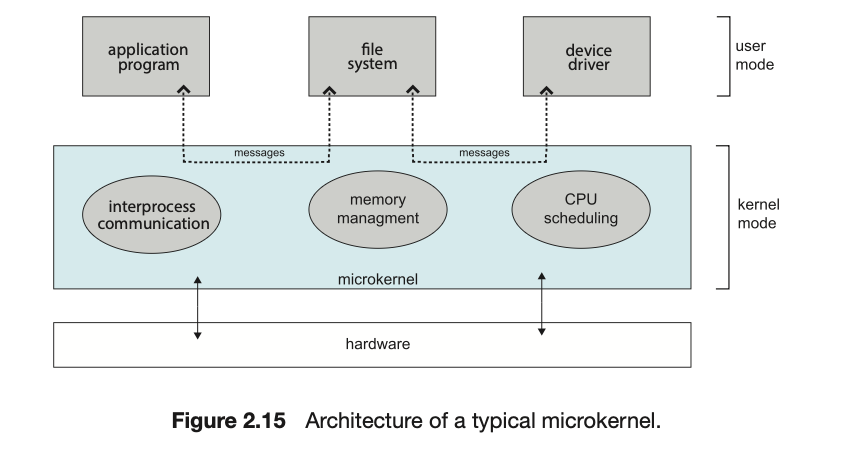
微内核的主要功能是提供客户端程序和在用户空间中运行的各种服务之间的通信。客户端程序和各种服务之间的通信是通过在2.3.3.5节中描述的消息传递进行的。例如,如果客户端程序希望访问一个文件,它必须与文件服务器进行交互。客户端程序和服务从不直接交互。它们通过与微内核交换消息来进行间接通信。
微内核方法的一个好处是它扩展了操作系统。所有新服务都是在用户空间添加的,因此不需要修改内核。当内核需要修改时,由于微内核是一个更小的内核,因此所需的更改往往较少。由此产生的操作系统也更容易从一种硬件架构移植到另一种。微内核还提供了更高的可靠性和安全性,因为大多数服务作为用户(而不是内核)进程运行。如果一个服务失败,操作系统的其余部分保持不受影响。
不幸的是,微内核的性能可能会因系统功能开销而受到影响。由于消息必须在用户空间中的服务和内核之间复制,因此通信开(销)会增加
2.8.4 模块 (Modules)
也许目前用于操作系统设计的最佳方法是使用可加载内核模块(loadable kernel modules, LKMs);让内核提供核心服务,而其他服务则在内核运行时动态实现
LKMs允许Linux拥有动态和模块化的特性,同时保持了单体系统的性能(通信等效率)。
2.8.5 混合系统 (Hybrid Systems)
在实践中,很少有操作系统采用单一、严格定义的结构。相反,它们结合了不同的结构,形成了解决性能、安全和可用性问题的混合系统。例如,Linux是单体的,因为将所有内容放在一个地址空间中提供了非常高效的性能。然而,它也是模块化的,所以可以动态地将新功能添加到内核中。
2.9 Building and Booting an Operating System
2.9.2 系统引导 (System Boot)
当一个操作系统生成后,它必须可供使用。它必须被安装在硬盘上,或者可以从硬盘上加载。但硬件如何知道内核在哪里,或者如何加载内核呢?加载内核的过程由存储在硬件固件中的一个小程序来处理,这个程序被称为自举程序(bootstrap program)或引导加载程序(boot loader)。在大多数系统上,引导过程如下:
自举程序或引导加载程序定位内核。
内核被加载到内存中并启动。
内核初始化硬件。
根文件系统被挂载。
一些计算机系统使用一个多阶段的引导过程。当计算机首次通电或重启时,一个位于固件(称为BIOS)中的小型引导加载程序boot loader会运行。这个初始引导加载程序通常只做一件事,即将第二个引导加载程序加载进来,而第二个引导加载程序位于磁盘上的固定位置,这个位置被称为引导块(boot block)。存储在引导块中的程序足以将整个操作系统加载到内存中并开始执行。通常,它是一个简单的代码(例如,它可能只是一个磁盘块的长度),它知道磁盘的地址和剩余引导程序的长度。
许多最近的计算机系统已经用**统一可扩展固件接口(Unified Extensible Firmware Interface, UEFI)**取代了基于BIOS的引导过程。UEFI有几个优势,包括比BIOS更好地支持64位系统和更大的磁盘。也许UEFI最大的优势是它是一个单一的、完整的引导管理器,因此比传统的BIOS引导过程更快。
无论从BIOS还是UEFI引导,引导程序都可以执行各种任务。除了加载程序到内存中,它还运行诊断程序来确定机器的状态——例如,检查内存和CPU。如果诊断通过,程序可以继续引导过程。引导程序还可以初始化系统的所有方面,从CPU寄存器到设备控制器和内存内容。只有到这时,它才会启动操作系统。对于操作系统来说,这个点就是挂载根文件系统(mount the root file system)。
2.10 Q&A
系统调用为操作系统提供的服务提供了接口。应用程序编程接口(API)用于访问系统调用
标准C库为UNIX和Linux系统提供了系统调用接口。
链接器将可重定位的目标模块组合成一个单一的二进制可执行文件。加载器将可执行文件加载到内存中,使其有资格在可用的CPU上运行。
Chapter3 : Processes
3.1 Concept
3.1.1 The process
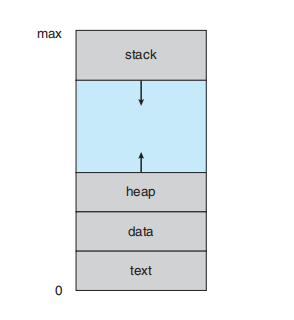
一个进程是一个正在执行的程序。一个进程的状态由 程序计数器(program counter)的值和处理器寄存器的内容来表示。进程的内存布局通常分为多个部分,如图3.1所示。这些部分包括:
文本段 (Text section) — 可执行代码
数据段 (Data section) — 全局变量

进程在内存地址空间中的布局。从低地址(0)到高地址(max)依次是:文本段(text),数据段(data),堆(heap)(向上增长),栈(stack)(向下增长)。
需要注意的是,文本和数据段的大小是固定的,而堆和栈段在程序执行期间可以动态地增长和收缩。每次调用函数时,一个 活动记录(activation record) 会被推送到栈中,其中包含函数的参数、局部变量和返回地址;当从函数返回时,这个活动记录会从栈中弹出。类似地,当通过
malloc()动态分配内存时,堆会增长;当通过free()释放内存时,堆会收缩。尽管栈和堆段是分开的,但它们朝对方增长。如果它们重叠,系统必须确保它们不会相互覆盖。
3.1.2 Process State

新建 (New): 进程正在被创建。
运行 (Running): 指令正在被执行。
等待 (Waiting): 进程正在等待某个事件的发生(例如I/O完成或收到一个信号)。
就绪 (Ready): 进程正在等待被分配给一个处理器。
3.1.3 进程控制块 (Process Control Block)
包含信息: 进程状态 (Process state) , 程序计数器 (Program counter) , CPU寄存器 (CPU registers) , CPU调度信息 (CPU-scheduling information) , 内存管理信息 (Memory-management information) , 记账信息 (Accounting information) , I/O状态信息 (I/O status information)
3.1.4 线程 (Threads)
允许一个进程拥有多个执行线程,从而可以一次执行多个任务。这一特性在多核系统上尤其有益,多个线程可以并行运行。在一个多线程的文字处理器上,例如,一个线程可以管理用户输入,而另一个线程可以运行拼写检查。在支持线程的系统上,PCB被扩展以包含每个线程的信息。其他变化也是必要的。
3.2 进程调度 (Process Scheduling)
多道程序设计(multi-processing, Time-sharing 本身就是种 multi-processing )的目标是在任何时候都有某个进程在运行,以最大化CPU的利用率。分时共享(Time Sharing)的目标是如此频繁地切换CPU核心,以便用户在程序运行时可以与之交互。为了实现这些目标,进程调度程序(process scheduler)从一组可用进程中为程序在一个CPU核心上的执行选择一个可用的进程。每个CPU核心一次可以运行一个进程。
对于一个单CPU核心的系统,任何时候都不会有超过一个进程在运行。然而,在一个多核系统上,可以同时运行多个进程。如果进程比核心多,多余的进程将不得不等待,直到一个核心空闲出来并可以被重新调度。
大多数进程可以被描述为I/O密集型或CPU密集型。一个I/O密集型进程(I/O-bound process)**是那种花在I/O上的时间比花在计算上的时间多的进程。
3.2.1 调度队列 (Scheduling Queues)
当进程进入系统时,它们被放入一个 就绪队列(ready queue) 中。它们在这个队列中等待,直到被选中在一个CPU核心上执行。这个队列通常存储为一个链表。就绪队列的头部包含指向链表中第一个PCB的指针,每个PCB都包含一个指向就绪队列中下一个PCB的指针。
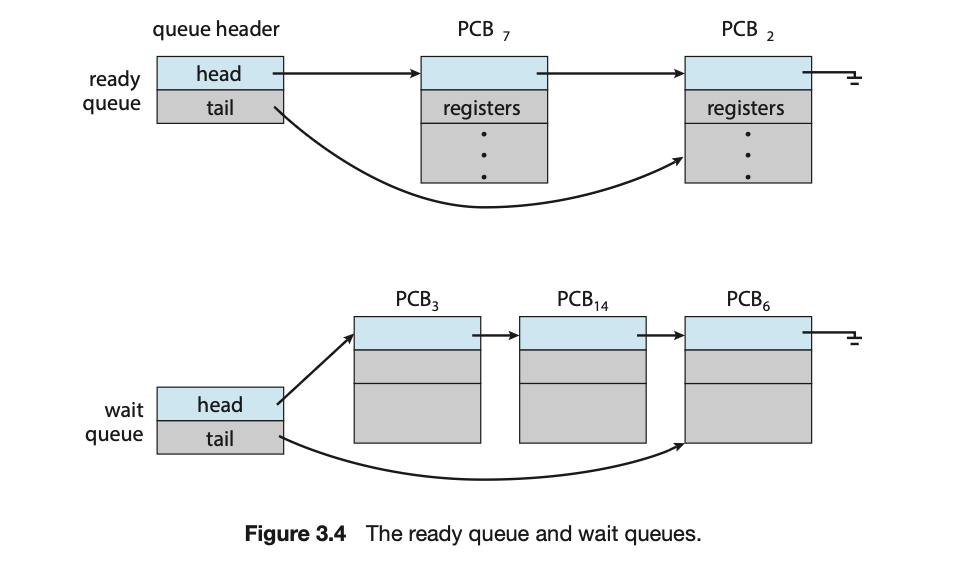
系统中还存在其他队列。当一个进程被分配给一个CPU核心并正在执行时,它可能会发出一个I/O请求,然后被放入一个I/O等待队列中。当一个进程因为特定事件(例如I/O请求完成)而等待时,它会被中断。假设一个系统有一个专用的磁盘驱动器,那么它会有一个等待该磁盘驱动器的进程队列。因此,每个设备都有自己的设备队列。

进程调度的常见表示是排队图(queuing diagram),如图3.5所示。每个矩形框代表一个队列。两种类型的队列是就绪队列和一组等待队列。圆圈代表为队列提供服务的资源,箭头表示系统中的进程流。
一个新进程最初被放入就绪队列中。它在那里等待,直到被选中执行或被分派(dispatched)。一旦进程被分配给一个CPU核心并正在执行,可能会发生以下几种事件之一:
进程可能发出一个I/O请求,然后被放入一个I/O等待队列。
进程可能创建一个新的子进程,然后被放入一个等待队列,直到其子进程终止。
进程可能因为中断或时间片到期而被强制从核心中移除,并被放回就绪队列。
3.2.2 CPU调度 (CPU Scheduling)
调度程序的工作方式如下。I/O密集型进程在等待I/O之前,可能只会执行几毫秒。一个CPU密集型进程可能需要更长的持续时间才能在核心上运行。然而,调度程序可能不会给予一个核心给一个长时间运行的进程。相反,它可能会从核心中移除该进程,并安排另一个进程运行。因此,CPU调度程序至少每100毫秒执行一次,尽管通常更频繁。
例如 , 如果没有抢占,一个CPU密集型进程(比如一个有bug的死循环程序)可以永久霸占CPU,导致你无法进行任何其他操作,连鼠标都动不了。
3.2.3 上下文切换 (Context Switch)
当中断发生时,系统需要保存当前正在CPU上运行的进程的上下文,以便在处理完中断后能够恢复该上下文。上下文在进程的PCB中表示。它包括CPU寄存器的值、进程状态(见图3.2)和内存管理信息。总的来说,我们需要保存当前CPU核心的状态,无论它是在内核模式还是用户模式,然后恢复一个状态以继续操作。
将CPU核心切换到另一个进程需要对当前进程的状态进行保存,并为另一个进程恢复状态。这个任务被称为上下文切换(context switch)。如图3.6所示,当发生上下文切换时,内核会将旧进程的上下文保存在其PCB中,并加载新进程已保存的上下文。上下文切换的时间是纯粹的开销(overhead),因为系统在切换期间没有做任何有用的工作。它的速度因机器而异,取决于内存速度、必须复制的寄存器数量以及是否存在用于加载或存储所有寄存器的特殊指令。
swap 通常是对内存的操作,对应着 Medium-term Scheduler
Short-term Scheduler 对应 位于内存中“就绪队列”里的进程
Long-term Scheduler 对应 Job Scheduler
3.3 对进程的操作 (Operations on Processes)
3.3.1 进程创建 (Process Creation)
在执行过程中,一个进程可能会创建几个新进程。创建进程被称为父进程(parent process),而新进程则被称为该进程的子进程(children of that process)。这些新进程中的每一个都可能再创建其他进程,从而形成一个进程树(tree of processes)
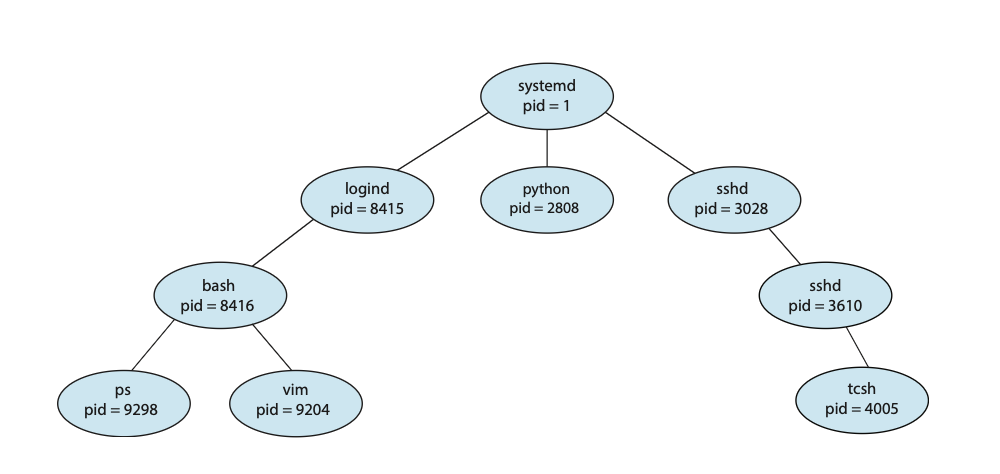
大多数操作系统(包括UNIX、Linux和Windows)都通过一个唯一的**进程标识符(process identifier, PID)**来识别进程,这个标识符通常是一个整数。PID为系统中的每个进程提供了一个唯一的数值,并且可以用来访问系统内进程的各种属性
通常,当一个进程创建一个子进程时,该子进程将需要某些资源(CPU时间、内存、文件、I/O设备)来完成其任务。子进程可以直接从操作系统获取其资源,或者它可能被限制为父进程资源的一个子集。父进程可能需要将资源在其子进程之间进行划分,或者它可能能够在其子进程之间共享一些资源(例如内存)。将子进程限制为父进程资源的一个子集可以防止任何进程因创建过多子进程而使系统过载。
除了各种物理和逻辑资源外,父进程还可能将初始化数据(输入)传递给子进程。例如,考虑一个进程,其功能是显示文件的内容——比如说
a.out——在屏幕上。当它被创建时,它会从其父进程那里获得文件名a.out作为输入。它将使用这个文件名打开文件并将其内容写到屏幕上。或者,父进程可能会传递一个指向打开文件的句柄。新进程会从其父进程的地址空间中获取文件名当一个新进程被创建时,对于执行有两种可能性:
父进程与其子进程并发执行。
父进程等待,直到其部分或所有子进程已经终止。
对于新进程的地址空间,也有两种可能性
子进程是父进程的一个副本(它拥有与父进程相同的程序和数据)
子进程加载了一个新的程序
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t pid;
/* fork a child process */
pid = fork();
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
return 1;
}
else if (pid == 0) { /* child process */
execlp("/bin/ls", "ls", NULL);
}
else { /* parent process */
/* parent will wait for the child to complete */
wait(NULL);
printf("Child Complete");
}
return 0;
}新进程由原始进程地址空间的一个副本组成。这种机制允许父进程轻松地与其子进程通信。
fork()进程和子进程都从exec()系统调用之后继续执行(fork 后 ready 准备被调度),但有一个区别:fork()对新(子)进程的返回码为零,而父进程的返回码是(非零的)子进程的pid在
fork()系统调用之后,其中一个进程通常使用exec()系统调用来用一个新程序替换该进程的内存空间。父进程可以创建更多的子进程;或者,如果它在子进程的执行期间没有什么可做的,它可以发出一个
wait()系统调用,将自己移出就绪队列,等待子进程的终止
3.3.2 进程终止 (Process Termination)
一个进程在执行完它的最后一条语句并请求操作系统通过
exit()系统调用来删除它时终止。此时,进程可能会向其父进程返回一个状态值(通常是一个整数)(通过wait()系统调用)。然后,该进程的所有资源——包括物理和虚拟内存、打开的文件和I/O缓冲区——都会被操作系统释放。父进程可能会因为多种原因终止其一个子进程的执行,例如:
子进程超出了其已分配资源的使用范围。(为了确定是否发生了这种情况,父进程必须有一个机制来检查其子进程的状态。)
分配给子进程的任务不再需要。
父进程正在退出,而操作系统不允许子进程在其父进程终止后继续运行。
当一个进程终止时,它的资源会被操作系统释放。然而,它在进程表中的条目必须保留,直到父进程调用
wait(),因为进程表包含了进程的退出状态。一个已经终止但其父进程尚未调用wait()的进程被称为僵尸进程(zombie process)。所有进程在终止时都会变成这种状态,但通常只存在很短的时间。一旦父进程调用wait(),僵尸进程的进程标识符和它在进程表中的条目就会被释放。现在,考虑如果一个父进程没有调用
wait()就终止了会发生什么。它的子进程就成了孤儿进程(orphan process)。UNIX系统通过将systemd进程(回忆一下3.1节,它在UNIX系统中始终存在)指定为孤儿进程的新父进程来解决这个问题。systemd进程会周期性地调用wait(),从而收集任何已终止孤儿进程的退出状态并释放这些进程的标识符和进程表条目。
3.4 进程间通信 (Interprocess Communication)
在一个操作系统中执行的进程可能是独立 (independent) 进程,也可能是协作 (cooperating) 进程。如果一个进程不能影响其他进程的执行,也不能被其他进程影响,那么它就是独立的。系统中的任何其他进程都不能与该进程共享数据。一个协作进程则可以影响其他进程或被其他进程影响。显然,任何与其他进程共享数据的进程都是一个协作进程
有多种原因需要提供一个允许进程协作的环境:
信息共享 (Information sharing)。由于多个应用可能对同一份信息感兴趣(例如,复制和粘贴),我们必须提供一个允许多个进程并发访问这些信息的环境。
计算加速 (Computation speedup)。如果我们想让一个特定任务运行得更快,我们必须把它分解成多个子任务,每个子任务将与其他子任务并行执行。这样的加速只有在计算机拥有多个处理核心时才能实现。
模块化 (Modularity)。我们可能希望以模块化的方式构建系统,将系统功能划分为独立的进程或线程,正如我们在第 2 章中讨论的那样。
协作进程需要一个进程间通信 (IPC) 机制,允许它们交换数据和信息,即发送数据给对方和从对方接收数据。进程间通信的两种基本模型是共享内存 (shared memory) 和消息传递 (message passing)。在共享内存模型中,会建立一个由协作进程共享的内存区域。进程可以通过向共享区域读写数据来交换信息。在消息传递模型中,通信是通过协作进程之间交换消息来进行的。
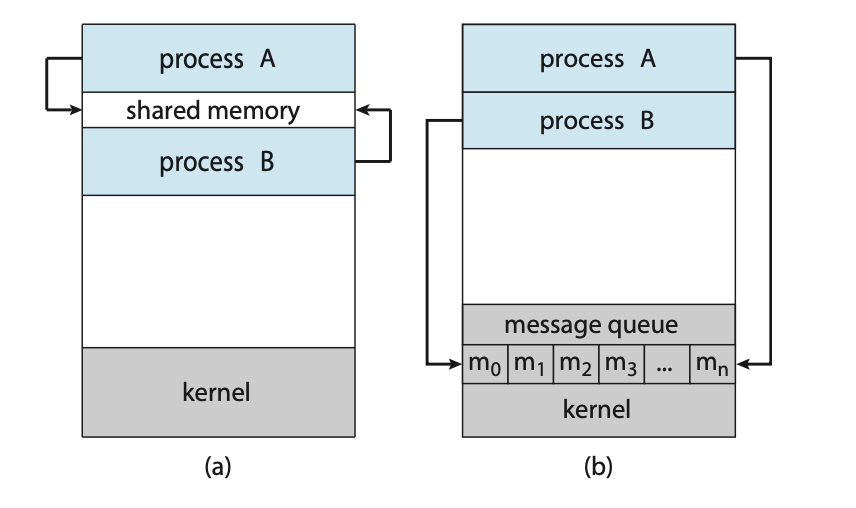
刚才提到的两种模型都在操作系统中很常见,许多系统甚至同时实现了两者。消息传递对于交换少量数据非常有用,因为它避免了冲突。消息传递也比共享内存更容易在分布式系统中实现。(虽然有提供分布式共享内存的系统,但我们在这里不考虑它们。)共享内存可能比消息传递速度更快,因为消息传递系统通常是通过系统调用实现的,因此需要更耗时的内核介入。而在共享内存系统中,系统调用仅在建立共享内存区域时才需要。一旦内存被建立,所有访问都将作为常规的内存访问处理,无需内核的协助。在 3.5 节和 3.6 节中,我们将探讨共享内存系统和消息传递系统中的进程间通信。
3.5 共享内存系统中的进程间通信 (IPC in Shared-Memory Systems)
使用共享内存的进程间通信需要通信进程建立一个共享内存区域。一个典型的情况是,一个进程在自己的地址空间内创建一个共享内存段。希望与该共享内存段通信的进程必须将其附加 (attach) 到自己的地址空间。通常,操作系统会试图阻止一个进程访问另一个进程的内存。共享内存要求两个或更多进程同意放弃这个限制。它们通过读写共享区域来交换信息。数据的形式和位置由这些进程决定,而不是由操作系统控制。这些进程也有责任确保它们不会同时向同一位置写入数据。
为了阐明协作进程的概念,让我们来思考一下生产者-消费者问题 (producer–consumer problem),这是一个协作进程的经典范例。一个生产者 (producer) 进程产生信息,而一个消费者 (consumer) 进程消费这些信息。例如,一个汇编器可能会产生汇编代码,这些代码由汇编器消费。反过来,汇编器可能会产生目标模块,这些模块由加载器消费。生产者-消费者问题也为客户端-服务器范式提供了一个有用的隐喻。我们通常可以把服务器视为生产者,把客户端视为消费者。例如,一个 Web 服务器生产(即提供)HTML 文件和图片,这些文件和图片由请求该资源的客户端 Web 浏览器消费(即读取)。
解决生产者-消费者问题的一种方案是让进程共享资源。为了允许生产者和消费者进程并发运行,我们必须提供一个可用的缓冲区 (buffer),其中可以存放由生产者生产、等待消费者消费的物品。这个缓冲区将驻留在由生产者和消费者进程共享的内存区域中。生产者可以生产一个物品,而消费者正在消费另一个物品。生产者和消费者必须是同步的,这样消费者就不会试图去消费一个尚未被生产的物品。
缓冲区可以有两种类型。无界缓冲区 (unbounded buffer) 对缓冲区的大小没有实际限制。消费者可能需要等待新物品,但生产者总能生产新物品。有界缓冲区 (bounded buffer) 则假定一个固定的缓冲区大小。在这种情况下,如果缓冲区为空,消费者必须等待,而如果缓冲区已满,生产者必须等待。
下面的变量驻留在由生产者和消费者进程共享的内存区域中:
#define BUFFER_SIZE 10
typedef struct {
. . .
} item;
item buffer[BUFFER_SIZE];
int in = 0;
int out = 0;当
in == out时,缓冲区为空;当(in + 1) % BUFFER_SIZE == out时,缓冲区已满。
item next_produced;
while (true) {
/* 生产一个物品并放入 next_produced */
while (((in + 1) % BUFFER_SIZE) == out)
; /* 什么都不做 */
buffer[in] = next_produced;
in = (in + 1) % BUFFER_SIZE;
}生产者, 这个方案在缓冲区中最多可以容纳
BUFFER_SIZE - 1个物品 , 可以通过生产中先存再while等待空余位置来容纳 BUFFER_SIZE个(即调换一下两句话的位置)
item next_consumed;
while (true) {
while (in == out)
; /* 什么都不做 */
next_consumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
/* 消费物品 next_consumed */
}消费者
3.6 消息传递系统中的进程间通信 (IPC in Message-Passing Systems)
我们展示了协作进程如何在共享内存系统中进行通信。该方案要求进程共享一个内存区域,并且操作共享内存的代码必须由应用开发者显式地编写。另一种实现相同目标的方法是让操作系统为协作进程提供一种机制,使它们能够通过消息传递设施进行相互通信。
消息传递提供了一种允许进程在不共享地址空间的情况下进行通信的机制。这在分布式环境中特别有用,因为通信进程可能位于通过网络连接的不同计算机上。例如,一个互联网聊天程序可以被设计成让参与聊天的客户端通过交换消息来进行通信。
一个消息传递设施至少提供两种操作:
send(message)和receive(message)如果进程 P 和 Q 想要通信,它们必须互相发送和接收消息;它们之间必须存在一个通信链路 (communication link)。这个链路可以通过多种方式实现。他有三种性质:
Direct or indirect communication
Synchronous or asynchronous communication
Automatic or explicit buffering
3.6.1 Naming
想要通信的进程必须有办法相互引用。它们可以使用直接或间接通信。
在直接通信 (direct communication) 中,每个想要通信的进程必须明确地命名接收者或发送者。在这种方案中,send() 和 receive() 原语的定义如下:
send(P, message)—— 发送一条消息给进程 P。receive(Q, message)—— 从进程 Q 接收一条消息。
这种通信链路具有以下属性:
在每一对想要通信的进程之间,会自动建立一个链路。进程只需要知道对方的身份即可通信。
一个链路只与一对通信进程相关联。
在每对进程之间,只存在一个链路。
这种方案在寻址方面表现出对称性 (symmetry);也就是说,发送进程和接收进程都必须指明对方才能通信。一种变体采用非对称寻址 (asymmetry in addressing),其中只有发送者需要命名接收者;接收者不需要命名发送者。在这种方案中,send() 和 receive() 原语的定义如下:
send(P, message)—— 发送一条消息给进程 P。receive(id, message)—— 从任何进程接收一条消息。变量id被设置为消息来源的进程名称。
这两种方案(对称和非对称)的缺点是它们的模块化程度有限。对进程定义的任何更改都可能需要检查所有其他进程的定义。例如,如果一个进程的标识符被更改,可能需要修改所有引用旧标识符的地方,以便它们可以被修改为新的标识符。任何这样的硬编码技术,其中标识符必须被明确说明,都比接下来描述的间接技术要差。
在间接通信 (indirect communication) 中,消息是从邮箱 (mailboxes)(有时也称为端口 (ports))发送和接收的。一个邮箱可以被看作是一个对象,进程可以向其中放置消息,也可以从中移除消息。每个邮箱都有一个唯一的标识符。例如,POSIX 消息队列使用一个整数值来标识邮箱。一个进程可以通过共享不同邮箱的多个进程进行通信。两个进程只有在共享一个邮箱时才能通信。send() 和 receive() 原语的定义如下:
send(A, message)—— 发送一条消息到邮箱 A。receive(A, message)—— 从邮箱 A 接收一条消息。
在这种方案中,一个通信链路具有以下属性:
一个链路只有在两个进程共享一个邮箱时才会在它们之间建立。
一个链路可能与两个以上的进程相关联。
在每对通信进程之间,可能存在多个不同的链路,每个链路对应一个邮箱。

允许一个链路最多只与一个进程关联,以便在任意时刻执行
receive()操作。(方法1,自行加以限制)允许系统从多个接收者中任意选择一个(例如,P₂ 或 P₃,但不能两者都选),并将消息传递给它。系统可以定义一种算法来选择接收者(例如,轮询 (round robin),即让进程轮流接收消息)。系统可以将接收者告知发送方。
(题外话)默认情况下,创建新邮箱的进程是该邮箱的所有者(也可以是系统拥有)(由于每个邮箱都有一个唯一的所有者,因此不会出现应该由哪个进程接收消息的混淆。)。最初,只有所有者可以从该邮箱接收消息。然而,所有权和接收权限可以通过适当的系统调用传递给其他进程。当然,这种规定可能会导致每个邮箱有多个接收者。
3.6.2 同步 (Synchronization)
进程之间的通信是通过调用 send() 和 receive() 原语来实现的。有不同的设计选项可以实现每个原语。消息传递可以是阻塞的 (blocking) 或非阻塞的 (non-blocking)—— 也被称为同步的 (synchronous) 和异步的 (asynchronous)。在整个文本当中,你将会遇到各种操作系统算法中同步和异步的概念。
阻塞式发送 (Blocking send)。发送进程被阻塞,直到消息被接收进程或邮箱接收为止。
非阻塞式发送 (Nonblocking send)。发送进程发送消息并恢复操作。
阻塞式接收 (Blocking receive)。接收者被阻塞,直到有可用的消息为止。
非阻塞式接收 (Nonblocking receive)。接收者取回一个有效消息或一个空值 (null)。
send() 和 receive() 原语的不同组合是可能的。当 send() 和 receive() 都是阻塞式的时候,我们就在发送者和接收者之间有了一次会合 (rendezvous)。当 send() 和 receive() 语句都是阻塞式时,生产者-消费者问题就变得微不足道了。生产者只需调用阻塞式的 send(),然后等待,直到消费者通过调用 receive() 接收到消息。同样,当消费者调用 receive() 时,它会被阻塞,直到有消息可用为止。这种情况在图 3.14 和 3.15 中有所说明。
3.6.3 缓冲 (Buffering)
无论通信是直接的还是间接的,由通信进程交换的消息都驻留在一个临时队列中。基本上,这样的队列可以通过三种方式实现:
零容量 (Zero capacity)。队列的最大长度为零;因此,链路上不能有任何消息在等待。在这种情况下,发送者必须阻塞,直到接收者收到消息为止。
有界容量 (Bounded capacity)。队列的长度是有限的 n;因此,最多只能有 n 条消息驻留在链路上。如果在一个已满的队列上发送新消息,发送者将被阻塞,直到队列中有可用空间为止(无论是消息被复制还是指针被保留),然后发送者可以继续执行而无需等待。
无界容量 (Unbounded capacity)。队列的长度是潜在无限的;因此,任何数量的消息都可以等待。发送者永远不会被阻塞。
零容量的情况有时被称为无缓冲的消息系统 (message system with no buffering)。其他情况则被称为带有自动缓冲的系统 (systems with automatic buffering)。
3.7 Examples of IPC Systems
当使用共享内存进行进程间通信时,两个(或更多)进程共享同一块内存区域。POSIX 为共享内存提供了一个 API。
两个进程可以通过使用消息传递来交换消息进行通信。Mach 操作系统使用消息传递作为其主要的进程间通信形式。Windows 也提供了一种消息传递的形式。
3.7.4 管道
疑问:If two-way communication is allowed, is it half duplex(半双工) (data can travel only one way at a time) or full duplex (data can travel in both directions
at thesametime)?
3.7.4.1 普通管道
普通管道允许两个进程以标准的生产者-消费者模式进行通信:生产者向管道的一端(写入端
write end)写入数据,而消费者从另一端(读取端read end)读取数据。因此,普通管道是单向的,只允许单向通信。如果需要双向通信,则必须使用两个管道,每个管道负责一个方向的数据发送。请注意,普通管道在 UNIX 和 Windows 系统中都需要通信进程之间存在父子关系。这意味着这些管道只能用于在同一台机器上的进程之间进行通信。
3.7.4.2 命名管道 (Named Pipes)
普通管道提供了一种机制,允许一对通信进程相互通信。然而,普通管道仅在这些进程进行通信时存在。在 UNIX 和 Windows 系统中,一旦进程完成通信并终止,普通管道就会不复存在。
命名管道提供了一个更强大的通信工具。通信可以是双向的,并且不需要父子关系。一旦命名管道被建立,多个进程都可以使用它进行通信。事实上,在典型的场景中,一个命名管道可以有多个写入者。此外,命名管道在通信进程结束后会继续存在。UNIX 和 Windows 系统都支持命名管道,尽管它们实现的细节差异很大。接下来我们将分别探讨这两种系统中的命名管道。
Chapter4: Threads & Concurrency
4.1 概述
线程是 CPU 利用率的基本单位;它包含一个线程ID、一个程序计数器(PC)、一组寄存器和一个栈。它与同一进程中的其他线程共享代码段、数据段以及其他操作系统资源(如打开的文件和信号)。一个传统的进程只有一个控制线程。如果一个进程有多个控制线程,它就可以一次执行多个任务。图 4.1 展示了传统单线程进程和多线程进程之间的区别。

4.1.1 Motivation
在某些情况下,单个应用程序可能需要执行几个类似的任务。例如,一个 Web 服务器接受来自客户端的网页、图像、声音等请求。一个繁忙的 Web 服务器可能会有成百上千个客户端同时请求服务。如果 Web 服务器以传统的单线程进程方式运行,它一次只能为一个客户端提供服务,这会导致排在后面的客户端需要等待很长时间才能得到服务。
一种解决方案是将服务器作为单个进程运行,当服务器收到请求时,它会为该请求创建一个独立的进程。事实上,这种进程创建方法在进程模型变得流行之前很常用。因为进程创建非常耗时且占用资源,如果新进程将执行与现有进程相同的任务,这样做是否值得?通常更有效的做法是使用一个能接受请求的进程,然后创建另一个独立的线程来处理该请求。这种多线程的服务器会有一个监听请求的线程。当收到请求时,它不是创建一个新进程,而是创建一个新线程来为请求提供服务,并恢复监听其他客户端的请求。
大多数操作系统内核本身也是多线程的。举个例子,在系统启动期间,在 Linux 系统上,会启动几个内核线程。每个线程执行特定的任务,例如管理设备、内存管理或中断处理。
ps -ef命令可用于显示 Linux 内核中的线程;该命令的输出将显示kthreadd线程(pid=2),它是所有其他内核线程的父线程。
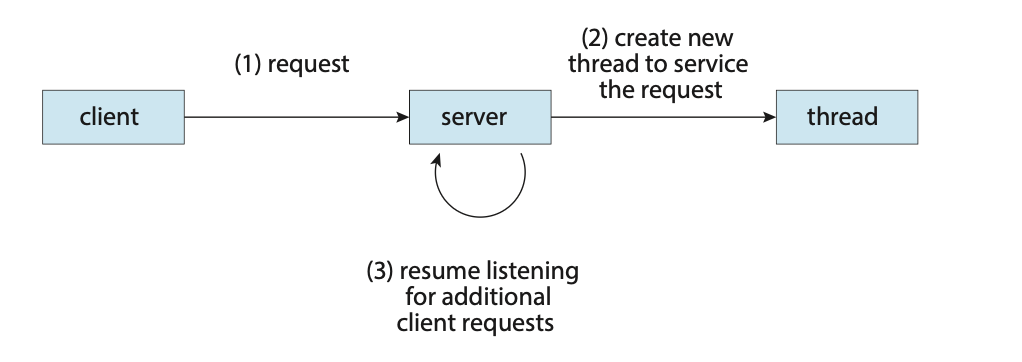
多线程服务器的架构
4.1.2 优点
响应性 (Responsiveness)。 多线程技术可以使交互式应用程序持续运行,即使它的一部分被阻塞或正在执行冗长的操作,从而提高了对用户的响应性。这在设计用户界面时尤其有用。试想一下,当用户点击一个按钮时会发生什么,而这个操作会导致一个耗时的操作。在一个单线程应用程序中,在耗时操作完成之前,用户将无法与应用程序进行交互。相反,如果耗时的操作在一个单独的、异步的线程中执行,应用程序将保持对用户的响应。
资源共享 (Resource sharing)。 进程只能通过共享内存和消息传递等技术来共享资源。这些技术必须由程序员显式地安排。然而,线程默认共享其所属进程的内存和资源。共享代码和数据的好处是,它允许一个应用程序在同一地址空间内有多个不同的活动线程。
经济性 (Economy)。 为进程分配内存和资源是昂贵的。因为线程共享其所属进程的资源,所以创建和切换线程的开销要比创建和切换进程的开销小得多。经验上,在创建方面,线程比进程消耗更少的时间和内存。因此,上下文切换在线程之间通常也比在进程之间更快。
可伸缩性 (Scalability)。 在多处理器体系结构中,多线程的优势可能更大,因为线程可以在不同的处理核心上并行运行。而一个单线程进程无论有多少可用的处理器,都只能在一个核心上运行。我们将在本章后面进一步探讨这个问题
4.2 多核编程 (Multicore Programming)
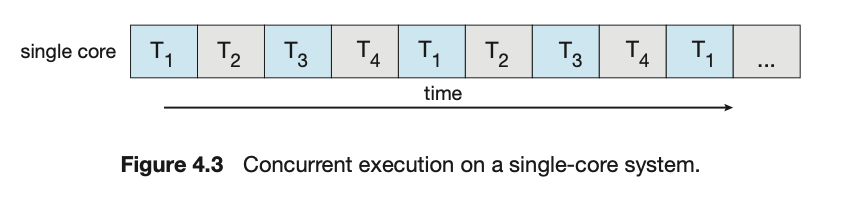
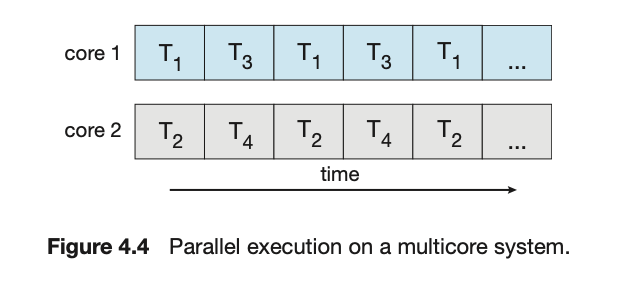
在一个具有单个核心的系统上,并发意味着一个应用程序的执行可以是交错的(threads will be interleaved
overtime)(在单核上一次只执行一个线程);然而,在具有多个核心的系统上,并发(concurrency)意味着某些线程可以并行(in parallel)运行,因为系统可以将每个核心分配给一个独立的线程
请注意本次讨论中并发 (concurrency) 和并行 (parallelism) 之间的区别。一个并发系统通过允许所有任务取得进展来支持多个任务。相比之下,一个并行系统可以同时执行多个任务。因此,可以有并发但没有并行。在多处理器和多核架构出现之前,大多数计算机系统只有一个处理器,CPU 调度器的设计目的是通过在进程之间快速切换来提供并行的假象,从而允许每个进程都能取得进展。这样的进程是并发运行,但不是并行运行。
4.2.1 Programming Challenges
对于应用程序员来说,挑战在于修改现有程序以及设计新的多线程程序。面临 挑战有
识别任务 (Identifying tasks): 找出可以被划分为独立的、并发的任务的区域
平衡 (Balance): 确保这些任务执行同等价值的工作
数据拆分 (Data splitting) : 正如应用程序被划分为独立的任务一样,这些任务所访问和操作的数据也必须进行拆分
数据依赖 (Data dependency)
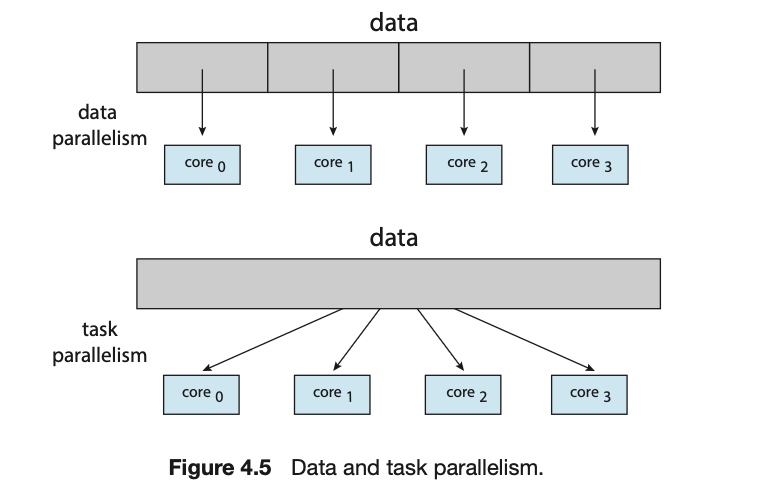
数据并行和任务并行
4.3 多线程模型 (Multithreading Models)
对线程的支持可以在用户层面为用户线程 (user threads) 提供,也可以由内核为内核线程 (kernel threads) 提供。用户线程在内核之上(外)被支持,其管理无需内核支持;而内核线程则由操作系统直接支持和管理。几乎所有当代的操作系统——包括 Windows、Linux 和 macOS——都支持内核线程。
最终,用户线程和内核线程之间必须存在某种关系,如图 4.6 所示。在本节中,我们研究建立这种关系的三种常见方式:多对一模型、一对一模型和多对多模型
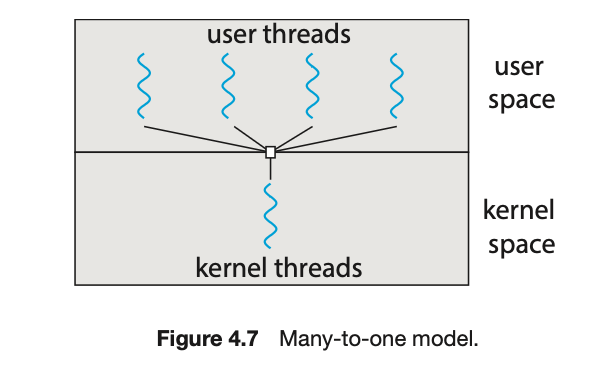
4.3.1 多对一模型 (Many-to-One Model)
多对一模型(图 4.7)将多个用户级线程映射到一个内核线程。线程管理是在用户空间通过线程库完成的。因此,它是高效的(我们将在 4.4 节讨论线程库)。然而,整个进程会在一个线程进行阻塞式系统调用时被阻塞。一次只有一个线程可以访问内核,因此多线程无法在多核系统上并行运行
为什么不能在多核系统上并行运行:在“多对一”模型中,整个进程(包括它内部所有的用户线程)只有一张门禁卡(一个内核线程)。因此,在总调度员的眼里,只有一个“单位”可以被安排工作。
4.3.2 一对一模型 (One-to-One Model)
一对一模型(图 4.8)将每个用户线程映射到一个内核线程。它通过允许另一个线程在某个线程进行阻塞式系统调用时继续运行,从而提供了比多对一模型更好的并发性。它还允许多个线程在多处理器上并行运行。该模型唯一的缺点是,创建一个用户线程就需要创建一个相应的内核线程,而大量的内核线程可能会影响系统性能。Linux 以及 Windows 家族的操作系统实现了这种一对一模型。
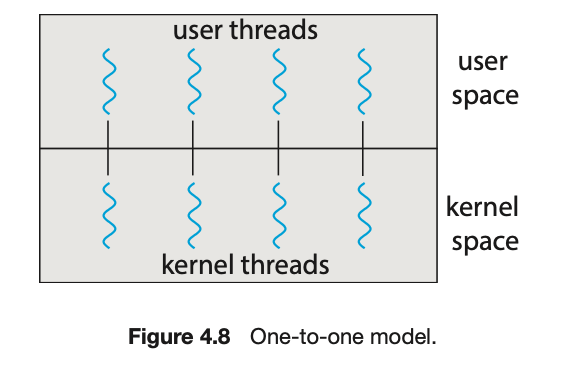
4.3.3 多对多模型 (Many-to-Many Model)
多对多模型(图 4.9)将多个用户级线程多路复用(multiplex)到数量较小或相等的内核线程上。内核线程的数量可能特定于某个特定应用程序或特定机器(一个应用程序可能会在一个拥有八个处理核心的系统上被分配比拥有四个核心的系统更多的内核线程)。
让我们思考一下这种设计的后果。多对一模型允许开发者创建任意多的用户线程,但由于内核一次只能调度一个线程,因此无法实现并行。一对一模型提供了更好的并发性,但开发者必须小心,不要在应用程序中创建过多的线程。(事实上,在某些系统上,可以创建的线程数量可能会受到限制。)多对多模型不存在这两个缺点:开发者可以创建任意多的用户线程,相应的内核线程可以在多处理器上并行运行。此外,当一个线程执行阻塞式系统调用时,内核可以调度另一个线程来执行。
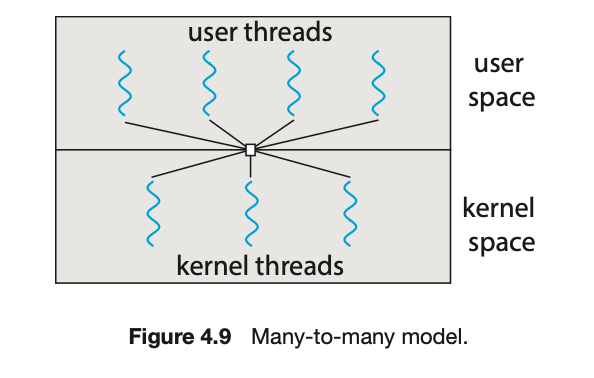
多对多模型的一种变体仍然将多个用户级线程多路复用到数量较小或相等的内核线程上,但也允许将一个用户级线程绑定到一个内核线程上。这种变体有时被称为两级模型 (two-level model)(图 4.10)。
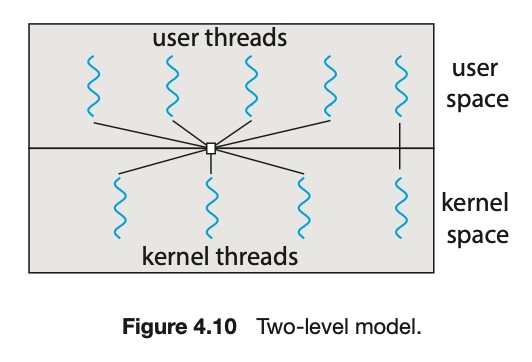
尽管多对多模型似乎是所讨论的模型中最灵活的,但实现起来很困难。此外,随着系统中处理核心数量的增加,限制内核线程数量的重要性变得越来越小。因此,大多数现在使用一对一模型的操作系统。然而,正如我们将在 4.5 节中看到的,一些当代的并发库让开发者识别出任务,然后将这些任务映射到使用多对多模型的线程上。
4.4 线程库 (Thread Libraries)
线程库为程序员提供了一个用于创建和管理线程的 API。实现线程库主要有两种方式。第一种方式是提供一个完全在用户空间中运行的库,没有任何内核支持。该库的所有代码和数据结构都存在于用户空间。这意味着调用库中的函数只会导致在用户空间进行本地函数调用,而不是系统调用。
第二种方式是实现一个由操作系统直接支持的内核级库。在这种情况下,库的代码和数据结构位于内核空间。调用 API 中针对该库的函数通常会导致对内核的系统调用
在我们继续我们的线程创建示例之前,我们介绍创建多个线程的两种通用策略:异步线程 (asynchronous threading) 和同步线程 (synchronous threading)。对于异步线程,一旦父线程创建了一个子线程,父线程就恢复其执行,这样父子线程就可以并发执行,并且彼此独立。由于线程是独立的,父线程通常不需要知道其子线程何时终止。异步线程是在多线程服务器中使用的策略,如图 4.2 所示,并且也常用于设计响应式用户界面。
同步线程发生在父线程创建一个或多个子线程,然后必须等待所有子线程终止后才能恢复执行。在这里,创建子线程的父线程会暂停工作,直到所有子线程都完成。父线程完成工作后,会与它的所有子线程会合(joins)。一旦所有子线程都已会合,父线程就可以恢复执行。同步线程涉及在线程之间共享大量数据。例如,父线程可能需要合并其所有子线程计算出的结果。以下所有示例都使用同步线程。
在多线程程序里。假设一个进程有 10 个线程。当其中一个线程(比如线程 A)调用了
fork(),新创建的子进程里应该是什么样的?是也包含 10 个线程,还是只包含一个克隆版的线程 A?
某些 Unix 系统有两种版本的
fork()。一个版本会复制所有线程,另一个版本只复制调用fork()的那个线程。不过,这件事(指实现复制所有线程)并不简单。为了避免这些无法解决的复杂问题,标准的
fork()只复制调用者自身
exec()家族的函数(如execlp(),execv(), 等)的作用是加载一个全新的程序来覆盖当前的进程。一旦exec()被成功调用,当前进程的内存空间(包括代码、数据、堆栈以及所有的线程)都会被完全丢弃,然后被新程序的内容所取代。进程的 ID (PID) 不变,但它已经变成了一个完全不同的程序。
4.5 隐式线程 (Implicit Threading)
随着多核处理的持续增长,包含数百甚至数千个线程的应用程序即将出现。设计这样的应用程序并非易事; 应对这些困难并更好地支持并发应用程序设计的一种方法是将线程创建和管理的责任从应用程序开发人员转移到编译器和运行时库。这种策略被称为隐式线程 (implicit threading)
4.5.1 线程池 (Thread Pools)
在 4.1 节中,我们描述了一个多线程服务器。在这种情况下,当服务器收到一个请求时,它会创建一个单独的线程来处理该请求。虽然创建一个单独的线程来处理服务而不是创建一个单独的进程是可行的,但这种方法仍然存在潜在问题。第一个问题与创建线程所需的时间有关。第二个问题是,如果每个并发请求都需要创建一个新线程,那么活动线程的数量在系统资源(如 CPU 时间或内存)方面是没有限制的。解决这个问题的一种方法是使用线程池 (thread pool)。
线程池背后的基本思想是在启动时创建一定数量的线程,并将它们放入一个池中等待工作。当服务器收到一个请求时,它不是创建一个新线程,而是从池中唤醒一个线程,向其提交请求,然后恢复等待。如果池中没有可用的线程,服务器会等待,直到有线程空闲下来。当一个线程完成了它的服务后,它会返回到池中,并等待更多的工作。线程池在提交给它们的任务可以被异步执行时效果很好。线程池提供了以下好处:
用池中的现有线程来处理请求通常比等待创建一个新线程要快。
线程池在任何时候都限制了现有线程的数量。这对于那些无法支持大量并发线程的系统来说尤其重要。
将要执行的任务与创建任务的机制分离开来,允许我们使用不同的策略来运行任务。例如,任务可以被安排为在延迟后执行,或者周期性地执行。
池中线程的数量可以根据 CPU 数量、物理内存大小以及预期的并发客户端数量等因素进行启发式设置。更复杂的线程池架构可以根据使用情况动态调整池中的线程数量:如果系统负载低,池中的线程数量可以减少;如果负载高,则可以增加。
4.6 线程问题 (Threading Issues)
4.6.1 fork() 和 exec() 系统调用
在第3章中,我们描述了
fork()系统调用如何被用来创建一个独立的、重复的进程。在多线程程序中,fork()和exec()系统调用的语义会发生变化。
如果程序中的一个线程调用
fork(),新进程是会复制所有线程,还是只有一个线程?一些 UNIX 系统提供了两个版本的fork():一个复制所有线程,另一个只复制调用了fork()系统调用的那个线程。
exec() 系统调用的工作方式与第3章中描述的完全相同。也就是说,如果一个线程调用了
exec()系统调用,那么在exec()的参数中指定的程序将替换整个进程——包括其所有线程。应该使用
fork()的哪种版本取决于应用程序。如果 fork() 之后立即调用 exec(),那么复制所有线程是不必要的,因为exec()的参数中指定的程序将替换整个进程。在这种情况下,只复制调用fork()的线程是合适的。然而,如果独立的进程在 fork() 之后不调用 exec(),那么这个独立的进程应该复制所有线程。
4.6.2 信号处理 (Signal Handling)
信号 (signal) 在 UNIX 系统中用于通知进程某个特定事件已经发生。信号的接收可能是同步的,也可能是异步的,这取决于事件的来源和被发信号的原因。
同步信号的例子包括非法内存访问和除以0。如果一个正在运行的程序执行了这些操作之一,就会产生一个信号。同步信号被传递到执行了导致该信号的操作的同一进程中(这就是它们被认为是同步的原因)。
当一个正在运行的程序之外的事件产生一个信号时,进程会异步地接收到该信号。这类信号的例子包括通过特定的按键(如
<control><C>)终止一个进程,或者定时器到期。通常,异步信号被发送到另一个进程在单线程程序中处理信号是直截了当的:信号总是被传递到进程。然而,在多线程程序中传递信号更为复杂,因为一个进程可能有多个线程。那么,信号应该被传递到哪里呢?有以下选项
将信号传递给其适用的线程。
将信号传递给进程中的每一个线程。
将信号传递给进程中的某些特定线程。
指定一个特定的线程来接收进程的所有信号。
传递信号的方法取决于产生的信号类型。例如,同步信号需要被传递到导致该信号的线程,而不能传递到进程中的其他线程。然而,对于异步信号,情况就不那么明朗了。一些异步信号——例如终止进程的信号(
<control><C>)——应该被发送到所有线程。
4.6.3 线程取消 (Thread Cancellation)
线程取消 (Thread cancellation) 指在一个线程完成其任务之前终止它。例如,如果多个线程正在并发地搜索一个数据库,而其中一个线程返回了结果,那么其余的线程就可以被取消。另一种情况可能发生在用户按下网页浏览器上的停止按钮,从而阻止网页进一步加载。通常,一个网页会使用多个线程加载——每个图像都由一个单独的线程加载。当用户按下浏览器上的停止按钮时,所有加载该页面的线程都会被取消。
一个将要被取消的线程通常被称为目标线程 (target thread)。目标线程的取消可能在两种不同的场景下发生:
异步取消 (Asynchronous cancellation)。一个线程立即终止目标线程。
延迟取消 (Deferred cancellation)。目标线程周期性地检查它是否应该终止,从而允许它以有序的方式自行终止。
取消的困难之处在于,当一个被取消的线程被分配了资源,或者一个线程在更新与其他线程共享的数据的过程中被取消时。这在异步取消中尤其麻烦。通常,操作系统会回收来自一个被取消线程的系统资源,但不会回收所有资源。因此,异步取消一个线程可能不会释放所有系统范围内的资源。
相比之下,在延迟取消中,一个线程指示目标线程应该被取消,但取消操作只有在目标线程检查了一个标志以确定是否应该被取消之后才会发生。线程可以在可以被安全取消的时候执行这个检查。
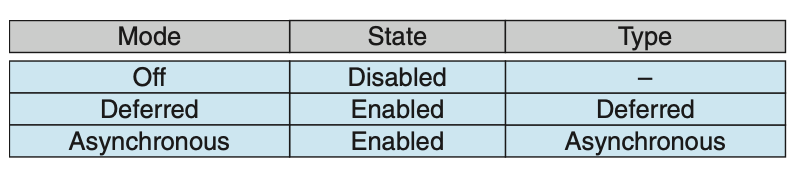
如该表所示,Pthreads 允许线程禁用或启用取消。显然,如果取消被禁用,线程是无法被取消的。然而,取消请求会保持挂起状态,以便线程之后可以启用取消并响应请求。
默认的取消类型是延迟取消。然而,取消只有在线程到达一个取消点 (cancellation point) 时才会发生。
Chapter5: CPU Scheduling
5.1 概述
在一个单核 CPU 系统中,一次只能运行一个进程。其他进程必须等到 CPU 空闲后才能被重新调度。多道程序的目标是在任何时候都有一些进程在运行,以最大化 CPU 的利用率。这个想法相对简单。一个进程被执行直到它必须等待,通常是为了完成某个 I/O 请求。在一个简单的计算机系统中,CPU 会一直空闲。所有这些等待时间都被浪费了;没有任何有用的工作被完成。通过多道程序,我们试图高效地利用这段时间。内存中会保留几个进程。当一个进程必须等待时,操作系统会从该进程手中拿走 CPU,并将其交给另一个进程。这种模式会持续下去。每当一个进程必须等待时,另一个进程就可以接管 CPU 的使用。这种保持 CPU 繁忙的概念也延伸到了多核系统。

5.1.1 CPU–I/O 执行周期 (CPU–I/O Burst Cycle)
CPU 调度的成功取决于对进程属性的观察和理解:进程的执行由 CPU 执行和 I/O 等待的周期 (cycle) 构成。进程在这两种状态之间交替。进程的执行始于一个 CPU 执行期 (CPU burst),随后是一个 I/O 等待期 (I/O burst),接着是另一个 CPU 执行期,如此循环。最终,最后一个 CPU 执行期以一个结束执行的系统请求结束(图 5.1)。
CPU 执行期的持续时间已被广泛测量。尽管它们因进程和计算机的不同而有很大差异,但它们倾向于呈现出如图 5.2 所示的频率曲线。该曲线通常具有指数或超指数分布的特征,其特点是包含大量短的 CPU 执行期和少量长的 CPU 执行期。一个 I/O 密集型程序通常会有许多短的 CPU 执行期。而一个 CPU 密集型程序可能会有几个长的 CPU 执行期。在实现 CPU 调度算法时,这种分布可能很重要。
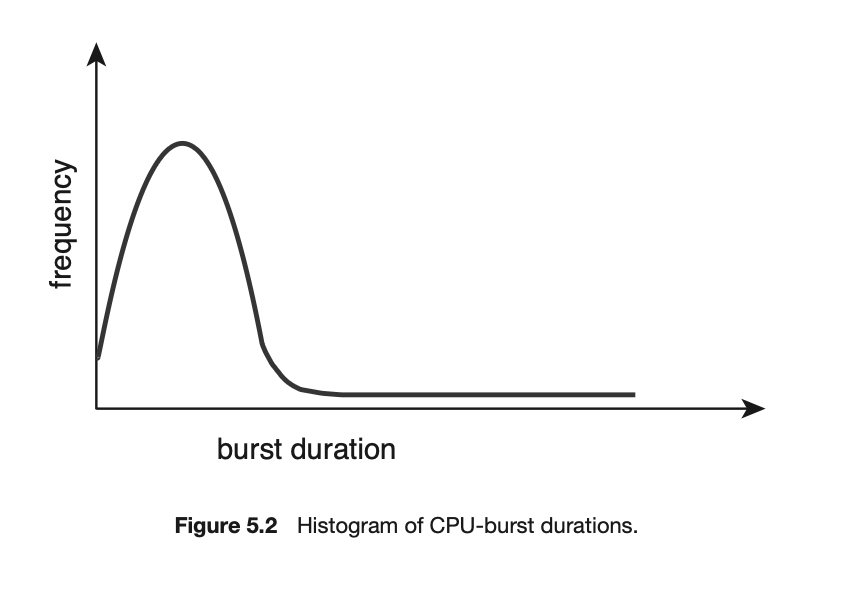
5.1.2 CPU 调度程序 (CPU Scheduler)
每当 CPU 空闲时,操作系统就必须从就绪队列 (ready queue) 中选择一个进程来执行。这个选择过程由 CPU 调度程序 (CPU scheduler) 执行。调度程序从内存中选择那些准备好执行的进程,并为它们分配 CPU。
请注意,就绪队列不一定是先进先出 (FIFO) 队列。正如我们将在考虑各种调度算法时看到的,就绪队列可以实现为 FIFO 队列、优先队列、树或一个无序的链表。概念上,就绪队列中的所有进程都在排队等待在 CPU 上运行的机会。队列中的记录通常是进程的进程控制块 (PCBs)。
5.1.3 抢占式和非抢占式调度 (Preemptive and Nonpreemptive Scheduling)
CPU 调度决策可能在以下四种情况下发生:
当一个进程从运行状态切换到等待状态时(例如,由于 I/O 请求或调用
wait()以等待子进程终止)。当一个进程从运行状态切换到就绪状态时(例如,当发生中断时)。
当一个进程从等待状态切换到就绪状态时(例如,I/O 完成时)。
当一个进程终止时。
当调度只在情况 1 和 4 下发生时,我们说调度方案是非抢占式的(nonpreemptive) 或协作式的 (cooperative) ;否则,就是抢占式的 (preemptive)。
区别,非抢占式:“除非我自己放弃,否则谁也别想拿走我的 CPU。” 抢占式 : “你的时间到了,现在 CPU 归我管,换下一个!”当进程结束时调度则是非抢占式,当有进程就绪时强制调度是抢占式
不幸的是,抢占式调度可能会在多个进程共享数据时导致竞争条件。考虑两个进程共享数据的情况。当一个进程正在更新数据时,它被抢占,以便第二个进程可以运行。然后第二个进程试图读取数据,而此时数据处于不一致的状态。这个问题将在第 6 章中详细探讨。
抢占也影响了操作系统内核的设计。在系统调用期间,内核可能代表某个进程忙于某项活动。这些活动可能涉及更改重要的内核数据(例如,用于 I/O 队列的数据)。如果在修改这些结构的过程中内核被抢占,并且内核(为另一个设备驱动程序)试图读取或修改同一结构,就可能出现混乱。如 5.2 节所述,操作系统内核可以被设计为非抢占式或抢占式。非抢占式内核会等待系统调用完成或进程阻塞后再进行上下文切换。这种方案确保了内核数据结构不会处于不一致的状态。不幸的是,这种执行模型是一个糟糕的单核支持,因为任务必须在有限的时间内完成执行。在 5.6 节中,我们探讨了实时系统的调度需求。一个抢占式内核需要像互斥锁 (mutex locks) 这样的机制来防止在访问共享内核数据时出现竞争条件。大多数现代操作系统在内核模式下运行时都是完全抢占式的。
因为中断可以随时发生,并且不能总是被内核忽略,所以必须保护被受影响的中断所访问的代码段,以防止同时使用。操作系统需要在几乎所有时候都接受中断。否则,输入可能会丢失或输出可能会被覆盖。那些禁用中断的代码段不会被多个进程并发访问。需要注意的是,禁用中断和启用中断的代码段通常非常短,一般只有几条指令。
5.1.4 调度程序 (Dispatcher)
CPU 调度功能中另一个涉及的组件是调度程序 (dispatcher)。调度程序是一个模块,它将 CPU 核心的控制权交给由 CPU 调度程序选择的进程。该功能涉及以下内容:
从一个进程切换到另一个进程
切换到用户模式
跳转到用户程序的适当位置以恢复该程序
调度程序应该在每次进程切换时被调用。调度程序停止一个进程并启动另一个进程所需的时间被称为调度延迟 (dispatch latency),如图 5.3 所示。

5.2 调度准则 (Scheduling Criteria)
在选择要在特定情况下使用的算法时,我们必须考虑各种算法的特性。
已经提出了许多准则来比较 CPU 调度算法。用于比较的准则的特点可以在算法中产生实质性的差异。要考虑的准则包括以下几点
CPU 利用率 (CPU utilization)。我们希望 CPU 尽可能地保持繁忙。概念上,CPU 利用率可以从 0 到 100%。在一个真实的系统中,它应该在 40%(对于一个轻负载系统)到 90%(对于一个重负载系统)之间变化。(CPU 利用率可以通过
top命令在 Linux、macOS 和 UNIX 系统中观察到。)吞吐量 (Throughput) 单位时间内完成的进程数量,称为吞吐量 (throughput)。对于长进程,这个速率可能几秒钟才完成一个进程;对于短事务,可能每秒完成几十个进程。
周转时间 (Turnaround time)。从单个进程的角度来看,重要的准则是执行该进程需要多长时间。从一个进程提交到该进程完成的时间间隔就是周转时间。周转时间是在就绪队列中等待、在 CPU 上执行以及进行 I/O 操作所花费的时间总和。
等待时间 (Waiting time)。CPU 调度算法不影响一个进程执行或进行 I/O 的时间量。它只影响一个进程在就绪队列中等待的时间量。等待时间就是进程在就绪队列中等待所花费的时间总和。
响应时间 (Response time)。在一个交互式系统中,周转时间可能不是最佳的准则。通常,一个进程可以在相当早的时候产生一些输出,并且可以在向用户输出先前结果的同时继续计算新的结果。因此,另一个衡量标准是从提交一个请求到产生第一个响应所花费的时间。这个衡量标准,称为响应时间,是开始响应所需的时间,而不是输出响应所需的时间。
理想的情况是最大化 CPU 利用率和吞吐量,并最小化周转时间、等待时间和响应时间。在大多数情况下,我们优化的是平均值。然而,在某些情况下,我们更倾向于优化最小值或最大值,而不是平均值。例如,为了保证所有用户都能得到良好的服务,我们可能希望最小化最大响应时间。
研究人员已经指出,对于交互式系统(例如个人电脑桌面或笔记本电脑系统),最小化响应时间的方差 (variance) 比最小化平均响应时间更重要。一个响应时间合理且可预测的系统,可能被认为比一个平均速度更快但变化很大的系统更可取。然而,关于最小化方差的 CPU 调度算法的研究还很少。
5.3 Scheduling Algorithms
CPU 调度处理的是决定就绪队列 (ready queue) 中的哪个进程将被分配到 CPU 核心的问题。尽管大多数现代 CPU 架构具有多个处理核心,但我们将假设只有一个处理核心可用来描述这些调度算法。
5.3.1 First-Come, First-Served Scheduling
最先请求 CPU 的进程将最先获得 CPU 分配。FCFS 策略的实现可以通过 FIFO 队列轻松管理。当一个进程进入就绪队列时,它的 PCB 被链接到队列的末尾。当 CPU 空闲时,它被分配给队列头部的进程。然后,正在运行的进程将从队列中移除。
不利的一面是,FCFS 策略下的平均等待时间通常很长。
此外,请考虑 FCFS 调度在动态情况下的性能。假设我们有一个 CPU 密集型进程和许多 I/O 密集型进程。当进程在系统中流转时,可能会出现以下情况。CPU 密集型进程将获取并占用 CPU。在此期间,所有其他进程将完成其 I/O 并转移到就绪队列中,等待 CPU。当这些进程在就绪队列中等待时,I/O 设备处于空闲状态。最终,CPU 密集型进程完成了其 CPU 突发,并转移到 I/O 设备。所有 I/O 密集型进程(它们具有较短的 CPU 突发)快速执行,然后移回 I/O 队列。此时,CPU 处于空闲状态。接着,CPU 密集型进程将移回就绪队列并被分配 CPU。再一次,所有 I/O 进程最终都会在就绪队列中等待,直到 CPU 密集型进程完成。这就产生了护航效应 (convoy effect),即所有其他进程都在等待那个庞大的进程释放 CPU。这种效应导致的 CPU 和设备利用率,会低于如果允许较短进程先运行所能达到的水平。
还请注意,FCFS 调度算法是非抢占式 (nonpreemptive) 的。一旦 CPU 被分配给一个进程,该进程将一直持有 CPU,直到它释放 CPU 为止——无论是通过终止还是通过请求 I/O。因此,FCFS 算法对于交互式系统尤其麻烦
5.3.2 Shortest-Job-First Scheduling
CPU 调度的另一种方法是最短作业优先 (SJF) 调度算法。此算法将每个进程与其下次 CPU 突发 (next CPU burst) 的长度相关联。当 CPU 可用时,它会被分配给具有最小下次 CPU 突发的进程。如果两个进程的下次 CPU 突发长度相同,则使用 FCFS 调度来打破平局
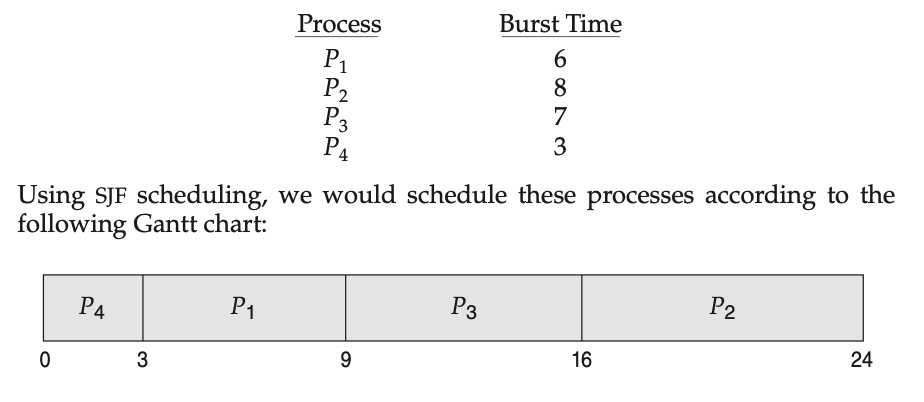
画出其 甘特图 (Gantt chart)
平均等待时间为 (3 + 16 + 9 + 0) / 4 = 7 毫秒 ; 相比之下,如果我们使用 FCFS 调度方案,平均等待时间将为 10.25 毫秒。
SJF 调度算法被证明是最优的,因为它能为给定的一组进程提供最小的平均等待时间。将一个短进程移到一个长进程之前,其缩短的短进程等待时间,会多于其增加的长进程等待时间
尽管 SJF 算法是最优的,但它无法在 CPU 调度层面上实现,因为没有办法知道下次 CPU 突发的长度。解决此问题的一种方法是尝试近似 SJF 调度。我们可能不知道下次 CPU 突发的长度,但我们或许能够预测它的值。下次 CPU 突发的长度通常被预测为先前 CPU 突发测量长度的指数平均 (exponential average)
设 tn 为第 n 次 CPU 突发的长度,并设 τn+1 为我们对下次 CPU 突发的预测值。那么,对于 0 < α < 1,定义:
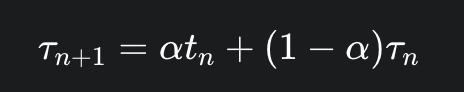
为了理解指数平均的行为,我们可以通过代入公式得到:
 每个连续项的权重都低于其前一项
每个连续项的权重都低于其前一项
SJF 算法可以是抢占式 (preemptive) 或非抢占式 (nonpreemptive) 的。当一个新进程在先前进程仍在执行时到达就绪队列,就需要做出选择。新到达进程的下次 CPU 突发可能比当前正在执行进程的剩余时间还要短。抢占式 SJF 算法将抢占当前正在执行的进程,而非抢占式 SJF 算法将允许当前运行的进程完成其 CPU 突发。抢占式 SJF 调度有时被称为最短剩余时间优先 (shortest-remaining-time-first, SRTF) 调度。
5.3.3 Round-Robin Scheduling
轮转 (Round-Robin, RR) 调度算法类似于 FCFS 调度,但增加了抢占 (preemption) 以使系统能够在进程之间进行切换。它定义了一个称为时间片 (time quantum) 或时间配额 (time slice) 的小时间单元。一个时间片的长度通常为 10 到 100 毫秒。就绪队列被视为一个循环队列。CPU 调度程序会遍历就绪队列,为每个进程分配 CPU,时间间隔最多为 1 个时间片。
为了实现 RR 调度,我们再次将就绪队列视为一个进程的 FIFO 队列。新进程被添加到就绪队列的末尾。CPU 调度程序从就绪队列中选取第一个进程,设置一个定时器以在 1 个时间片后中断,然后分派该进程。
接下来会发生两种情况之一。该进程的 CPU 突发可能小于 1 个时间片。在这种情况下,该进程将自愿释放 CPU。调度程序将接着处理就绪队列中的下一个进程。如果当前运行进程的 CPU 突发大于 1 个时间片,定时器将会到时,并向操作系统引发一个中断。系统将执行一次上下文切换,并将该进程(刚执行完的进程)放到就绪队列的末尾。然后,CPU 调度程序将选择就绪队列中的下一个进程。
RR 策略下的平均等待时间通常很长。


使用 4 毫秒的时间片
时间片 q 的大小必须在两个极端之间找到平衡
如果 q 非常大: RR 算法会退化成先来先服务 (FCFS) 算法。因为时间片足够长,每个进程都能在被抢占之前完成自己的整个 CPU 突发,这就像排队一样,先来的先执行完。
如果 q 非常小(例如 1 毫秒): 会导致大量的上下文切换 (context switches)。
公平性: RR 算法保证了公平性。如果就绪队列中有 n 个进程,时间片为 q,那么每个进程都能保证在 (n-1) q 的时间内至少获得一次 CPU。
5.3.4 Priority Scheduling
SJF 算法是广义的优先级调度 (priority-scheduling) 算法的一个特例。每个进程都有一个相关联的优先级,CPU 被分配给具有最高优先级的进程。具有相同优先级的进程按 FCFS 顺序调度。SJF 算法是一种简单的优先级算法,其优先级 (p) 是(预测的)下次 CPU 突发的倒数。CPU 突发越大,优先级越低,反之亦然。
优先级调度可以是抢占式 (preemptive) 或非抢占式 (nonpreemptive) 的。当一个进程到达就绪队列时,它的优先级会与当前正在运行进程的优先级进行比较。如果新到达进程的优先级高于当前运行进程的优先级,抢占式优先级调度算法将抢占 CPU。非抢占式优先级调度算法只会将新进程放在就绪队列的头部。
优先级调度算法的一个主要问题是无限期阻塞 (indefinite blocking) 或饥饿 (starvation)。一个准备好运行但正在等待 CPU 的进程可以被视为处于阻塞状态。优先级调度算法可能会导致一些低优先级进程无限期地等待。在一个重度负载的计算机系统中,源源不断的高优先级进程会使一个低优先级进程永远无法获得 CPU。
解决低优先级进程无限期阻塞问题的一种方法是老化 (aging)。老化是一种逐渐提高在系统中等待了很长时间的进程的优先级的方法。例如,如果优先级范围从 127(低)到 0(高),我们可以周期性地(比如每秒)将等待进程的优先级提高 1。
4. 另一种选择是将轮转 (round-robin) 和优先级调度结合起来,即系统执行具有最高优先级的进程,并对具有相同优先级的进程使用轮转调度。


5.3.5 Multilevel Queue Scheduling
在同时使用优先级调度和轮转调度时,所有进程都可能被放在一个单一队列中,然后调度程序选择具有最高优先级的进程来运行。根据队列的管理方式,可能需要进行 O(n) 搜索来确定优先级最高的进程。在实践中,为每个不同的优先级设置单独的队列通常更容易,而优先级调度只需调度最高优先级队列中的进程。这种方法——称为多级队列 (multilevel queue)——如图 5.7 所示。当优先级调度与轮转调度(Round-Robin)结合使用时,这种方法也很有效:如果最高优先级队列中有多个进程,它们将按轮转顺序执行。在这种方法最通用的形式中,每个进程被静态地分配一个优先级,并且进程在其整个运行期间都保持在同一个队列中。
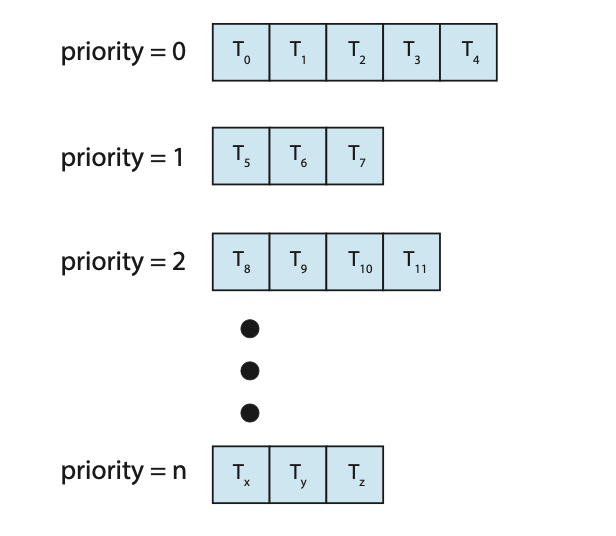
多级队列调度算法还可以用于根据进程类型将进程划分到几个单独的队列中(图 5.8)。例如,一个常见的划分是在前台 (foreground)(交互式)进程和后台 (background)(批处理)进程之间进行的。这两类进程有不同的响应时间要求,因此可能有不同的调度需求。此外,前台进程可能(由外部定义)比较后台进程有更高的优先级。
可以为前台和后台进程使用单独的队列,并且每个队列可以有自己的调度算法。例如,前台队列可以由 RR(轮转)算法调度,而后台队列则由 FCFS(先来先服务)算法调度。

每个队列都比低优先级队列具有绝对优先级。例如,批处理队列中的进程都不能运行,除非实时进程、系统进程和交互式进程的队列都为空。
另一种可能性是在队列之间划分时间片 (time-slice)。这里,每个队列获得一定比例的 CPU 时间,然后它可以在其各个进程之间调度这些时间。例如,在前台-后台队列的例子中,可以给予前台队列 80% 的 CPU 时间用于在其进程间进行 RR 调度,而后台队列则获得 20% 的 CPU 时间,以 FCFS 的方式分配给它的进程。
5.3.6 Multilevel Feedback Queue Scheduling
通常,当使用多级队列调度算法时,进程在进入系统时被永久地分配到一个队列中。例如,如果前台和后台进程有单独的队列,进程并不会从一个队列移动到另一个队列,因为进程不会改变其前台或后台的性质。这种设置具有低调度开销的优点,但是不灵活。
相比之下,多级反馈队列 (multilevel feedback queue) 调度算法允许进程在队列之间移动。其思想是根据进程 CPU 突发的特性来分离进程。如果一个进程使用了过多的 CPU 时间,它将被转移到优先级较低的队列。这种方案将 I/O 密集型进程和交互式进程(它们通常具有较短的 CPU 突发)留在优先级较高的队列中。此外,在低优先级队列中等待时间过长的进程可能会被移至高优先级队列。这种形式的老化 (aging) 可以防止饥饿 (starvation)。
5.4 Thread Scheduling
在第 4 章中,我们在进程模型中引入了线程,区分了用户级 (user-level) 线程和内核级 (kernel-level) 线程。在大多数现代操作系统上,是内核级线程(而不是进程)被操作系统调度。用户级线程由线程库管理,内核对它们的存在一无所知。为了在 CPU 上运行,用户级线程最终必须映射到关联的内核级线程上,尽管这种映射可能是间接的,并且可能使用轻量级进程 (LWP)(light weight process ||||. 用户级线程(User-level Threads)和内核级线程(Kernel-level Threads)之间的一个“中间人”或“桥梁”)。
用户级线程和内核级线程之间的一个区别在于它们的调度方式。在实现多对一 (many-to-one)(第 4.3.1 节)和多对多 (many-to-many)(第 4.3.3 节)模型的系统上,线程库将用户级线程调度到可用的 LWP 上运行。此方案称为进程竞争范围 (process-contention scope, PCS),因为对 CPU 的竞争发生在属于同一进程的线程之间。(当说线程库将用户线程调度到可用的 LWP 上时,我们并不是指这些线程实际在 CPU 上运行,因为这还需要操作系统将 LWP 的内核线程调度到物理 CPU 核心上。)
要决定将哪个内核级线程调度到 CPU 上,内核使用系统竞争范围 (system-contention scope, SCS)。对 CPU 的竞争发生在系统中的所有线程之间。使用一对一 (one-to-one) 模型(第 4.3.2 节)的系统(例如 Windows 和 Linux)仅使用 SCS。
通常,PCS 是根据优先级进行的——调度程序选择具有最高优先级的可运行线程。用户级线程的优先级由程序员设置,并通过线程库进行调整,尽管一些线程库可能允许程序员更改线程的优先级。值得注意的是,PCS 通常会抢占当前正在运行的线程,以利于更高优先级的线程;但是,对于优先级相等的线程,不能保证时间分片(第 5.3.3 节)
5.5 Multi-Processor Scheduling
5.5.1 多处理器调度的方法
在多处理器系统中,对 CPU 调度的一种方法是非对称多处理 (asymmetric multiprocessing),即所有调度决策、I/O 处理和其他系统活动都由一个单独的处理器——主服务器 (master server)——来处理。其他处理器只执行用户代码。这种非对称多处理)之所以简单,是因为只有一个核心访问系统数据结构,从而减少了数据共享的需求。这种方法的缺点是主服务器可能成为潜在的瓶颈,导致系统整体性能下降。
支持多处理器的标准方法是对称多处理 (symmetric multiprocessing, SMP),即每个处理器都是自我调度的。调度由每个处理器的调度程序(Scheduler)执行,该程序检查就绪队列 (ready queue) 并选择一个线程来运行。这就为组织有资格被调度的线程提供了两种可能的策略:
所有线程可能都在一个共同的就绪队列 (common ready queue) 中。
每个处理器都可能有自己的私有线程队列 (private queue)。
这两种策略如图 5.11 所示。如果我们选择第一种方案,我们必须确保共享的就绪队列不会出现竞争条件 (race condition),因此必须确保两个单独的处理器不会选择调度同一个线程,并且线程不会从队列中丢失。
Chapter 9 Main Memory
9.1 Background
9.1.1 Basic Hardware
内置于每个 CPU 核心的寄存器通常在一个 CPU 时钟周期内即可访问。一些 CPU 核心可以以每时钟周期一次或多次操作的速率解码指令并对寄存器内容执行简单操作。但主存却非如此,主存需要通过内存总线上的事务来访问。完成一次内存访问可能需要花费许多个 CPU 时钟周期。在这种情况下,处理器通常需要等待,因为它没有所需的数据来完成它正在执行的指令。这种情况是不受欢迎的,因为内存访问非常频繁。补救措施是在 CPU 和主存之间添加快速内存,通常位于 CPU 芯片上以便快速访问。这种高速缓存 (cache) 已在 1.5.5 节中描述过。为了管理内置于 CPU 的缓存,硬件会自动加速内存访问,无需任何操作系统的控制。
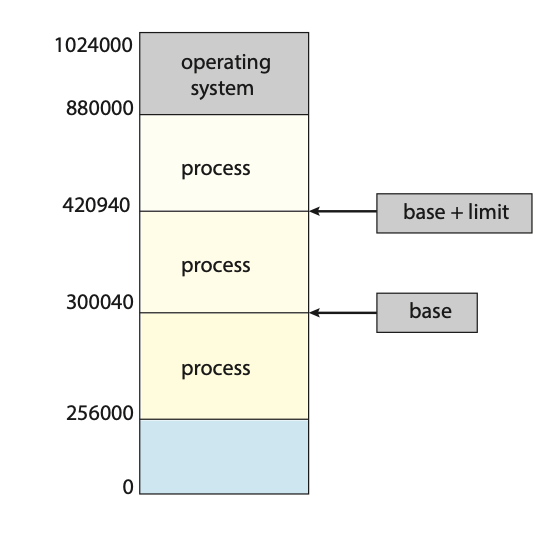
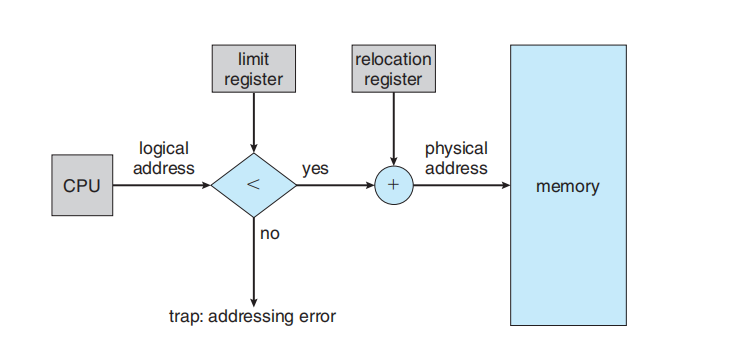
一个内存布局, 操作系统位于顶部, 一个进程位于中间 ; 基址 (base) 指向 300040,基址+界限 (base + limit) 指向 420940; 基址寄存器和界限寄存器定义了一个逻辑地址空间。
为了分离内存空间,我们需要有能力确定进程可以访问的合法地址范围,并确保进程只能访问这些合法地址。我们可以通过使用两个寄存器(通常是基址寄存器 (base register) 和界限寄存器 (limit register))来提供这种保护
基址寄存器存放最小的合法物理内存地址;界限寄存器指定了该范围的大小
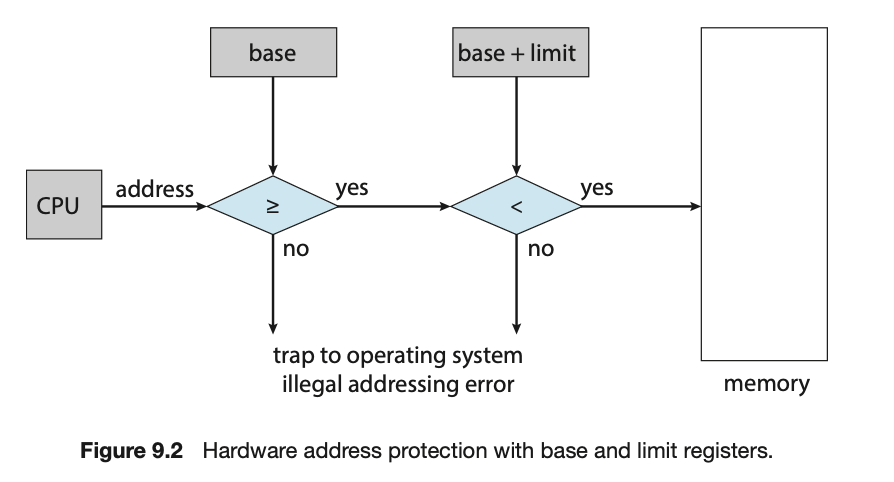
内存空间的保护是通过 CPU 硬件将来用户模式下生成的每个地址与这些寄存器进行比较来实现的。在用户模式下执行的程序任何试图访问操作系统内存或其他用户内存的尝试都会导致陷入 (trap) 操作系统,操作系统会将这种尝试视为致命错误(图 9.2)。这种机制防止了用户程序(无论是意外还是故意)修改操作系统或其他用户的代码或数据结构。
基址寄存器和界限寄存器只能由操作系统通过特殊的特权指令 (privileged instruction) 来加载。由于特权指令只能在内核模式 (kernel mode) 下执行,并且只有操作系统在内核模式下执行,因此只有操作系统才能加载基址寄存器和界限寄存器。这种机制允许操作系统更改寄存器的值,但防止用户程序更改寄存器的内容。
在内核模式下执行的操作系统被赋予了对操作系统内存和用户内存的不受限制的访问权限。这项规定允许操作系统将用户程序加载到用户内存中,在程序出错时转储这些程序,访问和修改系统调用的参数,执行进出用户内存的 I/O,以及提供许多其他服务。例如,考虑一个用于多处理系统的操作系统必须执行上下文切换,将一个进程的状态从寄存器存储到主存中,然后再将下一个进程的上下文从主存加载到寄存器中。
9.1.2 Address Binding
通常,程序作为二进制可执行文件驻留在磁盘上。为了运行,程序必须被调入内存,并置于一个进程的上下文中(如 2.5 节所述),在那里它才有资格在可用的 CPU 上执行。当进程执行时,它会从内存中访问指令和数据。最终,进程终止,其内存被回收以供其他进程使用。
大多数系统允许用户进程驻留在物理内存的任何部分。因此,尽管计算机的地址空间可能从 00000 开始,但用户进程的第一个地址不必是 00000。稍后你将看到操作系统实际上是如何将一个进程放入物理内存的。
在大多数情况下,一个用户程序在被执行前会经历几个步骤——其中一些可能是可选的(图 9.3)。在这些步骤中,地址可能以不同的方式表示。在源程序中的地址通常是符号化的(例如变量
count)。编译器 (compiler) 通常将这些符号地址绑定 (binds) 到可重定位地址 (relocatable addresses)(例如“距本模块开头 14 字节”)。接着,链接器 (linker) 或加载器 (loader)(见 2.5 节)将可重定位地址绑定到绝对地址 (absolute addresses)(例如 74014)。每个绑定都是从一个地址空间到另一个地址空间的映射。
经典地,指令和数据到内存地址的绑定可以在过程中的任何一步完成:
编译时 (Compile time)。 如果在编译时就知道进程将驻留在内存中的什么位置,那么就可以生成绝对代码 (absolute code)。例如,如果你知道一个用户进程将驻留在从位置 R 开始的地方,那么生成的编译器代码将从该位置开始并向上扩展。如果将来起始位置发生变化,则有必要重新编译此代码。
加载时 (Load time)。 如果在编译时不知道进程将驻留在内存中的什么位置,那么编译器必须生成可重定位代码 (relocatable code)。在这种情况下,最终的绑定会延迟到加载时。如果起始地址发生变化,我们只需要重新加载用户代码以合并这个已更改的值。
执行时 (Execution time)。 如果进程在执行期间可以从一个内存段移动到另一个内存段,那么绑定必须延迟到运行时 (run time)。这种方案需要特殊的硬件支持才能工作,我们将在 9.1.3 节中讨论。大多数操作系统都使用这种方法
9.1.3 Logical Versus Physical Address Space
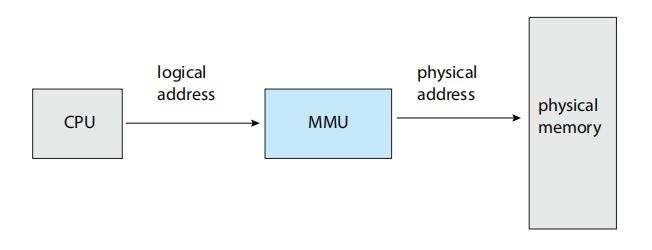
由CPU生成的地址通常称为逻辑地址 (logical address),而内存单元所看到的地址——即加载到内存的内存地址寄存器中的地址——通常称为物理地址 (physical address)。
在编译时或加载时绑定地址会产生相同的逻辑地址和物理地址。然而,运行时地址绑定方案则会导致逻辑地址和物理地址不同。在这种情况下,我们通常将逻辑地址称为虚拟地址 (virtual address)。在本书中,我们交替使用逻辑地址和虚拟地址。
基址寄存器现在被称为重定位寄存器 (relocation register)。在用户进程生成的每个地址发送到内存时,重定位寄存器中的值都会被加到该地址上; 例如,如果基址是 14000,那么用户访问 0 地址的尝试将被动态重定位到 14000 地址;对 346 地址的访问将被映射到 14346 地址
用户程序永远不会看到真实的物理地址。程序可以创建一个指向 346 地址的指针,将其存储在内存中,操作它,并将其与其他地址进行比较——所有这些都是基于 346 这个数值。只有当它被用作内存地址时(也许是在间接加载或存储中),它才会相对于基址寄存器进行重定位。用户程序处理的是逻辑地址。内存映射硬件将逻辑地址转换为物理地址。
9.1.4 Dynamic Loading
在我们到目前为止的讨论中,一个进程的整个程序和所有数据都必须在物理内存中,进程才能执行。因此,进程的大小受到了物理内存大小的限制。为了更好地利用内存空间,我们可以使用动态加载 (dynamic loading)。使用动态加载时,一个例程(routine)直到它被调用时才会被加载。所有的例程都以可重定位的加载格式保存在磁盘上。主程序被加载到内存中并执行。当一个例程需要调用另一个例程时,调用例程首先检查另一个例程是否已经被加载。如果没有,可重定位链接加载器(relocatable linking loader)就会被调用,将所需的例程加载到内存中,并更新程序的地址表以反映这一变化。然后控制权就传递给新加载的例程。
动态加载的优点是例程只在需要时才被加载。当需要处理不经常发生的(infrequently occurring)情况(例如错误例程)的大量代码时,此方法特别有用。在这种情况下,尽管程序总大小可能很大,但实际使用(并因此加载)的部分可能会小得多。
9.1.5 Dynamic Linking and Shared Libraries
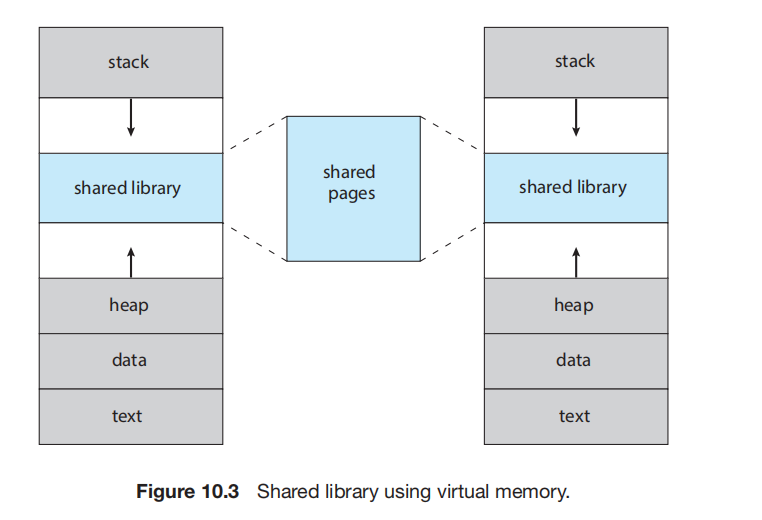
动态链接库 (Dynamically linked libraries, DLLs) 是在用户程序运行时才链接到程序中的系统库。动态链接,类似于动态加载,是将链接(而非加载)的过程推迟到执行时。这个特性通常用于系统库,例如标准 C 语言库。
如果没有这个特性,系统上的每个程序都必须在其可执行镜像中包含一份 C 语言库的副本(或者至少是程序引用的那些例程)。这个要求不仅增加了可执行镜像的大小,而且还可能浪费主存。DLL 的第二个优势是这些库可以在多个进程之间共享,因此主内存中只需要存在 DLL 的一个实例。因此,DLL 也被称为共享库 (shared libraries),它们在 Windows 和 Linux 系统中被广泛使用。
动态链接库可以通过库更新(例如错误修复)进行扩展。此外,一个库可以被一个新版本替换,所有引用该库的程序将自动使用新版本。如果没有动态链接,所有这些程序都需要重新链接才能使用新库。
与动态加载不同,动态链接和共享库通常需要操作系统的帮助。如果内存中的进程是相互保护的,那么操作系统是唯一可以检查所需例程是否在另一个进程的内存空间中,或者是否允许多个进程访问相同内存地址的实体。
9.2 Contiguous Memory Allocation
9.2.1 Memory Protection
如果我们有一个带有重定位寄存器(9.1.3 节)和界限寄存器(limit register)(9.1.1 节)的系统,我们就能实现我们的目标。重定位寄存器包含最小的物理地址值; 每个逻辑地址都必须落在界限寄存器指定的范围之内。MMU 通过将逻辑地址与重定位寄存器中的值相加来动态映射逻辑地址。这个映射后的地址被发送到内存
当 CPU 调度程序选择一个进程来执行时,分派器(dispatcher)会作为上下文切换的一部分,将正确的重定位寄存器和界限寄存器的值加载进去。因为 CPU 生成的每个地址都会对照这些寄存器进行检查,所以我们既可以保护操作系统,也可以保护其他用户的程序和数据,使其免受这个正在运行的进程的修改。
重定位寄存器方案提供了一种有效的方法,允许操作系统的大小动态变化。(因为可以重定向,因此可以不连续)
9.2.2 Memory Allocation
现在我们转向内存分配。最简单的内存分配方法之一是为进程分配可变大小的分区 (variably sized partitions),其中每个分区可能只包含一个进程。在这种可变分区 (variable-partition) 方案中,操作系统维护一个表,指明内存的哪些部分是可用的,哪些部分已被占用。最初,所有内存都可供用户进程使用,并被视为一整块可用内存,即一个“空闲块” (hole)。最终,如您将看到的,内存会包含一组大小各异的空闲块。

这个过程是动态存储分配问题 (dynamic storage-allocation problem) 的一个特例,该问题关注如何从一组空闲块列表中满足大小为 n 的请求。解决这个问题有多种方案。首次适应 (first-fit)、最佳适应 (best-fit) 和最差适应 (worst-fit) 策略是三种最常用于从可用空闲块集合中选择一个空闲块的策略。
首次适应 (First fit): 分配第一个足够大的空闲块。搜索可以从空闲块集合的开头开始,也可以从上次首次适应搜索结束的位置开始。只要我们找到一个足够大的空闲块,就可以停止搜索。
最佳适应 (Best fit): 分配那个足够大的、且是最小的空闲块。我们必须搜索整个列表,除非列表是按大小排序的。这种策略会产生最小的剩余空闲块。
最差适应 (Worst fit): 分配最大的空闲块。同样,我们必须搜索整个列表,除非它是按大小排序的。这种策略会产生最大的剩余空闲块,这个剩余块可能比最佳适应方法产生的小剩余块更有用。
9.2.3 Fragmentation
首次适应和最佳适应两种内存分配策略都会产生外部碎片 (external fragmentation)。随着进程被加载和移出内存,空闲的内存空间被分割成许多小块。当总的可用内存空间足以满足一个请求,但这些可用空间是不连续的时,就出现了外部碎片(external fragmentation)
考虑一个多分区分配方案,其中有一个 18,464 字节的空闲块。假设下一个进程请求 18,462 字节。如果我们精确地分配所请求的块,我们将留下一个 2 字节的空闲块。用于跟踪这个空闲块的开销可能会远远大于这个空闲块本身。避免这个问题的一般方法是将物理内存划分为固定大小的块,并以块为单位进行内存分配。这样一来,分配给进程的内存可能会比请求的内存稍大。这两者之间的差额就是内部碎片 (internal fragmentation)——即分区内部未被使用的内存。
解决外部碎片问题的一种方法是紧缩 (compaction)。其目标是重新挪动内存内容,以便将所有空闲内存合并成一个大的空闲块。
解决外部碎片问题的另一种可能方案是允许进程的逻辑地址空间是非连续的 (noncontiguous),从而允许一个进程在物理内存可用时被分配到任何可用的物理内存位置。这就是分页 (paging) 中使用的策略
9.3 Paging
9.3.1 Basic
实现分页的基本方法包括将物理内存分割成固定大小的块,称为帧 (frames),并将逻辑内存也分割成相同大小的块,称为页 (pages)。当一个进程要执行时,它的页(pages)会从它们的源(文件系统或后备存储)加载到任何可用的内存帧(frames)中。后备存储被划分为固定大小的块,其大小与内存帧相同(或为帧的倍数簇)。这个简单的想法具有强大的功能和深远的影响。例如,逻辑地址空间现在与物理地址空间完全分离,因此一个进程可以拥有一个逻辑上的 64 位地址空间,即使系统只有 232 字节的物理内存。
...略
通常,在 32 位 CPU 上,每个页表条目(PTE)为 4 字节长,但这个大小也可能变化。一个 32 位的条目可以指向 232个物理页帧中的一个。如果帧大小为 4 KB (212,)那么一个带有 4 字节条目的系统可以寻址 244 字节(或 16 TB)的物理内存。我们在这里应该注意,分页内存系统中的物理内存大小通常与进程的最大逻辑大小不同。随着我们进一步探索分页,我们将引入必须保存在页表条目中的其他信息。这些信息减少了可用于寻址页帧的位数。因此,一个具有 32 位页表条目的系统可能寻址的物理内存会小于可能的最大值
当一个进程到达系统准备执行时,系统会检查它的大小(以页为单位)。进程的每一页都需要一个帧。因此,如果进程需要 n 页,内存中必须至少有 n 个可用的帧。如果有 n 个可用的帧,它们就会被分配给这个到达的进程。

操作系统为每个进程维护一个页表的副本,就像它维护指令计数器和寄存器内容的副本一样。每当操作系统需要手动将逻辑地址映射到物理地址时,就会使用这个副本。当一个进程要被分配 CPU 时,CPU 调度程序也会使用它来定义硬件页表。因此,分页增加了上下文切换的时间。
9.3.2 Hardware Support
由于页表是每个进程一个的数据结构,指向页表的指针会与(像指令指针一样的)其他寄存器值一起,存储在每个进程的进程控制块(process control block)中。当 CPU 调度程序选择一个进程来执行时,它必须重新加载用户寄存器,并从存储的用户页表中加载相应的硬件页表值
页表的硬件实现可以通过几种方式完成。在最简单的情况下,页表被实现为一组专用的高速硬件寄存器,这使得页地址转换非常高效。然而,这种方法增加了上下文切换时间,因为在上下文切换期间,这些寄存器中的每一个都必须被交换。
如果页表相当小(例如,256 个条目),使用寄存器来实现页表是令人满意的。然而,大多数现代 CPU 支持大得多的页表(例如,220 个条目)。对于这些机器,使用快速寄存器来实现页表是不可行的。取而代之的是,页表保存在主内存中,并由一个页表基址寄存器 (page-table base register, PTBR) 指向该页表。切换页表只需要更改这一个寄存器,从而大大减少了上下文切换时间。
9.3.2.1 转译后备缓冲器 (Translation Look-Aside Buffer)
尽管将页表存储在主内存中可以加快上下文切换,但它也可能导致更慢的内存访问时间。假设我们要访问位置 i。我们必须首先索引页表,使用 PTBR 寄存器中的值并以 i 的页号作为偏移。这个任务需要一次内存访问。它为我们提供了帧号,帧号与页偏移组合以产生实际地址。然后我们就可以访问内存中所需的位置。使用这种方案,访问一个数据需要两次内存访问(一次用于获取页表条目,一次用于获取实际数据)。因此,内存访问慢了一倍(a factor of 2),这种延迟在大多数情况下被认为是无法忍受的。
这个问题的标准解决方案是使用一种特殊的、小型的、可快速查找的硬件缓存,称为转译后备缓冲器 (translation look-aside buffer, TLB)。TLB 是一种相联(associative)高速内存。
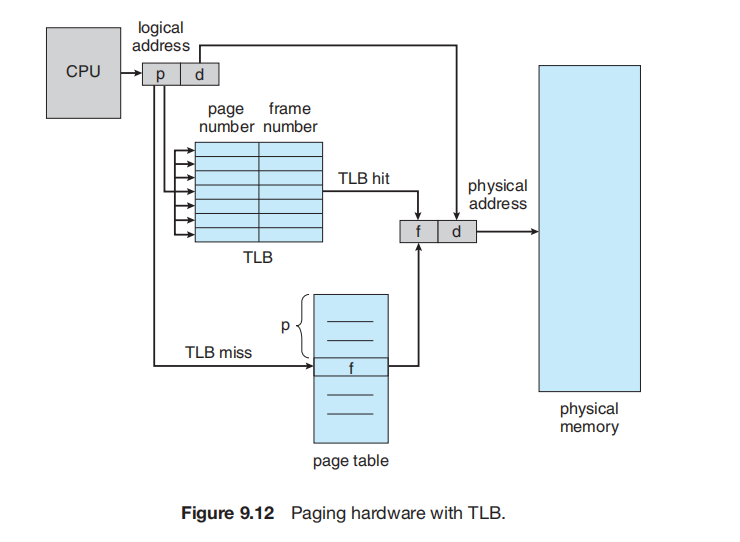
一些 TLB 在每个 TLB 条目中存储地址空间标识符 (address-space identifier, ASID)。ASID 唯一地标识每个进程,并用于为该进程提供地址空间保护。当 TLB 尝试解析虚拟页号时,它会确保当前运行进程的 ASID 与该虚拟页关联的 ASID 相匹配。如果 ASID 不匹配,则该尝试被视为 TLB 未命中。除了提供地址空间保护外,ASID 还允许 TLB 同时包含多个不同进程的条目。如果 TLB 不支持独立的 ASID,那么每当选择一个新的页表时(例如,每次上下文切换时),TLB 都必须被刷新 (flushe)(或清空),以确保下一个执行的进程不会使用错误的转换信息。否则,TLB 可能会包含一些旧的条目,这些条目虽然包含有效的虚拟地址,但却留下了前一个进程的不正确或无效的物理地址。
9.4 Structure of the Page Table
9.4.1 Hierarchical Paging
大多数现代计算机系统支持大型逻辑地址空间(232 到 264)。在这样的环境中,页表本身可能会变得异常庞大。例如,考虑一个 32 位逻辑地址空间的系统。如果该系统的页面大小为 4 KB (212),那么一个页表就可能包含超过 100 万个条目(232 / 212 = 220)。假设每个条目占用 4 字节,那么每个进程可能需要高达 4 MB 的物理地址空间来存储页表。
一个简单的解决方案是将页表分成更小的片段。我们可以通过多种方式来完成这个任务。因为地址转换是从外部页表向内进行的,所以这种方案也称为前向映射页表 (forward-mapped page table)。
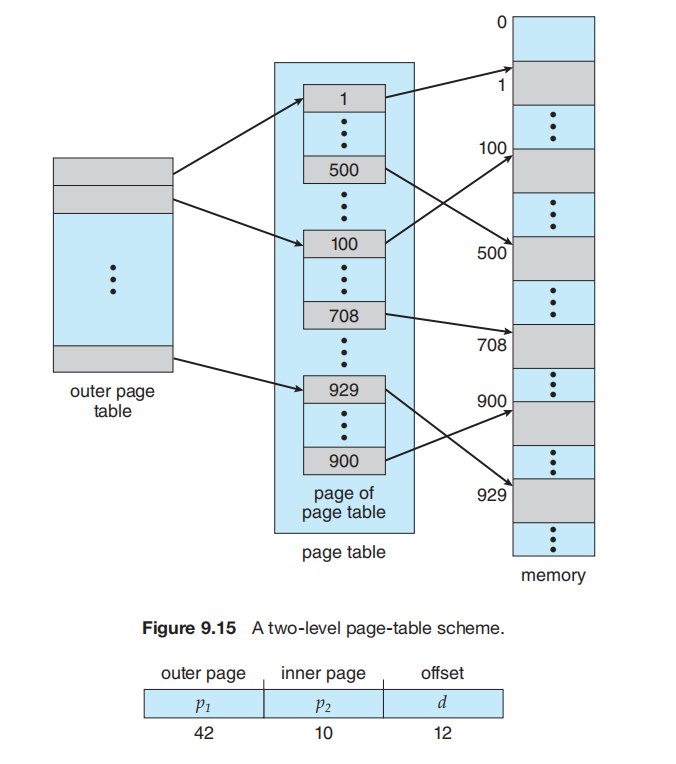
对于 64 位架构,分层页表通常被认为是不合适的。
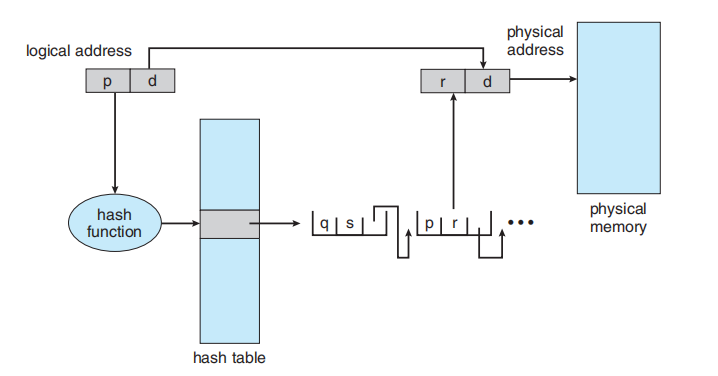
9.4.2 Hashed Page Tables
处理大于 32 位地址空间的一种方法是使用哈希页表 (hashed page table),其哈希值就是虚拟页号。哈希表中的每个条目都包含一个链表,链表中的元素都哈希到同一位置(用于处理冲突)。每个元素都包含三个字段:(1) 虚拟页号,(2) 映射的页帧的值,以及 (3) 指向链表中下一个元素的指针。
该算法的工作原理如下:虚拟地址中的虚拟页号被哈希到哈希表中。将这个虚拟页号与链表中第一个元素的字段 1 进行比较。如果匹配,则使用相应的页帧(字段 2)来构成所需的物理地址。如果不匹配,则在链表中搜索后续条目,以查找匹配的虚拟页号。
9.4.3 Inverted Page Tables
图片内容:CPU 生成逻辑地址,分为 pid (进程ID), p (页号), d (页偏移)。系统使用 pid 和 p 在“页表”(page table) 中进行“搜索”(search)。如果找到匹配的 [pid, p] 条目(位于索引 i),则 i 就是帧号。i 和偏移 d 组合成物理地址,指向“物理内存”(physical memory)。
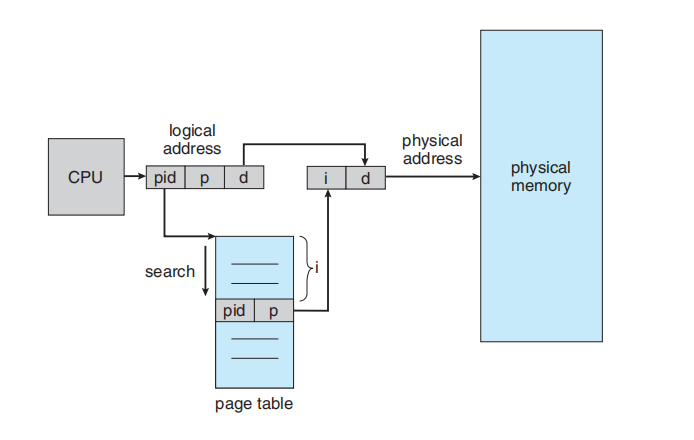
尽管此方案减少了存储每个页表所需的内存量,但它增加了在发生页面引用时搜索表所需的时间。因为反向页表是按物理地址排序的,但查找是按虚拟地址进行的;依次按物理地址遍历,不断比对value和已有的虚拟地址
9.5 Swapping
进程的指令和它们操作的数据必须在内存中才能执行。然而,一个进程(或进程的一部分)可以被暂时交换 (swapped) 出内存,存放到一个后备存储 (backing store) 中,然后在需要继续执行时再被换回内存(图 9.19)。交换技术使得所有进程的总物理地址空间可以超过系统的真实物理内存,从而提高了系统的多道程序设计 (multiprogramming) 程度。
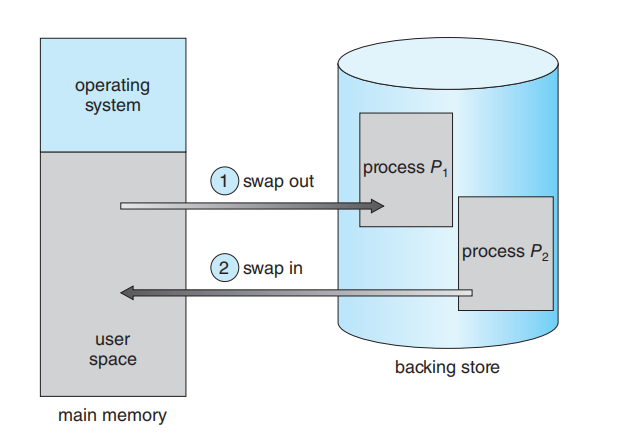
9.5.1 标准交换 (Standard Swapping)
标准交换 (Standard swapping) 涉及将进程在主存和后备存储 (backing store) 之间移动。后备存储通常是一个快速的二级存储设备,比如 SSD。它必须足够大,以容纳所有用户进程的内存映像副本,并且必须能提供对这些内存映像的直接访问。
当一个进程或其一部分被交换到后备存储时,与该进程相关联的数据结构也必须随之被交换。对于一个多线程进程,所有每个线程的(per-thread)数据结构也必须被换出。操作系统还必须维护那些已被换出到后备存储的进程的元数据。当一个进程被换回内存时,这些数据结构必须被恢复。
标准交换的优势在于它允许物理内存被“超额订阅”(oversubscribed)
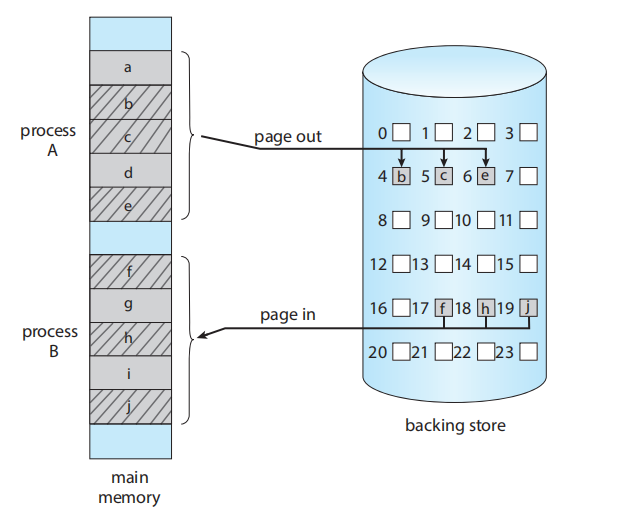
9.5.2 页交换 (Swapping with Paging)
标准交换曾在传统的 UNIX 系统中使用,但现在通常不再用于当代操作系统,因为它在移动整个进程时所需的时间太长,而且后备存储是磁盘
然而,包括 Linux 和 Windows 在内的大多数系统,现在使用标准交换的一种变体,即换出进程的部分页面 (pages)——而不是整个进程。这种策略仍然允许物理内存被超额订阅,但不会招致交换整个进程的昂贵代价。事实上,这个术语现在有点用词不当。页换出 (paging out) 指的是将一个页面从内存移动到后备存储。页换入 (paging in) 指的是从后备存储移动一个页面到内存。
9.6 Example: Intel 32- and 64-bit Architectures
9.6.1 IA-32 架构
IA-32 系统中的内存管理分为两个部分——分段 (segmentation) 和 分页 (paging)——其工作原理如下:CPU 生成逻辑地址 (logical addresses),并将其交给分段单元。分段单元为每个逻辑地址生成一个线性地址 (linear address)。然后,线性地址被交给分页单元,分页单元再生成主存中的物理地址 (physical address)。因此,分段和分页单元共同构成了内存管理单元 (MMU) 的等价物。
IA-32 架构允许一个段 (segment) 大小达到 4 GB,每个进程最多可有 16 K 个段。一个进程的逻辑地址空间被分为两个分区。第一个分区包含最多 8 K 个该进程私有的段。第二个分区包含最多 8 K 个所有进程共享的段。关于第一个分区的信息保存在局部描述符表 (LDT) 中;关于第二个分区的信息保存在全局描述符表 (GDT) 中。LDT 和 GDT 中的每个条目都是一个 8 字节的段描述符 (segment descriptor),包含特定段的详细信息,包括该段的基地址 (base location) 和界限 (limit)。
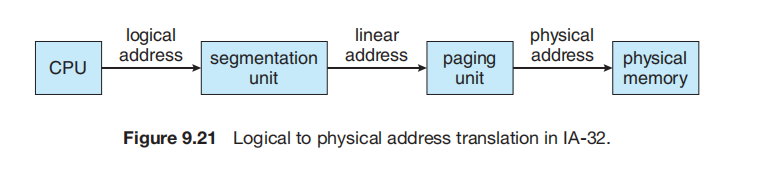
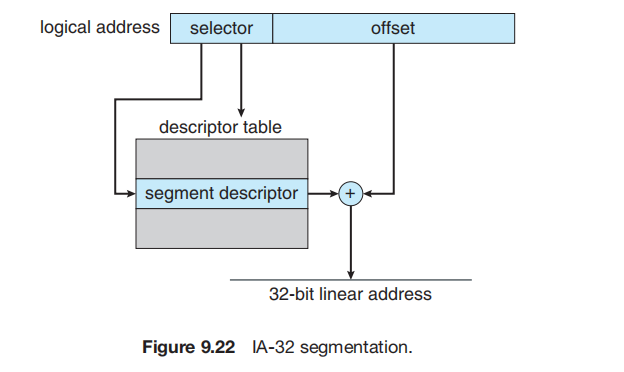
逻辑地址是一个对 (selector, offset),其中选择子 (selector) 是一个 16 位的数字:s (13 位), g (1 位), p (2 位);在这里,s 指定段号,g 指示该段是在 GDT 还是 LDT 中,p 涉及保护。
Chapter 10 Virtual Memory
10.1 Background
第 9 章中概述的内存管理算法是必需的,因为一个基本要求是:正在执行的指令必须在物理内存中。满足此要求的第一个方法是将整个逻辑地址空间放入物理内存。动态链接 (Dynamic linking) 可以帮助放宽这一限制,但它通常需要程序员采取特殊的预防措施。
“指令必须在物理内存中”这一要求似乎是必要且合理的,但不幸的是,它限制了程序的大小,使其不能超过物理内存的大小。即使在需要整个程序的情况下,也可能不需要同时需要它的所有部分。
执行一个仅部分驻留在内存中的程序的能力将带来许多好处:
程序将不再受限于可用物理内存的数量。用户将能够为极其巨大的虚拟地址空间编写程序,从而简化编程任务。
由于每个程序占用的物理内存更少,更多的程序可以同时运行,这会相应地提高 CPU 利用率和吞吐量,但不会增加响应时间或周转时间。
加载或交换程序(或程序的一部分)进出内存所需的 I/O 将会减少,从而使程序运行得更快。
虚拟内存 (Virtual memory) 涉及将开发人员感知的逻辑内存 (logical memory) 与物理内存 (physical memory) 分离。这种分离允许在只有较小物理内存可用的情况下,为程序员提供一个极其巨大的虚拟内存
我们允许堆 (heap) 在用于动态内存分配时在内存中向上增长。同样,我们也允许栈 (stack) 通过连续的函数调用在内存中向下增长。堆和栈之间的大片空白空间(或空洞)是虚拟地址空间的一部分,但只有在堆或栈增长时,它才需要实际的物理页面。包含空洞的虚拟地址空间被称为稀疏地址空间 (sparse address spaces)。使用稀疏地址空间是有益的,因为当栈或堆段增长时,或者当我们在程序执行期间希望动态链接库(或可能的其他共享对象)时,这些空洞可以被填补。
10.2 Demand Paging
10.2.1 Basic Concepts
思考可执行程序如何从二级存储加载到内存。一种选择是在程序执行时将整个程序加载到物理内存。然而,这种方法的一个问题是,我们最初可能并不需要程序的所有部分都在内存中。
另一种策略是只在需要时才加载页面。这项技术被称为请求分页 (demand paging),在虚拟内存系统中被普遍使用。通过请求分页,页面只在程序执行期间被请求 (demanded) 时才被加载。那些从未被访问过的页面就永远不会被加载到物理内存中。
当一个进程在执行时,它的一些页面会在内存中,而另一些会在二级存储中。因此,我们需要某种形式的硬件支持来区分这两者。第 9.3.3 节中描述的有效-无效位 (valid-invalid bit) 方案可以用于此目的
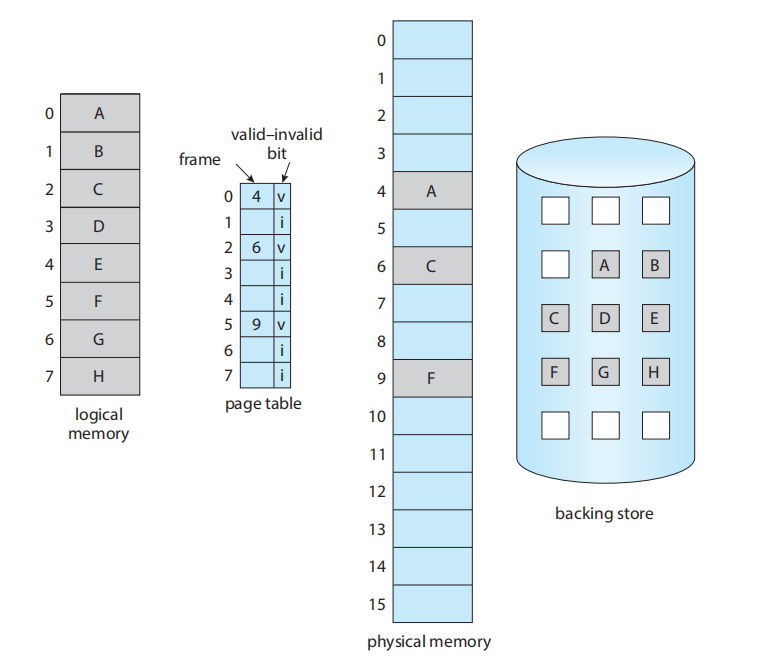
后备存储 (backing store) 包含了所有页面 A 到 H 的副本。
当该位被设置为“有效”(valid) 时,关联的页面既是合法的 (legal),也是在内存中的。如果该位被设置为“无效”(invalid),则该页面要么是无效的(即,不在进程的逻辑地址空间中),要么是有效的、但当前在二级存储中。当一个页面被调入内存时,其页表条目会像往常一样被设置,但是,对于一个当前不在内存中的页面,其页表条目会简单地被标记为无效。
但是,如果进程试图访问一个尚未调入内存的页面,会发生什么呢?对标记为无效的页面的访问会导致页错误 (page fault)。分页硬件在通过页表转换地址时,会注意到无效位被设置,从而引发一个对操作系统的陷阱 (trap)。这个陷阱是操作系统为响应将所需页面调入内存的失败而产生的。处理这种页错误的过程很直接:
我们检查一个内部表(通常保存在该进程的进程控制块 (process control block) 中),以确定该引用是合法的,还是一个非法的内存访问。
如果引用是无效的(非法的),我们终止该进程。如果它是有效的、但我们尚未调入该页面,我们现在就将它调入 (page in)。
我们找到一个空闲帧 (free frame)(例如,从空闲帧列表中取一个 ( 在 physical memory ))。
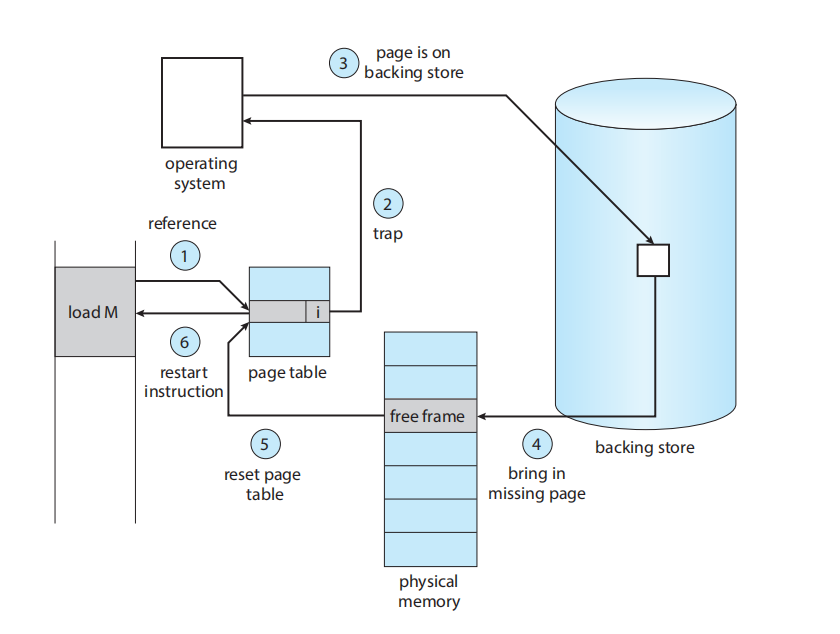
10.2.2 Free-Frame List
当页错误 (page fault) 发生时,操作系统必须将所需的页面从二级存储调入主存。为了解决页错误,大多数操作系统维护一个空闲帧列表 (free-frame list),这是一个用于满足此类请求的空闲帧池(图 10.6)
当系统启动时,所有可用内存都被放置在空闲帧列表上。当空闲帧被请求时(例如,通过请求分页),空闲帧列表的大小会缩小。在某个时刻,该列表要么会减少到零,要么会低于某个阈值,此时它必须被重新填充。

10.2.3 Performance of Demand Paging
请求分页会极大地影响计算机系统的性能。要了解原因,让我们来计算一下请求分页内存的有效访问时间 (effective access time)。假设内存访问时间(记为 ma)为 10 纳秒。只要我们没有页错误,有效访问时间就等于内存访问时间。然而,如果发生了页错误,我们必须首先从二级存储中读取相关的页面,然后才能访问所需的字

我们看到,有效访问时间与页错误率 (page-fault rate) 成正比。如果 1,000 次访问中有 1 次导致页错误,有效访问时间就是 8.2 微秒 (microseconds)。计算机会因为请求分页而慢 40 倍!
10.3 Copy-on-Write
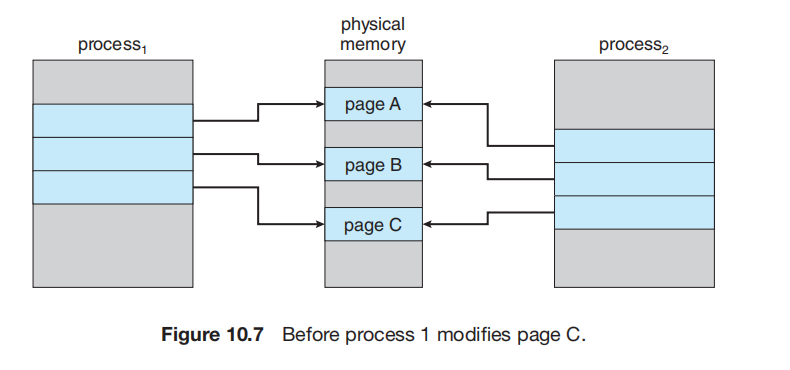
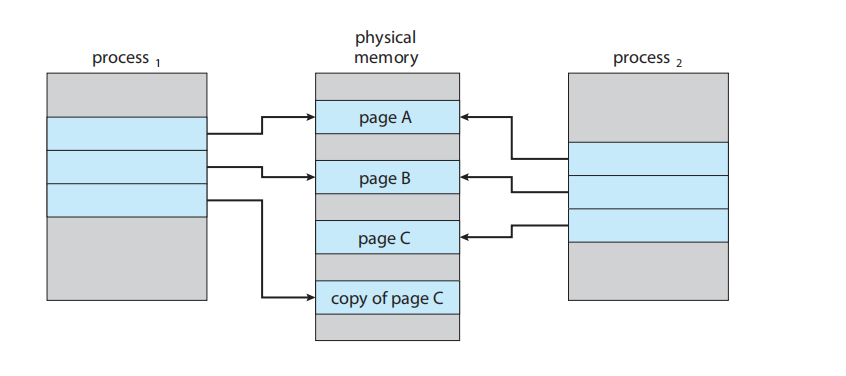
我们可以使用一种称为写时复制 (copy-on-write, COW) 的技术,它通过允许父进程和子进程最初共享相同的页面来工作。这些共享页面被标记为“写时复制”页面,这意味着如果任一进程(父进程或子进程)写入一个共享页面,系统就会创建该共享页面的一个副本
例如,假设子进程试图修改一个包含部分栈 (stack) 内容的页面,而这些页面被设置为写时复制。操作系统将从空闲帧列表中获取一个帧,并创建一个这个页面的副本,将其映射到子进程的地址空间。子进程随后将修改其复制的页面,而不是修改属于父进程的那个页面。
10.4 Page Replacement
10.4.1 Basic Page Replacement
请求分页 (Demand Paging) 允许我们提高多道程序设计程度 (degree of multiprogramming)。
我们可以将内存超额分配 (over-allocating):例如,即使我们只有 40 帧 (frames) 物理内存,我们也可以同时运行 8 个进程,每个进程的(理论)最大大小为 10 帧(总共 80 帧)
“超额分配”的风险: 如果所有 8 个进程突然都需要它们的第 6 帧,系统就会发生页错误 (page fault),但此时会遇到一个“危机“;操作系统去空闲帧列表 (free-frame list) 查找,却发现没有空闲帧。所有物理内存都已被占用。

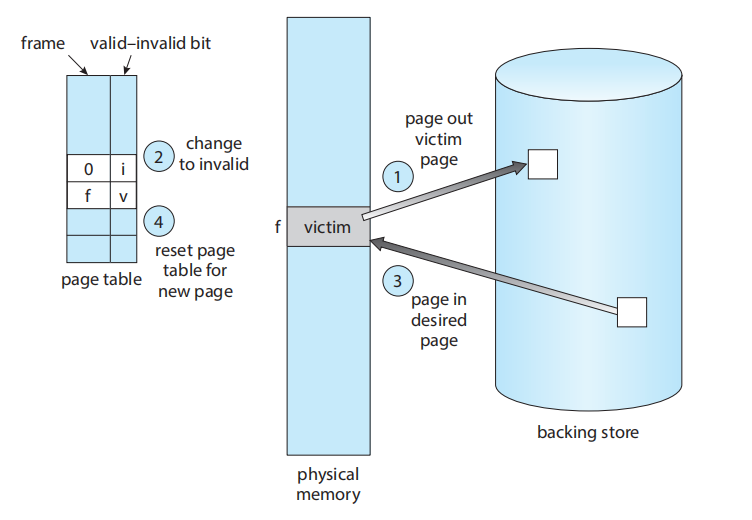
当没有空闲帧时,操作系统不能简单地终止进程(这是最差的选择)或换出整个进程(这太慢了)。它会执行页面置换。
如果没有空闲帧,就使用页面置换算法 (page-replacement algorithm) 来选择一个“受害帧” (victim frame); 将“受害帧”(Page H)的内容写回 (write) 到二级存储(如果它被修改过的话,即“变脏了”);相应地更改 Page H 的页表(例如,在进程 2 的页表中将 Page H 标记为 'i')。现在,帧 4 空闲了; 将所需页面 (Page B) 读入新释放的帧中(即帧 4)。并相应地更改 Page B 的页表(在进程 1 的页表中,将 Page B 标记为 'v',帧号为 4)
如果没有空闲帧,就需要两次页面传输(一次用于页换出 (page-out),一次用于页换入 (page-in))。这种情况实际上使页错误服务时间 (page-fault service time) 翻倍,并相应地增加了有效访问时间 (effective access time)。
我们可以通过使用修改位 (modify bit)(或称脏位 (dirty bit))来减少这种开销。如果修改位没有被设置,那么该页面自从被读入内存后就没有被修改过。在这种情况下,我们不需要将该内存页面写回存储; 因此,在需要时它们可以直接被丢弃 (discarded)。这种方案可以显著减少服务页错误所需的时间,因为如果页面未被修改,它就将 I/O 时间减少了一半。
要实现请求分页 (demand paging),我们必须解决两个主要问题:我们必须开发一个帧分配算法 (frame-allocation algorithm) 和一个页面置换算法 (page-replacement algorithm)。也就是说,如果内存中有多个进程,我们必须决定给每个进程分配多少帧 (frames);并且当需要页面置换时,我们必须选择要被置换的帧。
有许多不同的页面置换算法。每个操作系统都可能有自己的置换方案。我们如何选择一个特定的置换算法呢?总的来说,我们希望选择页错误率 (page-fault rate) 最低的那一个
10.4.2 FIFO Page Replacement

看起来这个 FIFO算法,对于 已经在页中并且再访问一次的frame,不会把它标记成最近一次in的
Belady 异常: 对于某些页面置换算法,当分配的页框数量增加时,缺页率反而可能增加
10.4.3 Optimal Page Replacement
替换掉在未来最长时间内不会被使用的页面。
使用这种页面置换算法,可以保证在固定数量的页框下获得最低的缺页率。
不幸的是,最佳页面置换算法很难实现,因为它需要预知未来的引用字符串。
10.4.4 LRU Page Replacement
如果最佳算法是不可行的,那么一个近似于最佳算法的算法也许是可能的。FIFO 和 OPT 算法(除了一个是回顾过去一个是展望未来)的关键区别在于:FIFO 算法使用的是页面被调入内存的时间,而 OPT 算法使用的是页面将被使用的时间。如果我们使用最近的过去来近似地代替不久的将来,那么我们就可以替换掉在最长时间内未被使用的那个页面。这种方法就是最近最少使用 (LRU) 算法 (least recently used (LRU) algorithm)。
LRU 置换算法为每个页面关联一个该页面最后一次使用的时间。当必须替换一个页面时,LRU 会选择在最长时间内未被使用的那个页面。我们可以将这个策略看作是“向后看”(回顾过去)的最佳页面置换算法,而不是“向前看”(预知未来)。
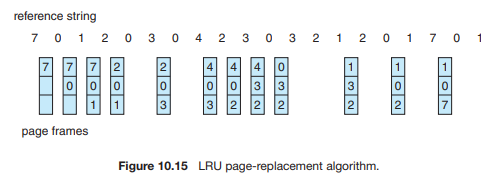
一个 LRU 页面置换算法可能需要大量的硬件辅助。难题在于要为页框确定一个由“最后使用时间”所定义的顺序。有两种可行的实现方式:
计数器 (Counters)
每当一个页面被引用时,时钟寄存器的内容就会被复制到该页面的页表项中的“使用时间”字段。这样,我们就可以把这个策略看作是记录了每个页面最后一次引用的(时钟)时间。我们替换具有最小时间值的页面。
栈 (Stack)
另一种实现 LRU 置换的方法是维护一个页号栈。每当一个页面被引用时,它就从栈中被移除,并被放到栈顶。通过这种方式,最近最多使用的页面总是在栈顶,而最近最少使用的页面总是在栈底
与最佳置换一样,LRU 置换也不会遭受 Belady 异常
10.4.5 LRU-Approximation Page Replacement
没有多少计算机系统为真正的 LRU 页面置换提供足够的硬件支持。事实上,一些系统根本不提供硬件支持,此时必须使用其他的页面置换算法; 许多近似 LRU 置换算法的基础是引用位
10.4.5.1 Additional-Reference-Bits Algorithm
我们可以通过定期记录引用位来获取额外的顺序信息。我们可以在内存中的一个表里,为每个页面保留一个 8 位的字节。操作系统会定期(例如,每 100 毫秒)通过一个定时器中断来获取控制权。操作系统将每个页面的引用位移入其 8 位字节的高位 (high-order bit),并将其他位右移 1 位,丢弃最低位 (low-order bit)。
例如,如果一个移位寄存器包含 00000000,则表示该页面在最近八个周期内都未被使用过。如果一个页面在每个周期中都至少被使用一次,其移位寄存器的值将是 11111111。一个历史寄存器值为 11000100 的页面,会比一个值为 01101111 的页面被认为“最近使用过”。
当然,移位寄存器中包含的历史位数是可以变化的,(根据可用的硬件)选择这个位数是为了使更新尽可能快。在极端情况下,这个(历史)位数可以减少到零,只留下引用位本身。这个算法被称为第二次机会页面置换算法
10.4.5.2 Second-Chance Algorithm
第二次机会置换算法的基本算法是一种 FIFO 置换算法。然而,当一个页面被选中(准备替换)时,我们会检查它的引用位。如果引用位为 0,我们就替换这个页面;但如果引用位为 1,我们就给这个页面“第二次机会”,并继续选择下一个 FIFO 页面。
当一个页面获得第二次机会时,它的引用位被清零,并且它的“到达时间”被重置为当前时间。因此,一个被给予第二次机会的页面,在所有其他页面(先)被替换(或也被给予第二次机会)之前,是不会被替换的。此外,如果一个页面被足够频繁地使用,使其引用位一直保持为 1,那么它将永远不会被替换。
实现第二次机会算法(有时也称为时钟算法 (clock algorithm))的一种方法是使用循环队列。一个指针(即“时钟”上的“指针”)指向下一个要被替换的页面。当需要一个页框时,指针会向前移动,直到它找到一个引用位为 0 的页面。在它(指针)前进的过程中,它会清除(路过的)页面的引用位(图 10.17)。一旦找到了“受害者”页面(引用位为 0 的页面),该页面就被替换,新页面被插入到循环队列中的那个位置。
请注意,在最坏的情况下,当所有(页面的)引用位都为 1 时,指针会循环遍历整个队列,给每个页面一次“第二次机会”。它会在选择下一页进行替换之前,清除所有的引用位。如果所有的位(总是)为 1,第二次机会置换算法就退化为 FIFO 置换算法。
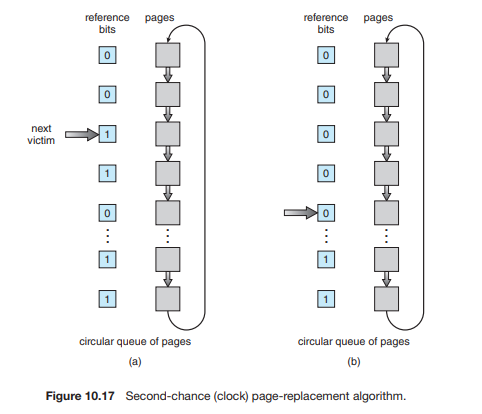
10.4.5.3 Enhanced Second-Chance Algorithm
我们可以通过将引用位 (reference bit) 和修改位 (modify bit)(在 10.4.1 节中描述)视为一个有序对,来增强第二次机会算法。利用这两个位,我们可以得到以下四种可能的类别:
(0, 0) 最近未被使用,也未被修改——最佳的替换页面。
(0, 1) 最近未被使用,但被修改过——不是那么好,因为该页面在被替换前需要被写出(到磁盘)。
(1, 0) 最近被使用过,但是干净的(未被修改)——可能很快会再次被使用。
(1, 1) 最近被使用过,且被修改过——可能很快会再次被使用,并且该页面在被替换前需要被写出到二级存储。
请注意,我们可能需要扫描循环队列数次才能找到一个要替换的页面。该算法与简单的时钟算法的主要区别在于,我们优先(替换)那些未被修改过的页面,以减少所需的 I/O 操作次数
10.4.6 Counting-Based Page Replacement
还有许多其他算法可用于页面置换。例如,我们可以为每个页面保留一个已被访问次数的计数器
最不经常使用 (LFU) 页面置换算法 (The least frequently used (LFU) page-replacement algorithm) 要求替换具有最小计数值的页面。
最常使用 (MFU) 页面置换算法 (The most frequently used (MFU) page-replacement algorithm) 基于这样一种论点:计数值最小的页面可能是刚被调入内存,尚未使用。
10.5 Allocation of Frames
10.5.2 Allocation Algorithms
这里讨论的是“分蛋糕”的方法,即如何把总共 m 个可用页框分给 n 个进程。
平均分配 (Equal Allocation) 方法: 最简单粗暴的方法,给每个进程相同数量的页框。计算:
m / n比例分配 (Proportional Allocation) 方法: 更合理的方法,根据每个进程的虚拟内存大小 (Size) 来按比例分配。进程越大,分的页框越多。(还可以根据进程的优先级来分配,而不仅仅是大小。高优先级的进程可以获得更多页框,以确保其运行流畅。)
10.5.3 Global versus Local Allocation
这里讨论的是当一个进程(比如 P1)发生缺页,需要替换一个页面时,它应该从哪里挑选“受害者”页面。
全局置换 (Global Replacement)
方法: 进程 P1 可以从系统中所有进程(包括它自己)的页框中,选择一个“受害者”来替换(例如,P1 可以抢走 P2 的一个页框)。
优点: 系统整体吞吐量更高。因为算法总能从全局选择一个最不常用的页面(例如全局 LRU),内存利用率最高。
缺点: 进程的性能变得不可预测。一个进程的运行速度不仅取决于它自己,还取决于其他进程的运行行为。
局部置换 (Local Replacement)
进程 P1 只能从它自己被分配到的页框中,选择一个来替换
优点: 性能可预测。一个进程的运行表现只和它自己的页面访问模式有关。
缺点: 系统资源利用率低。
10.6 Thrashing
操作系统中提到的最小页框数(Minimum Number of Frames)通常是指一个进程在内存中运行时,必须分配给它的一组最少的物理页框(Page Frames)数量。
考虑一下,如果一个进程没有“足够”的页框——也就是说,它没有支持其工作集 (working set) 中页面所需的最小页框数——会发生什么。该进程将很快发生缺页中断。此时, 它必须替换某个页面。然而,由于它的所有页面都在被活跃使用,它(被迫)替换的将是一个很快会再次被需要的页面。因此,它很快会再次发生缺页,然后再次(缺页),不断地替换那些它必须立即又调回来的页面。
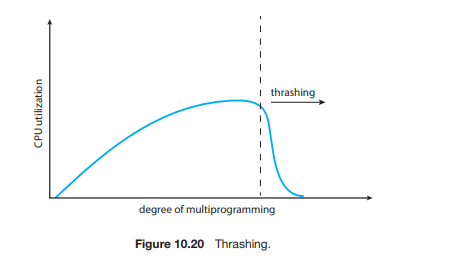
这种高频率的分页活动被称为颠簸 (thrashing)。如果一个进程花费在分页(page paging)上的时间比它执行(executing)的时间还多,那么这个进程就在“颠簸”。
10.6.1 Cause of Thrashing
考虑以下基于早期分页系统实际行为的场景。操作系统监视 CPU 利用率。如果 CPU 利用率(过)低,它(操作系统)就会通过向系统中引入一个新进程来提高多道程序设计的程度 (degree of multiprogramming)。此时使用的是全局页面置换算法 (global page-replacement algorithm),它(从所有进程中)替换页面,而不考虑页面属于哪个进程。
现在,假设一个进程在其执行过程中进入了一个新阶段,需要更多页框。它开始发生缺页,并从其他进程中拿走(替换)页框。然而,那些进程也需要它们(被拿走)的页面,所以它们也开始缺页,(同样)从其他进程中拿走页框。这些发生缺页的进程必须使用分页设备(磁盘)来进行页面的换入和换出。当它们在分页设备前排队等待时,就绪队列(ready queue)变空了。结果,CPU 利用率下降了。
CPU 调度程序看到下降的 CPU 利用率,并(错误地)增加多道程序设计的程度。.... 恶性循环
我们可以通过使用局部置换算法 (local replacement algorithm)来限制颠簸的效应。但是,这个问题并没有被完全解决。如果进程在颠簸,它们将大部分时间都花在分页设备的队列中。
为了防止颠簸,我们必须为一个进程提供它所“需要”的足够多的页框。但我们如何知道它到底“需要”多少页框呢?一种策略是定义进程执行的局部性模型 (locality model)。一个局部性 (locality) 是一组被活跃地(集中)使用在一起的页面。一个正在运行的程序通常由几个不同的局部性组成,这些局部性可能会重叠。例如,当一个函数被调用时,它就定义了一个新的局部性。
假设我们为进程分配足够的页框来容纳其当前的局部性。它将会(在该局部性的初始阶段)发生缺页中断,直到它把当前局部性的所有页面都调入内存中;此后,它将不会再发生缺页,直到它转移到一个新的局部性。如果我们没有分配足够的页框来容纳当前局部性的大小,进程将会发生颠簸,因为它无法将所有它正在活跃使用的页面都保存在内存中。
10.6.2 Working-Set Model
工作集模型 (working-set model) 是基于局部性的假设。该模型使用一个参数 Δ 来定义工作集窗口 (working-set window)。其思想是检查最近 Δ 次的页面引用。在这最近的 Δ 次引用中涉及到的页面集合就是工作集 (working set)(图 10.22)。如果一个页面正在被活跃使用,它就会在工作集中。如果它不再被使用,在它最后一次被引用后的 Δ 个时间单位后,它将从工作集中移除。因此,工作集是程序局部性的一个近似值。
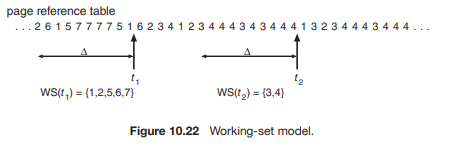
该模型的准确性取决于 Δ 的选择。如果 Δ 太小,它将无法包含整个局部性。如果 Δ太大,它可能会(同时)包含多个局部性。在极端情况下,如果 Δ 是无限的,那么工作集就是进程在执行过程中接触到的所有页面的集合。
10.6.3 Page-Fault Frequency
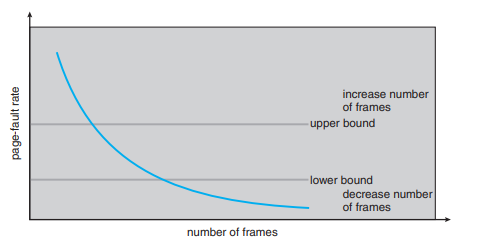
工作集模型是成功的,并且工作集的知识对于预分页(Prepaging,见 10.9.1 节)很有用,但它似乎是一种控制颠簸的笨拙方式。使用缺页率 (page-fault frequency, PFF) 的策略采用了一种更直接的方法。
具体的问题是如何防止颠簸。颠簸(的特征)是高缺页率。因此,我们想要控制缺页率。当它太高时,我们知道进程需要更多页框。相反,如果缺页率太低,那么进程可能拥有了过多的页框。我们可以在期望的缺页率上建立一个上限 (upper bound) 和 下限 (lower bound)(图 10.23)。如果实际缺页率超过了上限,我们就给进程分配另一个页框。如果缺页率降到下限以下,我们就从该进程中移除一个页框。因此,我们可以直接测量和控制缺页率来防止颠簸
10.8 Allocating Kernel Memory
用户程序申请内存时,哪怕只需要 1 个字节(放个螺丝钉),也得租下一整个 4KB 的大仓库;内核(操作系统自己)申请内存. 它的需求非常零碎。它可能需要 32 字节存一个进程信息,100 字节存一个文件锁... 如果每要 32 字节就去占一个 4KB 的大仓库,那内存很快就会被它自己浪费光了。因此,内核必须“精打细算”,它需要一种能高效管理各种小块内存的方法,不能像对待用户程序那样“粗放”。
用户程序用的内存, 在物理上可能是东一块、西一块,散落在内存条的各个角落。但我们不在乎,因为 CPU 和操作系统会帮你用“虚拟地址”把它们串起来;内核还要负责管理硬件,比如你的网卡、硬盘,它们不认识“虚拟地址”; 内核必须有能力分配到物理地址连续的内存块。而那个给用户程序的“空闲仓库列表”里都是分散的页框,无法保证这一点
在以下部分中,我们探讨了两种用于管理分配给内核进程的空闲内存的策略:“伙伴系统” (buddy system) 和“平板分配” (slab allocation)。
10.8.1 Buddy System
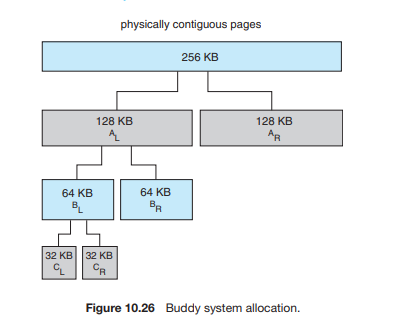
伙伴系统从一个固定大小的、物理上连续的页面段 (segment) 中分配内存。该系统使用2 的幂次方分配器 (power-of-2 allocator),以 2 的幂次方为单位(例如 4 KB, 8 KB, 16 KB, 等等)来满足(内存)请求。一个(任意大小的)请求会被向上取整 (rounded up) 到下一个最接近的 2 的幂次方。例如,一个 11 KB 的请求将由一个 16 KB 的段来满足。
伙伴系统的一个额外好处是,相邻的伙伴块可以组合起来形成更大的段,这个技术被称为合并 (coalescing)。
伙伴系统最明显的缺点是,向上取整到下一个 2 的幂次方可能会导致明显的碎片。例如,一个 33 KB 的请求只能由一个 64 KB 的段来满足。事实上,我们不能保证分配的单元中少于 50% 的空间会被浪费掉(译注:指内部碎片)
10.8.2 Slab Allocation
分配内核内存的第二种策略被称为平板分配 (slab allocation)。一个平板 (slab) 由一个或多个物理上连续的页面组成。一个缓存 (cache) 由一个或多个平板组成。每种唯一的内核数据结构都有一个单独的缓存——例如,一个用于表示进程描述符的数据结构的缓存,一个用于文件对象的缓存,一个用于信号量的缓存,等等。每个缓存中都填充有对象 (objects),这些对象是该缓存所代表的内核数据结构的实例。例如,代表信号量的缓存存储着信号量对象的实例,代表进程描述符的缓存存储着进程描述符对象的实例,依此类推。平板、缓存和对象之间的关系如图 10.27 所示。该图显示了两个 3 KB 大小的内核对象和三个 7 KB 大小的对象,每种都存储在一个单独的缓存中
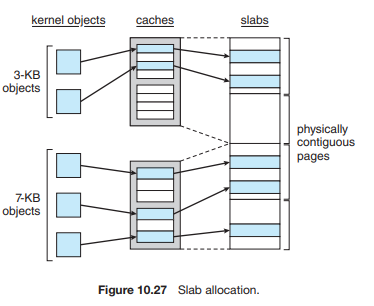
(如果 3kb 和 7kb的 分配需求都给 8kb的话, 未免有些浪费了,因此, 专门给 3kb的分配 4kb的块,这些块在caches中,caches中有些还未被分配; 同样的,专门给7kb的块分配8kb的内存;)
缓存中对象的数量取决于关联平板的大小。例如,一个 12-KB 的平板(由三个连续的 4-KB 页面组成)可以存储六个 2-KB 的对象
最初,缓存中的所有对象都被标记为空闲。当需要一个内核数据结构的新对象时,分配器 (allocator) 可以从缓存中分配任何空闲的对象来满足该请求。从缓存中分配的对象被标记为已使用。
在 Linux 中,一个平板可能有以下三种状态之一:
满 (Full)。 平板中的所有对象都标记为已使用。
空 (Empty)。 平板中的所有对象都标记为空闲。
部分 (Partial)。 平板中既有已使用的对象,也有空闲的对象。
平板分配器 (slab allocator) 首先尝试用部分 (partial) 平板中的一个空闲对象来满足请求。如果(部分平板)不存在,就从一个空 (empty) 平板中分配一个空闲对象。如果没有空的平板可用,就会从(物理)连续的物理页面中分配一个新的平板,并将其指派给一个缓存;(然后)对象所需的内存会从这个(新)平板中分配。
平板分配器提供了两个主要好处:
不会因碎片而浪费内存。 碎片不成问题,因为每种唯一的内核数据结构都有一个关联的缓存,而每个缓存都由一个或多个平板组成,这些平板被精确地划分成块(chunks),(块的)大小就是被表示的对象的大小。因此,当内核为某个对象请求内存时,平板分配器返回的内存大小正好可以容纳该对象。
可以快速满足内存请求。 因此,平板分配方案对于管理那些被频繁分配和释放的对象(这在内核请求中很常见)尤其有效。分配和释放内存的行为本身可能是一个耗时的过程。然而(在平板分配中),对象可以被预先创建,因此可以从缓存中快速分配。此外,当内核使用完一个对象并释放它时,该对象会被标记为空闲并返回到其缓存中,从而使其可用于内核随后的(下一次)请求。
10.9 Other Considerations
10.9.1 Prepaging
纯请求调页(pure demand paging)的一个明显特性是,当一个进程启动时会发生大量的缺页错误(page faults)。这种情况是由于试图将初始的局部性(locality)数据读入内存而导致的。预调页(Prepaging)就是为了防止这种高频率的初始调页而做出的尝试。其策略是一次性将所需的全部——或部分——页面调入内存。
例如,在使用工作集(working-set)模型的系统中,我们可以为每个进程保留一份其工作集内的页面列表。如果我们必须挂起一个进程(由于缺乏空闲帧),我们会记住该进程的工作集。当进程要恢复时(因为 I/O 完成或有足够的空闲帧可用),我们在重启进程之前,自动将其整个工作集调回内存。
在某些情况下,预调页可能会提供优势。问题仅仅在于,使用预调页的成本是否小于处理相应缺页错误的成本。很有可能的情况是,通过预调页调回内存的许多页面根本不会被使用。
假设有 s 页是预分页的,并且其中一部分 α 的页面实际上被使用(0 ≤ α ≤ 1)。问题在于,s*α 个节省的页面错误的成本是否大于或小于预分页 s*(1−α) 个不必要页面的成本。如果 的 α 接近 0,预分页会吃亏;如果 α 接近 1,预分页会占优势。
10.9.2 Page Size
我们如何选择页面大小?一个考量因素是页表(page table)的大小。对于给定的虚拟内存空间,减小页面大小会增加页面的数量,从而增加页表的大小。因为每个活动进程都必须有自己的页表副本,所以较大的页面大小是比较理想的。
然而,较小的页面能更好地利用内存 假设进程大小与页面大小无关,我们可以预期,平均而言,每个进程的最后一页有一半会被浪费。对于 512 字节的页面,这种损失仅为 256 字节;但对于 8,192 字节的页面,损失则高达 4,096 字节。因此,为了最大限度地减少内部碎片,我们需要较小的页面大小。
另一个问题是读取或写入一个页面所需的时间。寻道时间和旋转延迟通常远大于传输时间。因此,为了最大限度地减少 I/O 时间,我们需要较大的页面大小。
不过,使用较小的页面大小,总 I/O 量应该会减少,因为局部性(locality)会得到改善。
但是你有没有注意到,如果页面大小为 1 字节,我们将为每个字节产生一次缺页错误(page fault)?一个 200 KB 的进程,如果只使用其中一半的内存,在页面大小为 200 KB 时只会产生 1 次缺页错误,但在页面大小为 1 字节时会产生 102,400 次缺页错误。每次缺页错误都会产生大量的开销,用于处理中断、保存寄存器、置换页面、排队等待分页设备以及更新表项。为了最大限度地减少缺页错误的数量,我们需要较大的页面大小。
10.9.3 TLB Reach
与命中率相关的一个类似指标是 TLB 覆盖范围(TLB reach)。TLB 覆盖范围是指可以通过 TLB 访问的内存总量,它简单地等于 TLB 条目数乘以页面大小。理想情况下,一个进程的工作集(working set)应该存储在 TLB 中。
增加 TLB 覆盖范围的另一种方法是增加页面大小,或者提供多种页面大小。如果我们增加页面大小——比如说,从 4 KB 增加到 16 KB——我们就将 TLB 覆盖范围增加了四倍。然而,对于某些不需要如此大页面大小的应用程序来说,这可能会导致碎片化(fragmentation)的增加。另外,大多数架构都支持不止一种页面大小,操作系统可以被配置为利用这种支持。例如,Linux 系统上的默认页面大小是 4 KB;然而,Linux 也提供大页(huge pages),该功能指定了一块物理内存区域,在那里可以使用更大的页面(例如 2 MB)。
10.9.5 Program Structure
请求调页被设计为对用户程序透明。在许多情况下,用户完全不知道内存的分页性质。然而,在其他情况下,如果用户(或编译器)了解底层的请求调页机制,系统性能可以得到提高。
int i, j;
int[128][128] data;
for (j = 0; j < 128; j++)
for (i = 0; i < 128; i++)
data[i][j] = 0;注意数组是按行主序(row major)存储的.对于 128 个字的页面,每一行占用一页。因此,前面的代码先将每一页中的一个字清零,然后将每一页中的另一个字清零,依此类推。如果操作系统为整个程序分配的帧少于 128 个,那么它的执行将导致 128 * 128 = 16,384 次缺页错误。
int i, j;
int[128][128] data;
for (i = 0; i < 128; i++)
for (j = 0; j < 128; j++)
data[i][j] = 0;这段代码在开始下一页之前将一页上的所有字清零,将缺页错误的数量减少到 128 次。
Chapter 6 Synchronization Tools
6.1 Background
现在我们回到对有界缓冲区(bounded buffer)的讨论。正如我们之前指出的,我们最初的方案同一时间最多允许缓冲区中存放 BUFFER_SIZE - 1 个项。假设我们想要修改算法来弥补这一缺陷。一种可能性是添加一个整数变量 count,初始化为 0。每当我们向缓冲区添加一个新项时,count 递增;每当我们从缓冲区移除一个项时,count 递减。
但当它们并发执行(executed concurrently)时,功能可能不正确。作为说明,假设变量 count 的当前值为 5,并且生产者和消费者进程并发执行语句 "count++" 和 "count--"。在这两个语句执行之后,变量 count 的值可能是 4、5 或 6!然而,唯一正确的结果是 count == 5
我们之所以会得到这个不正确的状态,是因为我们允许两个进程并发地操纵变量 count。像这种情况,即多个进程并发地访问和操纵同一数据,且执行结果取决于访问发生的特定顺序,被称为竞态条件(race condition)。为了防止上述竞态条件,我们需要确保同一时间只有一个进程可以操纵变量 count。为了做出这样的保证,我们需要进程以某种方式进行同步(synchronized)。
6.2 The Critical-Section Problem
我们通过讨论所谓的临界区问题(critical-section problem)来开始对进程同步的思考。考虑一个由 n 个进程 {P0, P1, ..., Pn-1} 组成的系统。每个进程都有一段代码,称为临界区(critical section),在该区中进程可能正在访问——并更新——至少与一个其他进程共享的数据。系统的重要特征是,当一个进程在其临界区内执行时,没有其他进程被允许在其临界区内执行。也就是说,没有两个进程同时在它们的临界区内执行。临界区问题就是设计一种协议,进程可以使用该协议来同步它们的活动,从而协作地共享数据。每个进程必须请求许可才能进入其临界区。实现这一请求的代码部分是进入区(entry section)。临界区之后可能紧跟着一个退出区(exit section)。剩余的代码是剩余区(remainder section)。
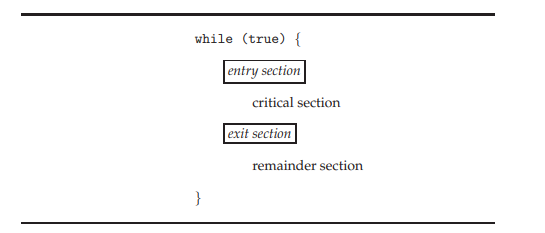
临界区问题的解决方案必须满足以下三个要求:
互斥(Mutual exclusion)。如果进程 Pi 正在其临界区内执行,那么其他进程都不能在它们的临界区内执行。
前进(Progress)。如果没有进程在临界区内执行,并且有一些进程希望进入它们的临界区,那么只有那些不在其剩余区执行的进程可以参与决定哪一个将下一个进入其临界区,并且这种选择不能被无限期推迟
·有限等待(Bounded waiting)。在以一个进程发出进入其临界区的请求开始,到该请求被批准为止的时间段内,其他进程被允许进入其临界区的次数必须存在一个界限或限制。
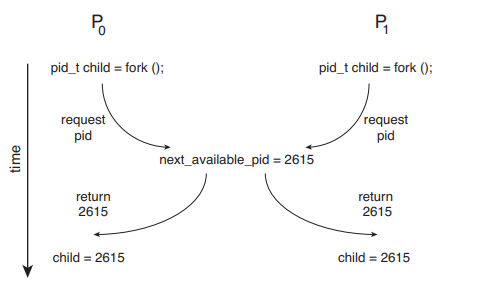
在这种情况下,两个进程 P0 和 P1 正在使用 fork() 系统调用创建子进程。回顾第 3.3.1 节,fork() 将新创建进程的进程标识符(PID)返回给父进程。在这个例子中,变量 next_available_pid 存在竞态条件,该变量表示下一个可用进程标识符的值。除非提供互斥,否则相同的进程标识符编号可能会被分配给两个独立的进程。
如果在修改共享变量时我们可以防止中断发生,那么在单核环境下,临界区问题就可以简单地解决。通过这种方式,我们可以确信当前的指令序列将被允许按顺序执行而不会被抢占(preemption)。没有其他指令会运行,因此不会对共享变量进行意外的修改。
不幸的是,这种解决方案在多处理器环境中并不可行。在多处理器上禁用中断可能很耗时,因为消息需要传递给所有处理器。这种消息传递会延迟进入每个临界区,从而降低系统效率。此外,如果系统时钟通过中断进行更新,还要考虑这对系统时钟的影响。
在操作系统中处理临界区通常使用两种通用方法:抢占式内核(preemptive kernels)和非抢占式内核(nonpreemptive kernels)。
抢占式内核允许进程在内核模式下运行时被抢占。
非抢占式内核不允许在内核模式下运行的进程被抢占;内核模式的进程会一直运行,直到它退出内核模式、阻塞或自愿让出 CPU 的控制权。
显然,非抢占式内核本质上在内核数据结构上没有竞态条件,因为同一时间只有一个进程在内核中处于活动状态。我们就不能对抢占式内核这么说了,因此必须仔细设计它们以确保共享的内核数据不受竞态条件的影响。抢占式内核在 SMP(对称多处理)架构的设计上通过特别困难,因为在这些环境中,两个内核模式的进程可能在不同的 CPU 核心上同时运行。
那么,为什么还有人会倾向于选择抢占式内核而不是非抢占式内核呢? 抢占式内核可能响应更灵敏(more responsive),因为内核模式进程在将处理器让给等待进程之前,运行任意长的时间的风险较小。(当然,这种风险也可以通过设计不产生这种行为的内核代码来最小化。)此外,抢占式内核更适合实时编程(real-time programming),因为它允许实时进程抢占当前在内核中运行的进程。
6.3 Peterson’s Solution
由于现代计算机架构执行基本机器语言指令(如 load 和 store)的方式,无法保证 Peterson 算法在这些架构上能正确运行。然而,我们要介绍这个方案,因为它提供了一个很好的算法描述来解决临界区问题,并阐明了设计满足互斥、前进(Progress)和有限等待要求的软件时所涉及的一些复杂性。
Peterson 算法仅限于两个在临界区和剩余区之间交替执行的进程。进程编号为 P0 和 P1 , 为了方便起见,记为 Pi 和 Pj, j = 1 - i
两个进程共享两个数据项
int turn;
boolean flag[2];Peterson 算法中进程 Pi 的结构
while (true) {
flag[i] = true;
turn = j;
while (flag[j] && turn == j)
;
/* critical section (临界区) */
flag[i] = false;
/* remainder section (剩余区) */
}我们现在证明这个方案是正确的。我们需要证明 互斥性 (Mutual exclusion), 前进性 (Progress) 和 有限等待 (Bounded-waiting)
flag表示某个进程有没有准备好,如果只有i个进程准备好了,那么对应j的flag就是false,因此i可以很轻松的进入临界区;但如果两个flag都准备好了,那么就要看谁先执行 turn = j;先执行的进程会先进入 while 的循环中,等待另一方执行 turn = i, 另一方执行之后,自己就可以进入临界区;而在临界区中由于 turn 为 i没有进程会改变,另一方一直没发进入,卡在while循环中,直到我方退出临界区执行flag[i] = false;
Peterson 算法不能保证在现代计算机架构上工作,主要原因是:为了提高系统性能,处理器和/或编译器可能会对没有依赖关系的读写操作进行重排序 (Reorder)。
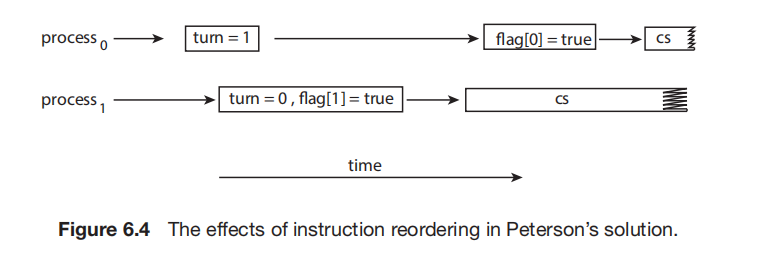
由于变量之间没有数据依赖,处理器可能对指令进行重排序,这会导致两者都进入 critical section
保持互斥性的唯一方法是使用适当的同步工具
6.4 Hardware Support for Synchronization
基于软件的解决方案并不能保证在现代计算机架构上正常工作。在本节中,我们将介绍三种提供临界区问题解决支持的硬件指令。
6.4.1 Memory Barriers
内存模型属于以下两类之一:
强序 (Strongly ordered):一个处理器上的内存修改会立即对所有其他处理器可见
弱序 (Weakly ordered):一个处理器上的内存修改可能不会立即对其他处理器可见。
6.4.2 Hardware Instructions
许多现代计算机系统提供特殊的硬件指令,允许我们要么原子地 (atomically) —— 即作为一个不可中断的单元 —— 测试并修改一个字的内容,要么原子地交换两个字的内容。我们可以使用这些特殊指令以相对简单的方式解决临界区问题。我们不讨论特定机器的一条具体指令,而是通过描述 test_and_set() 和 compare_and_swap() 指令来抽象这些类型指令背后的主要概念。
boolean test_and_set(boolean *target) {
boolean rv = *target;
*target = true;
return rv;
}代码逻辑是:读取目标当前值,将目标设为 true,返回旧值。整个过程是原子的。这条指令的重要特征是它是原子地执行的。因此,如果两个 test_and_set() 指令同时执行(每个在不同的核心上),它们将以某种任意顺序依次执行。
do {
while (test_and_set(&lock))
; /* do nothing */
/* critical section (临界区) */
lock = false;
/* remainder section (剩余区) */
} while (true);使用 test_and_set() 实现互斥
int compare_and_swap(int *value, int expected, int new_value) {
int temp = *value;
if (*value == expected)
*value = new_value;
return temp;
}代码逻辑是:读取当前值,如果当前值等于期望值,则更新为新值;无论是否更新,都返回旧值。整个过程是原子的。
test_and_set() 指令可以如上 所示进行定义。这条指令的重要特征是它是原子地执行的。因此,如果两个 test_and_set() 指令同时执行(每个在不同的核心上),它们将以某种任意顺序依次执行。如果机器支持 test_and_set() 指令,我们可以通过声明一个布尔变量 lock(初始化为 false)来实现互斥。进程 Pi 的结构如下 所示
do {
while (compare_and_swap(&lock, 0, 1) != 0)
; /* do nothing */
/* critical section (临界区) */
lock = 0;
/* remainder section (剩余区) */
} while (true);使用 compare_and_swap() 指令实现互斥
虽然这个算法满足了互斥 (mutual-exclusion) 要求,但它并不满足有限等待 (bounded-waiting)。因为当当前的锁持有者将 lock 重置为 0(释放锁)的瞬间,所有正在等待的进程(以及任何刚刚到达的新进程)都会同时去竞争这个锁。谁能抢到锁完全取决于硬件层面的运气,进程进入临界区的次数没有一个上限
do {
waiting[i] = true;
key = 1;
while (waiting[i] && key == 1)
key = compare_and_swap(&lock, 0, 1);
waiting[i] = false;
/* critical section (临界区) */
j = (i + 1) % n;
while ((j != i) && !waiting[j])
j = (j + 1) % n;
if (j == i)
lock = 0;
else
waiting[j] = false;
/* remainder section (剩余区) */
} while (true);而以上此算法保证了每个等待的进程最多只需要等待n-1 次
6.5 Mutex Locks
在 6.4 节中介绍的临界区问题的硬件解决方案既复杂,又通常无法被应用程序员直接使用。相反,操作系统设计者构建了更高级的软件工具来解决临界区问题。这些工具中最简单的就是 互斥锁 (mutex lock)。
互斥锁包含一个布尔变量 available,其值指示锁是否可用。如果锁可用,调用 acquire() 将会成功,随后锁会被视为不可用。一个试图获取不可用锁的进程将被阻塞,直到该锁被释放。
while (true) {
acquire lock // 获取锁
critical section // 临界区
release lock // 释放锁
remainder section // 剩余区
}使用互斥锁解决临界区问题
acquire() {
while (!available)
; /* busy wait (忙等待) */
available = false;
}acquire() 的定义
release() {
available = true;
}release() 的定义